


PHPでページごとに3つのXMLデータを読み取るにはどうすればよいですか?
次のコードは、「9.xml」のすべての shortdesc フィールドを読み出すことができます:
--------------------------- -- ---------------
$xml_array=simplexml_load_file('9.xml'); //XML のデータを配列オブジェクトに読み込みますin
foreach($xml_array as $tmp){
echo $tmp->shortdesc."
";
}
?>
---------------------------------------
理由データ量が非常に多いので、「次へ」ボタンをクリックすると、すべてのデータが表示されるまで次の 3 つのデータが表示されるようにしたいのです。再度「次へ」ボタンをクリックしてもページは変わりません。これを達成する方法を教えてください。コードもあったほうが良いです、ありがとうございます。
-----解決策---------
これは最初に出力したものです:
foreach($xml_array as $tmp){
echo $tmp->shortdesc."
";
}
次のようにする必要があります。次のように出力します Line
$page = ($_GET['page'] - 1) * 3;
for($i=$page; $i echo $xml [$i]->shortdesc."
";
}
------解決策----------------------
ボスのコードは十分に明確です
//配列を取得します
$xml_array=simplexml_load_file('9.xml');
// どの項目から開始します。ページングを要求しませんでしたか? ページングにはデータの開始位置とオフセットが必要です。
// すると、このデータの開始位置は $page になります。 ページ 2 が必要な場合は、パラメータ $_GET['page'] === 2
// (2-1)*3 (3) を渡します。これは配列のキー値でデータを取得するもので、配列のキー値は0から始まります。 0,1,2 は最初のページ、3,4,5 は 2 番目のページです
$page = ($_GET['page'] - 1) * 3;
// 3 回ループして計算します毎回 $i の値を見てください。それぞれ 3、4、5 です。次に、上記のキー値 3、4、5 を持つデータです
for($i=$page; $iecho $xml[$i] - >shortdesc."
";
}
// 次のページのリンクに渡されるパラメータは $_GET['page'] + 1 です
------解決策------------------
それはあなたのせいです。最初から正しい情報を提供しなかったのです
あなたの
foreach($xml_array as $tmp){
echo $tmp->shortdesc."
";
}
ドキュメントの内容を出力できません
これは、
foreach($xml_array->news->new as $tmp){
echo $tmp->gt; の方法です。 ."
";
}
$xml_array->news->new は配列であるため、
$xml = $xml_array->news-> ;
$page = min(3, count($xml)-3);
for($i=$page; $i echo $xml [ $i]->shortdesc."
";
}
が確立されました

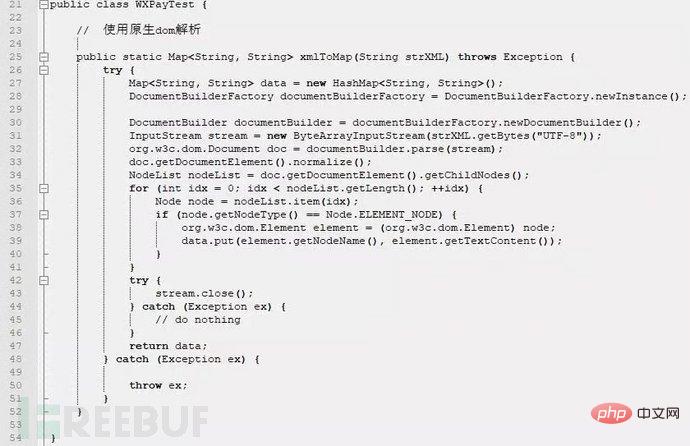 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM
如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM如何用PHP和XML实现网站的分页和导航导言:在开发一个网站时,分页和导航功能是很常见的需求。本文将介绍如何使用PHP和XML来实现网站的分页和导航功能。我们会先讨论分页的实现,然后再介绍导航的实现。一、分页的实现准备工作在开始实现分页之前,需要准备一个XML文件,用来存储网站的内容。XML文件的结构如下:<articles><art
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
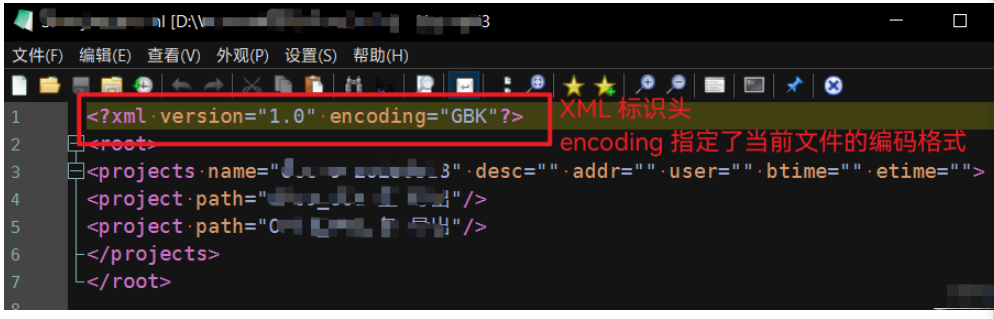 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

Dreamweaver Mac版
ビジュアル Web 開発ツール

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン
ホットトピック
 7441
7441 15137152
15137152