


CSS の正式名はカスケード スタイル シートで、中国語名はカスケード スタイル シート、カスケード スタイル シートとも呼ばれます。その利点は、コードを整理でき、一部のスタイルをバッチ処理できることです。
基本構文:
コメント記号: /* */
セレクター記号: selector {attribute:value} 同じ属性の値はスペースで区切られ、異なる属性はセミコロンで区切られます。 大文字と小文字を区別。
たとえば、ページ上のテーブルのスタイルをカスタマイズしたい場合は、 table {...;...;} と記述します。
セレクターの使用方法はたくさんあるので、面倒すぎて説明できませんでした。インターネットからコピーしたものをもう一度入力します:
| セレクターモード | 説明 |
| * | は任意の要素に一致します。 (ユニバーサルセレクター) |
| E | は、任意の要素 E (タイプ E の要素など) と一致します。 (タイプセレクター) |
| E F | 要素 E の子孫要素 F と一致します。 (子孫セレクター) |
| E > F | 要素 E のサブ要素 F と一致します。 (子セレクター) |
| E:第一子 | 要素 E が親要素内の最初の子要素である場合、要素 E と一致します。 (:first-child 擬似クラス) |
| E:リンク E:訪問しました | E が、ターゲットがまだ訪問されていない (:link) か、訪問されている (:visited) ハイパーリンクのソースアンカーである場合、要素 E と一致します。 (リンク疑似クラス) |
| E:アクティブ E:ホバー E:フォーカス | 特定のユーザーアクションで E と一致します。 (動的擬似クラス) |
| E:lang(c) | タイプ E の要素が (人間の) 言語 c にある場合、その要素と一致します (言語の決定方法はドキュメント言語によって決まります)。 (:lang() 擬似クラス) |
| E F | 要素 E が要素 F の直前にある場合、要素 F と一致します。 (近接セレクター) |
| E[属性] | 「attr」属性が設定されている要素 E と一致します (その値に関係なく)。 (属性セレクター) |
| E[attr="warning"] | 「attr」属性値が「warning」と厳密に等しい任意の要素 E と一致します。 (属性セレクター) |
| E[attr~="warning"] | 「attr」属性値がスペースで区切られた値のリストであり、その 1 つが厳密に「warning」に等しい要素 E と一致します。(属性选择器) |
| E[lang|="en"] | 匹配其“lang”属性具有以“en”开头(从左边)的值的列表的任意元素 E 。(属性选择器) |
| DIV.warning | 仅 HTML。用法同 DIV[class~="warning"]。(类选择器) |
| E#myid | 匹配 ID 等于“myid”的任意元素 E 。(ID 选择器) |
CSS の優先順位: 同じページまたは CSS ファイル内に、同じ要素の複数の定義が存在する場合があり、優先順位に従ってレンダリングする必要があります。優先度は、外部定義スタイルの優先度とその他のスタイルの優先度に分かれます。
外部定義スタイルの優先順位: 特定のアルゴリズムについては説明しません。ここでは単に結果について説明します: ID セレクター>クラス セレクター>属性セレクター>疑似クラス セレクター>要素セレクター>疑似要素セレクター>グローバルセレクター>その他
他のスタイル定義の優先順位: テキスト内スタイル、つまり要素内の style=... これが最も高度で、すべての外部定義スタイルよりも優先されます。 「!重要」はバージョンによって使い方が異なるため、詳細な説明は省略しますので、必要に応じて確認してください。継承によって取得されたスタイル: 優先度が最も低いスタイルです。
CSS 属性: http://www.jb51.net/w3school/css/css_reference.htm を参照してください (おい、これは無責任です! 秋)
CSS ユニット: http://www.jb51 。 net/w3school/css/css_units.htm (ブロガー、負け犬だ!落ちろ!)
