
ホームページ >バックエンド開発 >Python チュートリアル >Python 中国語コーディングの問題の概要
Python 中国語コーディングの問題の概要

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2016-06-16 08:41:321147ブラウズ
中国語のエンコーディングの問題は、Python プログラミングにおいて常に頭の痛い問題です。この記事では、これについて詳しくまとめています。詳細は以下のとおりです。
文字列が「u4e2du56fd」の場合
>>>s=['\u4e2d\u56fd','\u6e05\u534e\u5927\u5b66']
>>>str=s[0].decode('unicode_escape') #.encode("EUC_KR")
>>>print str
中国
文字列が「東アジア学院第一中学校」の場合
>>>print unichr(19996) 东
ord() は Unicode をサポートしており、次のような特定の文字の Unicode 番号を表示できます。
>>>print ord('A')
65
Unicode に接続されている限り、Unicode 文字列が生成されます。例:
>>> 'help' 'help' >>> 'help,' + u'python' u'help,python'ASCII (7 ビット) 互換文字列の場合、組み込みの str() 関数を使用して Unicode 文字列を ASCII 文字列に変換できます。例:
>>> str(u'hello world') 'hello world'いくつかの概念の理解:
ASCII コードでは、以下の図に示すように、データ ワードを使用して対応する文字に対応します。
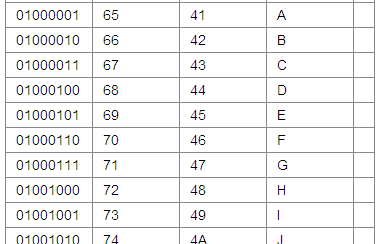
Unicode エンコードは国ごとに 1 つに分割されています。 UTF-8、UTF-16、UTF-32、その他の形式があります
中国語の範囲 4E00-9FBF: この範囲には gbk、gb2312、
があります
UTF-8 は Unicode に基づいており、国際的な状況での使用に適しています
この記事が皆さんの Python プログラミングに役立つことを願っています。
声明:
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。