


実装内容:HTMLコードを含むテキストを切り詰めますが、包含タグが閉じていなくても問題ありません。
注: これはサーバー側で使用するための PHP バージョンです。クライアント バージョンが必要な場合は、次の記事をお読みください。
BLOG などのプログラムを作成する場合、多くの場合、前の部分を表示する必要があります。しかし、不適切な切り詰めにより終了タグが破壊され、ドキュメント構造全体に損傷が生じるのではないかと心配しています。この関数を使用すると、高い要件を必要とせずにこの問題を解決できます。
この機能をサーバー側に適用するかクライアント側に適用するかを誰もが考慮する必要があります。この機能は実行するとマシンへの負荷が高くなる可能性があると考えられるため、セキュリティ要件が高くない場合はクライアントに配置できます。
対応するデータベース クエリも最適化されるように、この概要をデータ テーブルの別のフィールドに配置するのが最善です。多くの時間を費やす代わりに少しのスペースを犠牲にするのは、それでも十分に得策です。
セキュリティの問題、主にコンテンツのセキュリティについてもう一度話しましょう。クライアントが通常の要約情報を変更しようとする場合、通常、BLOG の所有者がその権限を有しており、要約と原文との間の一貫性を破壊するのは彼自身の仕事です。コンテンツ以外のセキュリティはサーバー側で解決できます。したがって、この機能はクライアント側で使用することをお勧めします。
コアコード
コピーコード コードは次のとおりです:
// PHP 4.3 以降が必要
define("BRIEF_LENGTH", 800); //記事のブリーフィングの単語量
function Generate_Brief($text){
global $Briefing_Length;
if(strlen($text) $Foremost = substr($text, 0, BRIEF_LENGTH);
$re = "/]*(>?)/i";
$Single = "/BASE|META|LINK|HR|BR|PARAM|IMG|AREA|INPUT/i";
$Stack = array(); $posStack = array();
preg_match_all($re,$Foremost,$matches, PREG_SET_ORDER | PREG_OFFSET_CAPTURE);
/* [子マッチング仕様]:
$matches[$i][1] : 現在の "<...>" かどうかを示す "/" 文字 摩擦は終了部分
$matches[$i][2] : 要素名です。
$matches[$i][3] : 右 > 「<...>」の 摩擦 */
for($i = 0 ; $i if($matches[$i][1][0] == ""){
$Elem = $matches[$i][2][0];
if(preg_match($Single,$Elem) && $matches[$i][3][0] !=""){
続き;
}
array_push($Stack, strtoupper($matches[$i][2][0]));
array_push($posStack, $matches[$i][2][1]);
if($matches[$i][3][0] =="") break;
}else{
$StackTop = $Stack[count($Stack)-1];
$End = strtoupper($matches[$i][2][0]);
if(strcasecmp($StackTop,$End)==0){
array_pop($Stack);
array_pop($posStack);
if($matches[$i][3][0] ==""){
$Foremost = $Foremost.">";
}
}
}
}
$cutpos = array_shift($posStack) - 1;
$Foremost = substr($Foremost,0,$cutpos);
$Foremost を返します。
};
复制代码 代码如下:
関数 Generate_Brief($text){
global $Briefing_Length;
mb_regex_encoding("UTF-8");
if(mb_strlen($text) $Foremost = mb_substr($text, 0, BRIEF_LENGTH);
$re = "]*(>?)";
$Single = "/BASE|META|LINK|HR|BR|PARAM|IMG|AREA|INPUT|BR/i";
$Stack = array(); $posStack = array();
mb_ereg_search_init($Foremost, $re, 'i');
while($pos = mb_ereg_search_pos()){
$match = mb_ereg_search_getregs();
/* [子マッチングの定式化]:
$matche[1] : 現在の 「<...>」かどうかを示すA "/" 文字 摩擦は終了部分
$matche[2] : 要素名です。
$matche[3] : 右 > 「<...>」の 摩擦
*/
if($match[1]==""){
$Elem = $match[2];
if(mb_eregi($Single, $Elem) && $match[3] !=""){
続き;
}
array_push($Stack, mb_strtoupper($Elem));
array_push($posStack, $pos[0]);
}else{
$StackTop = $Stack[count($Stack)-1];
$End = mb_strtoupper($match[2]);
if(strcasecmp($StackTop,$End)==0){
array_pop($Stack);
array_pop($posStack);
if($match[3] ==""){
$Foremost = $Foremost.">";
}
}
}
}
$cutpos = array_shift($posStack) - 1;
$Foremost = mb_substr($Foremost,0,$cutpos,"UTF-8");
$Foremost を返します。
};

