
ホームページ >ウェブフロントエンド >jsチュートリアル >js_javascript スキルで最も近い共通の祖先要素を見つけるための実装コード
js_javascript スキルで最も近い共通の祖先要素を見つけるための実装コード

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2016-05-16 18:12:561414ブラウズ
まず概念を見てみましょう。まず、DOM はツリーであり、そのルート ノードは次の図で表すことができます。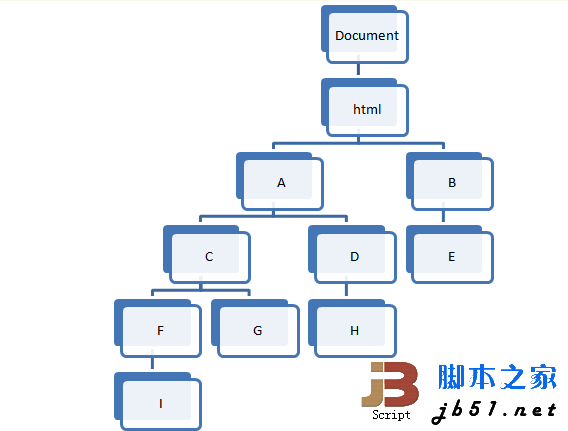
いわゆる「最近の共通祖先」です。 「要素」は、指定された一連の要素を参照し、ツリー内で最も深い要素を見つけますが、これらすべての要素の祖先でもあります。
たとえば、上の図では、I と G の結果は C、G と H の結果は A、D と E の結果は html、C と B の結果は html、等
テスト駆動
論理的な質問については、関数が正しいかどうか完全に確信が持てないため、それでも最初にテスト関数を構築し、その関数がテストに合格するように努めます。
今回はDOM構造として上図の構造を使用し、Aはbody、Bはhead、その他のノードはdiv要素を使用しています。テストの入力と出力として使用されます。 まず、テストを構築します:
コードをコピーします コードは次のとおりです:
関数 test() {
var result
result = find('i', 'g');
result.id !== 'c' && alter('失敗 (i, g)');
結果 = find('g' , 'h');
結果.id !== 'a' && アラート('失敗 (g, h)');
結果 = find('d', 'e');
result.nodeName.toLowerCase() !== 'html' && アラート('fail (d, e)'); find('c', 'b');
result.nodeName.toLowerCase () !== 'html' &&alert('fail (c, b)');
基本ロジック
今回のロジックは大まかに次のとおりです:
2. 要素をキー、走査回数を値として、走査プロセス中に渡された各要素を順序付きマップに保存します。
2. 最後に、マップを走査し、最初の値が指定された要素の数と同じである項目を見つけます。これは、走査内のすべての要素によって渡された最初の要素、つまり、最も最近の共通要素です。祖先要素。
詳細な問題
実際のプロセスでは、マップの構築がより重要です。ここには 2 つの問題が関係しています。
1. マップは要素をキーとして直接使用できないため、変換する必要があります。適切なプリミティブのタイプ (数値、文字列、正規表現など)。
2. Chrome はオブジェクト内のキーを自動的に並べ替えるため、キーとして数値型を使用しないようにしてください。
最初の質問では、一意の識別子として機能するように、適切なフィールドを要素にバインドする必要があります。幸いなことに、HTML5 には data-* 属性が用意されており、これにより DOM のメタデータ保持能力が大幅に向上し、必要な属性を大胆に追加できます。
2 番目の質問に関しては、それ自体は難しいことではありません。生成された識別子に数値を含めないでください。アンダースコアを追加するか、String.fromCharCode を使用して文字に変換します。 、 それは問題ではありません。
実装コード
このコードは、主に JAVA スタイルを好むため、条件付き分岐を処理するために && または || を使用するのが好きではありません。中括弧のような場合、本当に効果的なコードは実際には合理化されています。 toggleなどのプラグインをインストールするのはめんどくさいし、スクロールバーも見たくないのでここに放り込みました。
コードをコピー
コードは次のとおりです。 function find() { var length = 引数 .length,
i = 0, node, //現在のノード
parent, //親ノード
counter = 0,
uuid, //DOMの一意の識別子
hash = {}; //最終結果のマップ
//各要素について、ドキュメントまで上方向に移動します
//この 2 層ループは避けられません
for (; i < length; i ) {
//ノードの取得
node = argument[i];
if (typeof node == 'string') {
node = document.getElementById(node) ;
}
//上方向にトラバース
while (parent = node.parentElement || node.parentNode) {
//ドキュメントに到達したら停止します。そうでない場合は無限ループになります
if (parent.nodeType == 9) {
break;
}
//識別子を取得または追加します
uuid =parent.getAttribute('data-find'); (!uuid) {
uuid = '_' (counter) //Chrome のハッシュの並べ替えを回避します