(聞こえないふり)
申請リンクを入力しましょう ( ̄︶ ̄)
1. CSS を埋め込みます。現在のページのスタイル:
.tableStyle{
font-size:14px;
font-weight:bold
}
| title: |
|
| textarea name= "content" class="userData"cols="10"> |
2. CSS スタイル ファイルを埋め込みます:
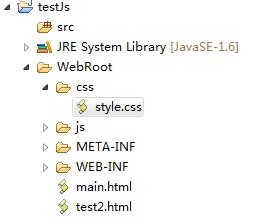
プロジェクトの下に新しい CSS フォルダーを作成し、style.css という名前の新しい CSS ファイルを作成します。もちろん、これはコードをきれいに保つために行われます。これは単なる例なので、先ほどの例の内容だけを書きました。
コードをコピー
コードは次のとおりです。
これも簡単です。 1 行追加:
rel は追加する CSS スタイル シート ファイルを指定し、次のように入力します。 href はファイルの種類を指定します。
3 CSS スタイルを動的に変更します。
最後に、js と関係があります。
この変更メソッドは、要素を取得してその属性を変更するだけです。言及しておきたいのは、リンクの属性も変更できるということです。
コードをコピー
コードは次のとおりです。
XML 部分から始めましょう
(ブロガーのあなた、あなたの誠実さはどこにありますか? ! )
XML を本当に詳しく学びたい場合は、別のシリーズを始めることができます。 。したがって、ここではそれについて簡単に説明します。
xml の正式名は、拡張マークアップ言語です。これは、データをより適切に、より柔軟に、より広範に記述するために存在します。ほぼすべてのタグはユーザー定義可能です。
たとえば、書籍に関する情報を保存したい場合は、次のようなさまざまな方法で保存できます。
コードをコピー
コードは次のとおりです:
....名前>
..
XML にもいくつかの無効なルールがあります:
xml 以外のすべての要素は閉じられている必要があります。つまり、
属性値は引用符で囲まれている必要があります。
大文字と小文字を区別します
名前を文字でタグ付けします。 「_」と「:」で始まり、その後に文字、数字、ピリオド、コロン、アンダースコアを続けることができます。
ルートノードは 1 つだけです。
XPath
XPath は、XML ファイル内の情報を検索して見つけるために使用される言語です。ツリー内の要素と属性を横断できます。
実際、ここで話しているのは単に xpath の構文について話しているだけです。
xpath の構文については、http://www.jb51.net/w3school/xpath/xpath_syntax.htm を参照してください。
「XPath 構文」、「XPath 軸」、「XPath 演算子」を簡単に参照し、リファレンスを参照してください。上記 Web ページの「XPath Functions」の「Manual」列を参照してください。
大まかな内容を参照した後、演習のこの部分を開始できます:
最初に XML ファイルを指定します:
接下来是FF的:
| book name: | |
| book author: |
xml在FF中的读取网上的资源很少,我找了好多也没找到可以读到结点值的,于是我用debug在ff浏览器下观察了好久,终于找到了 author.childNodes[0].nodeValue 这一句。
XML文件在firefox浏览器下的读取主要有两个类实现,一个是XPathEvaluator, XPathResult。其实就是用XPathEvaluator查找,然后在XPathResult里存储查找结果。可以看到我的代码里用XPathEvaluator查找的部分,那个函数evaluate的参数非常多,但是必须要了解这个函数才行,摘取下别人的东西(原内容点这里):
函数:evaluate(xpathText,contextNode,namespaceURLMapper,resultType,result)
| 参数 | 描述 |
|---|---|
| xpathText | 表示要计算的 XPath 表达式的字符串。 |
| contextNode | 文档中,对应要计算的表达式的节点。 |
| namespaceURLMapper |
把一个命名空间前缀映射为一个全称命名空间 URL 的函数。 如果不需要这样的映射,就为 null。 |
| resultType |
指定了期待作为结果的对象的类型,使用 XPath 转换来强制结果类型。 类型的可能的值是 XPathResult 对象所定义的常量。 |
| result |