 今日头条发布文章怎么才能有收益?今日头条发布文章获得更多收益方法!Mar 15, 2024 pm 04:13 PM
今日头条发布文章怎么才能有收益?今日头条发布文章获得更多收益方法!Mar 15, 2024 pm 04:13 PM一、今日头条发布文章怎么才能有收益?今日头条发布文章获得更多收益方法!1.开通基础权益:原创文章选择投放广告可获得收益,视频必须要原创横屏才会有收益。2.开通百粉权益:粉丝量达到百粉以上,微头条、原创问答创作及问答均可获得收益。3.坚持原创作品:原创作品包含文章、微头条及问题等,要求300字以上。注意违规抄袭作品作为原创发布,会被扣信用分,即使有收益也会被扣除。4.垂直度:做专业领域一类的文章,不能随意跨领域写文章,会得不到合适的推荐,达不到作品的专和精,难以吸引粉丝读者。5.活跃度:活跃度高,
 五个方便好用的Python自动化脚本Apr 11, 2023 pm 07:31 PM
五个方便好用的Python自动化脚本Apr 11, 2023 pm 07:31 PM相比大家都听过自动化生产线、自动化办公等词汇,在没有人工干预的情况下,机器可以自己完成各项任务,这大大提升了工作效率。编程世界里有各种各样的自动化脚本,来完成不同的任务。尤其Python非常适合编写自动化脚本,因为它语法简洁易懂,而且有丰富的第三方工具库。这次我们使用Python来实现几个自动化场景,或许可以用到你的工作中。1、自动化阅读网页新闻这个脚本能够实现从网页中抓取文本,然后自动化语音朗读,当你想听新闻的时候,这是个不错的选择。代码分为两大部分,第一通过爬虫抓取网页文本呢,第二通过阅读工
 用Python写了个小工具,再复杂的文件夹,分分钟帮你整理!Apr 11, 2023 pm 08:19 PM
用Python写了个小工具,再复杂的文件夹,分分钟帮你整理!Apr 11, 2023 pm 08:19 PM糟透了我承认我不是一个爱整理桌面的人,因为我觉得乱糟糟的桌面,反而容易找到文件。哈哈,可是最近桌面实在是太乱了,自己都看不下去了,几乎占满了整个屏幕。虽然一键整理桌面的软件很多,但是对于其他路径下的文件,我同样需要整理,于是我想到使用Python,完成这个需求。效果展示我一共为将文件分为9个大类,分别是图片、视频、音频、文档、压缩文件、常用格式、程序脚本、可执行程序和字体文件。# 不同文件组成的嵌套字典 file_dict = { '图片': ['jpg','png','gif','webp
 wps目录怎么自动生成目录页码Feb 27, 2024 pm 04:01 PM
wps目录怎么自动生成目录页码Feb 27, 2024 pm 04:01 PMWPS是一款功能强大的办公软件,可以帮助我们高效地完成各种办公任务。其中,自动生成目录页码是一项非常实用的功能。能极大的为用户们提高自己的工作效率,那么下面本站小编就带来本文详细为大家介绍一下如何使用WPS自动生成目录页码,希望能帮助到各位有需要的小伙伴们。wps目录怎么自动生成目录页码首先打开wps群文档,在空白处输入要生成目录的内容,然后在开始菜单栏中选择标题1、标题2、标题3的样式。2、然后设置好之后我们点击其中的【引用】功能,点击之后在引用的工具栏中,在这里我们点击【目录】;3、最后点击
 从头开始构建,DeepMind新论文用伪代码详解TransformerApr 09, 2023 pm 08:31 PM