parent.setAttribute('data-find', uuid);
// count
if (hash[uuid]) {
hash[uuid].count ;
}
else {
hash[uuid] = {ノード: 親、カウント: 1}; 🎜>}
node =parent;
}
}
//ハッシュには各ノードが上方向にトラバースした親ノードのみが含まれており、あまり大きくない必要があります
//したがって、このループは比較的高速です
for (i in hash) {
if (hash[i].count == length) {
return hash[i].node;
}
}
};
コメント
テストには問題はありませんが、テスト ケースが完璧であるかどうかを言うのは難しいです。論理的なタイプについては、ネチズンが問題を見つけるのを手伝ってくれることを願っています。 100%大丈夫だと自信を持って言えます。
親要素を取得するには、IE との互換性のためにparentElement || を記述するのが一般的です。これは、要素が作成されたばかりで DOM に入っていない場合、parentNode が存在しないためです。 。ただし、この関数はノードが DOM ツリー内に存在することを保証します。実際には、parentElement は必要ありません。したがって、習慣的に互換性のあるコードが必ずしも良いとは限らない場合があります。現在の環境に最も適したコードが良いコードです。
二重ループは避けられないと言われていますが、特定の状況ではまだ軽減する方法があるのではないかと漠然と感じています。たとえば、上向きにトラバースする場合、特定の要素が共通の祖先になることができないことがわかります。すべての要素の場合は、カウント値をそれ以上インクリメントしないでください。
最後の for..in ループを省略する方法はありますか?上記の二重ループで、変数を介して常に最適なノードをリアルタイムで保存する方法はありますか?
parent, //親ノード
counter = 0,
uuid, //DOMの一意の識別子
hash = {}; //最終結果のマップ
//各要素について、ドキュメントまで上方向に移動します
//この 2 層ループは避けられません
for (; i < length; i ) {
//ノードの取得
node = argument[i];
if (typeof node == 'string') {
node = document.getElementById(node) ;
}
//上方向にトラバース
while (parent = node.parentElement || node.parentNode) {
//ドキュメントに到達したら停止します。そうでない場合は無限ループになります
if (parent.nodeType == 9) {
break;
}
//識別子を取得または追加します
uuid =parent.getAttribute('data-find'); (!uuid) {
uuid = '_' (counter) //Chrome のハッシュの並べ替えを回避します
parent.setAttribute('data-find', uuid);
// count
if (hash[uuid]) {
hash[uuid].count ;
}
else {
hash[uuid] = {ノード: 親、カウント: 1}; 🎜>}
node =parent;
}
}
//ハッシュには各ノードが上方向にトラバースした親ノードのみが含まれており、あまり大きくない必要があります
//したがって、このループは比較的高速です
for (i in hash) {
if (hash[i].count == length) {
return hash[i].node;
}
}
};
コメント
テストには問題はありませんが、テスト ケースが完璧であるかどうかを言うのは難しいです。論理的なタイプについては、ネチズンが問題を見つけるのを手伝ってくれることを願っています。 100%大丈夫だと自信を持って言えます。
親要素を取得するには、IE との互換性のためにparentElement || を記述するのが一般的です。これは、要素が作成されたばかりで DOM に入っていない場合、parentNode が存在しないためです。 。ただし、この関数はノードが DOM ツリー内に存在することを保証します。実際には、parentElement は必要ありません。したがって、習慣的に互換性のあるコードが必ずしも良いとは限らない場合があります。現在の環境に最も適したコードが良いコードです。
二重ループは避けられないと言われていますが、特定の状況ではまだ軽減する方法があるのではないかと漠然と感じています。たとえば、上向きにトラバースする場合、特定の要素が共通の祖先になることができないことがわかります。すべての要素の場合は、カウント値をそれ以上インクリメントしないでください。
最後の for..in ループを省略する方法はありますか?上記の二重ループで、変数を介して常に最適なノードをリアルタイムで保存する方法はありますか?
声明:
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。