一个复用的 XPathResult 对象; 如果你要创建一个新的 XPathResult 对象,则为 null。 |
| 返回类型 | 说明 |
| ANY_TYPE | 把这个值传递给 Document.evaluate() 或 XPathExpression.evaluate() 来指定可接受的结果类型。属性 resultType 并不设置这个值。 |
| NUMBER_TYPE | numbervalue 保存结果。 |
| STRING_TYPE | stringvalue 保存结果。 |
| BOOLEAN_TYPE | booleanValue 保存结果。 |
| UNORDERED_NODE_ITERATOR_TYPE | 这个结果是节点的无序集合,可以通过重复调用 iterateNext() 直到返回 null 来依次访问。在此迭代过程中,文档必须不被修改。 |
| ORDERED_NODE_ITERATOR_TYPE | 结果是节点的列表,按照文档中的属性排列,可以通过重复调用 iterateNext() 直到返回 null 来依次访问。在此迭代过程中,文档必须不被修改。 |
| UNORDERED_NODE_SNAPSHOT_TYPE | 结果是一个随机访问的节点列表。snapshotLength 属性指定了列表的长度,并且 snapshotItem() 方法返回指定下标的节点。节点可能和它们出现在文档中的顺序不一样。既然这种结果是一个“快照”,因此即便文档发生变化,它也有效。 |
| ORDERED_NODE_SNAPSHOT_TYPE | 这个结果是一个随机访问的节点列表,就像 UNORDERED_NODE_SNAPSHOT_TYPE,只不过这个列表是按照文档中的顺序排列的。 |
| ANY_UNORDERED_NODE_TYPE | singleNodeValue 属性引用和查询匹配的一个节点,如果没有匹配的节点则为 null。如果有多个节点和查询匹配,singleNodeValue 可能是任何一个匹配节点。 |
| FIRST_ORDERED_NODE_TYPE | singleNodeValue 保存了文档中的第一个和查询匹配的节点,如果没有匹配的节点,则为 null。 |
これらに加えて、XML ファイル ノードは実際に条件を追加できます。たとえば、最初の条件が満たされる限り、XML ファイル ノードには条件を追加できます。条件 ノード:
/bookstore/book[1]/title
または価格が 35 より高い:
/bookstore/book[price>35]/price
before この例では、すべての子ノードを返す効果を示したいため、条件付き選択は使用されていません。結局のところ、これが一般的に使用されるものです。
ここで言及されている XSLT と呼ばれる概念があります。これは、XML ファイルの変換に使用される言語で、正式名は拡張スタイルシート言語変換です。 XSLT は XPath を借用して XML ドキュメント内の情報を検索し、指定されたスタイルに従って XML ファイルに格納されているコンテンツを HTML ページとして表示できます。
特に興味のある学生はチェックしてみてください。しかし、私はとにかく興味がありません。 。 ╮(╯▽╰)╭
ついに、XML の最後の概念に到達しました。データアイランド
は、実際には、CSS と同様に、ページに XML データ情報が含まれていることを意味します。メソッドは内部的には
xmlデータアイランドのデータ datasrcとdatafldでhtmlタグへのバインディングは完了しましたが、試してみてもコードが実行できなかったので、とりあえずこのままにしておきます。コードを完成させます。

 Python vs. JavaScript:開発者の比較分析May 09, 2025 am 12:22 AM
Python vs. JavaScript:開発者の比較分析May 09, 2025 am 12:22 AMPythonとJavaScriptの主な違いは、タイプシステムとアプリケーションシナリオです。 1。Pythonは、科学的コンピューティングとデータ分析に適した動的タイプを使用します。 2。JavaScriptは弱いタイプを採用し、フロントエンドとフルスタックの開発で広く使用されています。この2つは、非同期プログラミングとパフォーマンスの最適化に独自の利点があり、選択する際にプロジェクトの要件に従って決定する必要があります。
 Python vs. JavaScript:ジョブに適したツールを選択するMay 08, 2025 am 12:10 AM
