
ホームページ >バックエンド開発 >PHPチュートリアル >PHP 2 ベースの cURL によるクイック スタート
PHP 2 ベースの cURL によるクイック スタート

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2016-06-13 13:03:28804ブラウズ
PHP 2 ベースの cURL によるクイックスタート
?
POST メソッドを使用してデータを送信する
GET リクエストを開始するとき、「クエリ文字列」を通じてデータを URL に渡すことができます。たとえば、Google で検索する場合、検索キーは URL のクエリ文字列の一部です:
http://www.google.com/search?q=nettuts
次に、おそらく cURL をシミュレートする必要はありません。この URL を「file_get_contents()」にスローすると、同じ結果が得られます。
ただし、一部の HTML フォームは POST メソッドを使用して送信されます。このフォームが送信されると、データはクエリ文字列ではなく HTTP リクエスト本文を通じて送信されます。たとえば、CodeIgniter フォーラム フォームを使用する場合、どのようなキーワードを入力しても、常に次のページに POST されます:
http://codeigniter.com/forums/do_search/
PHP スクリプトを使用して、この URL リクエストをシミュレートできます。まず、POST データを受け入れて表示できる新しいファイルを作成します。post_output.php という名前を付けます。
print_r($_POST);?
次に、cURL リクエストを実行する PHP スクリプトを作成します:
以下は引用された内容です:
$url = "http://localhost/post_output.php"; $post_data = array ( "foo" => "bar", "query" => "Nettuts", "action" => "Submit" ); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // 我们在POST数据哦! curl_setopt($ch, CURLOPT_POST, 1); // 把post的变量加上 curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $output = curl_exec($ch); curl_close($ch); echo $output;?
コードを実行すると、次の結果が得られます:

このスクリプトは、このページの post_output.php に POST リクエストを送信します。 $_POST 変数とリターン、cURL を使用してこの出力をキャプチャしました。
ファイルのアップロード
ファイルのアップロードは、前の POST と非常によく似ています。すべてのファイル アップロード フォームは POST メソッドを通じて送信されるためです。
最初に、upload_output.php という名前でファイルを受信するための新しいページを作成します:
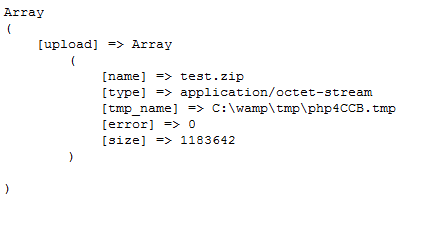
print_r($_FILES);
以下は、実際にファイル アップロード タスクを実行するスクリプトです。 :
以下は引用内容です:
$url = "http://localhost/upload_output.php"; $post_data = array ( "foo" => "bar", // 要上传的本地文件地址 "upload" => "@C:/wamp/www/test.zip" ); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $output = curl_exec($ch); curl_close($ch); echo $output;?
ファイルをアップロードする必要がある場合は、post 変数のようにファイル パスを渡すだけですが、先頭に @ 記号を追加することを忘れないでください。このスクリプトを実行すると、次の出力が得られます。
cURL バッチ処理 (マルチ cURL)
cURL には、バッチ ハンドル (ハンドル) という高度な機能もあります。この機能を使用すると、複数の URL 接続を同時にまたは非同期で開くことができます。
以下は php.net のサンプルコードです:
以下は引用された内容です:
// 创建两个cURL资源
$ch1 = curl_init();
$ch2 = curl_init();
// 指定URL和适当的参数
curl_setopt($ch1, CURLOPT_URL, "http://lxr.php.net/");
curl_setopt($ch1, CURLOPT_HEADER, 0);
curl_setopt($ch2, CURLOPT_URL, "http://www.php.net/");
curl_setopt($ch2, CURLOPT_HEADER, 0);
// 创建cURL批处理句柄
$mh = curl_multi_init();
// 加上前面两个资源句柄
curl_multi_add_handle($mh,$ch1);
curl_multi_add_handle($mh,$ch2);
// 预定义一个状态变量
$active = null;
// 执行批处理
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
while ($active && $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
// 关闭各个句柄
curl_multi_remove_handle($mh, $ch1);
curl_multi_remove_handle($mh, $ch2);
curl_multi_close($mh);
?
ここで必要なのは、複数の cURL ハンドルを開いてバッチ ハンドラーに割り当てることだけです。次に、while ループで完了するまで待つだけです。
この例には 2 つの主要なループがあります。最初の do-while ループは、curl_multi_exec() を繰り返し呼び出します。この関数はノンブロッキングですが、実行される回数は最小限に抑えられます。ステータス値を返します。この値が定数 CURLM_CALL_MULTI_PERFORM と等しい限り、実行すべき緊急の作業がまだあることを意味します (たとえば、URL に対応する http ヘッダー情報の送信)。つまり、戻り値が変わるまでこの関数を呼び出し続ける必要があります。
次の while ループは、$active 変数が true の場合にのみ続行されます。この変数は以前、curl_multi_exec() の 2 番目のパラメーターとして渡され、バッチ ハンドラーにまだアクティブな接続が存在するかどうかを表します。次に、curl_multi_select() を呼び出します。これは、アクティブな接続が発生する (サーバー応答の受信など) まで「ブロック」されます。この関数が正常に実行された後、別の do-while ループに入り、次の URL に進みます。
この機能を実際に使用する方法を見てみましょう:
WordPress 接続チェッカー
膨大な数の記事があるブログがあると想像してください。多数の外部 Web サイトへのリンク。しばらくすると、何らかの理由で、これらのリンクのかなりの数が無効になりました。調和されているか、サイト全体がハッキングされているかのどちらかです...
これらすべてのリンクを分析し、開けない Web サイトや Web ページ、または 404 を検出して、報告。
以下は実際に利用可能な WordPress プラグインではなく、デモンストレーションのみを目的とした、独立した機能を備えた単なるスクリプトであることに注意してください。ありがとうございます。
さて、始めましょう。まず、データベースからこれらのリンクをすべて読み取ります:
引用された内容は次のとおりです:
// CONFIG
$db_host = 'localhost';
$db_user = 'root';
$db_pass = '';
$db_name = 'wordpress';
$excluded_domains = array(
'localhost', 'www.mydomain.com');
$max_connections = 10;
// 初始化一些变量
$url_list = array();
$working_urls = array();
$dead_urls = array();
$not_found_urls = array();
$active = null;
// 连到 MySQL
if (!mysql_connect($db_host, $db_user, $db_pass)) {
die('Could not connect: ' . mysql_error());
}
if (!mysql_select_db($db_name)) {
die('Could not select db: ' . mysql_error());
}
// 找出所有含有链接的文章
$q = "SELECT post_content FROM wp_posts
WHERE post_content LIKE '%href=%'
AND post_status = 'publish'
AND post_type = 'post'";
$r = mysql_query($q) or die(mysql_error());
while ($d = mysql_fetch_assoc($r)) {
// 用正则匹配链接
if (preg_match_all("!href=\"(.*?)\"!", $d['post_content'], $matches)) {
foreach ($matches[1] as $url) {
// exclude some domains
$tmp = parse_url($url);
if (in_array($tmp['host'], $excluded_domains)) {
continue;
}
// store the url
$url_list []= $url;
}
}
}
// 移除重复链接
$url_list = array_values(array_unique($url_list));
if (!$url_list) {
die('No URL to check');
}
?
まず、データベース、除外する一連のドメイン名 ($excluded_domains)、および同時接続の最大数 ($max_connections) を構成します。次に、データベースに接続し、記事と含まれるリンクを取得し、それらを配列 ($url_list) に収集します。