从头开始构建,DeepMind新论文用伪代码详解TransformerApr 09, 2023 pm 08:31 PM2017 年 Transformer 横空出世,由谷歌在论文《Attention is all you need》中引入。这篇论文抛弃了以往深度学习任务里面使用到的 CNN 和 RNN。这一开创性的研究颠覆了以往序列建模和 RNN 划等号的思路,如今被广泛用于 NLP。大热的 GPT、BERT 等都是基于 Transformer 构建的。Transformer 自推出以来,研究者已经提出了许多变体。但大家对 Transformer 的描述似乎都是以口头形式、图形解释等方式介绍该架构。关于 Tra
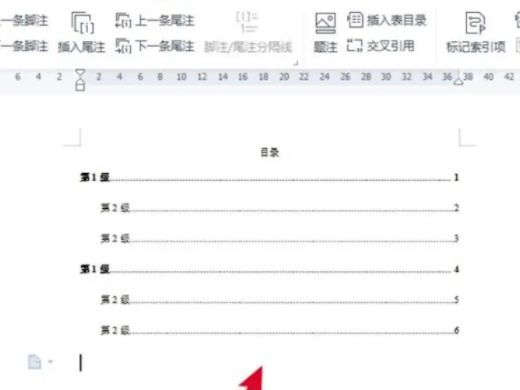 目录怎么自动生成 自动生成目录格式怎么设置Feb 22, 2024 pm 03:30 PM
目录怎么自动生成 自动生成目录格式怎么设置Feb 22, 2024 pm 03:30 PM在word中挑选目录的款式,操作完成就可以自动生成了。解析1进到电脑的word,点一下引入。2进去后,点一下文件目录。3接着挑选文件目录的款式。4操作完成,就可以看到文件目录自动生成了。补充:总结/注意事项文章的目录自动生成,其中包括一级标题、二级标题和三级标题,通常不超过三级标题。
 集成GPT-4的Cursor让编写代码和聊天一样简单,用自然语言编写代码的新时代已来Apr 04, 2023 pm 12:15 PM
集成GPT-4的Cursor让编写代码和聊天一样简单,用自然语言编写代码的新时代已来Apr 04, 2023 pm 12:15 PM集成GPT-4的Github Copilot X还在小范围内测中,而集成GPT-4的Cursor已公开发行。Cursor是一个集成GPT-4的IDE,可以用自然语言编写代码,让编写代码和聊天一样简单。 GPT-4和GPT-3.5在处理和编写代码的能力上差别还是很大的。官网的一份测试报告。前两个是GPT-4,一个采用文本输入,一个采用图像输入;第三个是GPT3.5,可以看出GPT-4的代码能力相较于GPT-3.5有较大能力的提升。集成GPT-4的Github Copilot X还在小范围内测中,而
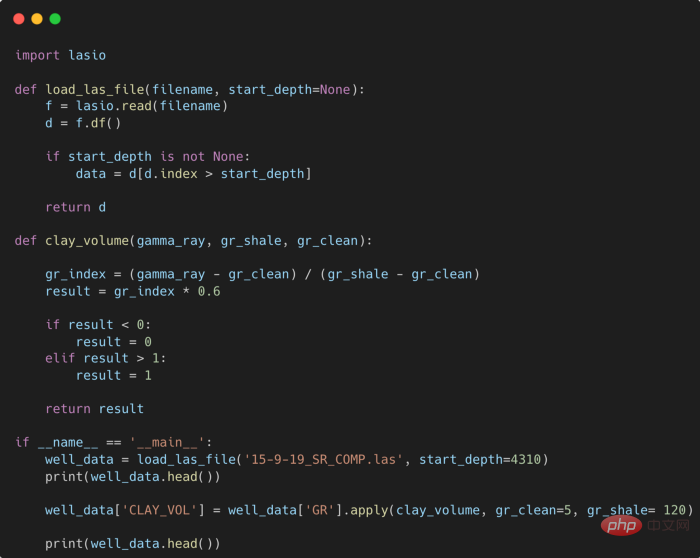 提高Python代码可读性的五个基本技巧Apr 11, 2023 pm 09:07 PM
提高Python代码可读性的五个基本技巧Apr 11, 2023 pm 09:07 PM译者 | 赵青窕审校 | 孙淑娟你是否经常回头看看6个月前写的代码,想知道这段代码底是怎么回事?或者从别人手上接手项目,并且不知道从哪里开始?这样的情况对开发者来说是比较常见的。Python中有许多方法可以帮助我们理解代码的内部工作方式,因此当您从头来看代码或者写代码时,应该会更容易地从停止的地方继续下去。在此我给大家举个例子,我们可能会得到如下图所示的代码。这还不是最糟糕的,但有一些事情需要我们去确认,例如:在load_las_file函数中f和d代表什么?为什么我们要在clay函数中检查结果


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

SublimeText3 中国語版
中国語版、とても使いやすい

WebStorm Mac版
便利なJavaScript開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン
ホットトピック
 7448
7448 15137452
15137452