Python vs. JavaScript:ジョブに適したツールを選択するMay 08, 2025 am 12:10 AMPythonまたはJavaScriptを選択するかどうかは、プロジェクトの種類によって異なります。1)データサイエンスおよび自動化タスクのPythonを選択します。 2)フロントエンドとフルスタック開発のためにJavaScriptを選択します。 Pythonは、データ処理と自動化における強力なライブラリに好まれていますが、JavaScriptはWebインタラクションとフルスタック開発の利点に不可欠です。
 PythonとJavaScript:それぞれの強みを理解するMay 06, 2025 am 12:15 AM
PythonとJavaScript:それぞれの強みを理解するMay 06, 2025 am 12:15 AMPythonとJavaScriptにはそれぞれ独自の利点があり、選択はプロジェクトのニーズと個人的な好みに依存します。 1. Pythonは、データサイエンスやバックエンド開発に適した簡潔な構文を備えた学習が簡単ですが、実行速度が遅くなっています。 2。JavaScriptはフロントエンド開発のいたるところにあり、強力な非同期プログラミング機能を備えています。 node.jsはフルスタックの開発に適していますが、構文は複雑でエラーが発生しやすい場合があります。
 JavaScriptのコア:CまたはCの上に構築されていますか?May 05, 2025 am 12:07 AM
JavaScriptのコア:CまたはCの上に構築されていますか?May 05, 2025 am 12:07 AMjavascriptisnotbuiltoncorc;それは、解釈されていることを解釈しました。
 JavaScriptアプリケーション:フロントエンドからバックエンドまでMay 04, 2025 am 12:12 AM
JavaScriptアプリケーション:フロントエンドからバックエンドまでMay 04, 2025 am 12:12 AMJavaScriptは、フロントエンドおよびバックエンド開発に使用できます。フロントエンドは、DOM操作を介してユーザーエクスペリエンスを強化し、バックエンドはnode.jsを介してサーバータスクを処理することを処理します。 1.フロントエンドの例:Webページテキストのコンテンツを変更します。 2。バックエンドの例:node.jsサーバーを作成します。
 Python vs. Javascript:どの言語を学ぶべきですか?May 03, 2025 am 12:10 AM
Python vs. Javascript:どの言語を学ぶべきですか?May 03, 2025 am 12:10 AMPythonまたはJavaScriptの選択は、キャリア開発、学習曲線、エコシステムに基づいている必要があります。1)キャリア開発:Pythonはデータサイエンスとバックエンド開発に適していますが、JavaScriptはフロントエンドおよびフルスタック開発に適しています。 2)学習曲線:Python構文は簡潔で初心者に適しています。 JavaScriptの構文は柔軟です。 3)エコシステム:Pythonには豊富な科学コンピューティングライブラリがあり、JavaScriptには強力なフロントエンドフレームワークがあります。
 JavaScriptフレームワーク:最新のWeb開発のパワーMay 02, 2025 am 12:04 AM
JavaScriptフレームワーク:最新のWeb開発のパワーMay 02, 2025 am 12:04 AMJavaScriptフレームワークのパワーは、開発を簡素化し、ユーザーエクスペリエンスとアプリケーションのパフォーマンスを向上させることにあります。フレームワークを選択するときは、次のことを検討してください。1。プロジェクトのサイズと複雑さ、2。チームエクスペリエンス、3。エコシステムとコミュニティサポート。
 JavaScript、C、およびブラウザの関係May 01, 2025 am 12:06 AM
JavaScript、C、およびブラウザの関係May 01, 2025 am 12:06 AMはじめに私はあなたがそれを奇妙に思うかもしれないことを知っています、JavaScript、C、およびブラウザは正確に何をしなければなりませんか?彼らは無関係であるように見えますが、実際、彼らは現代のウェブ開発において非常に重要な役割を果たしています。今日は、これら3つの間の密接なつながりについて説明します。この記事を通して、JavaScriptがブラウザでどのように実行されるか、ブラウザエンジンでのCの役割、およびそれらが協力してWebページのレンダリングと相互作用を駆動する方法を学びます。私たちは皆、JavaScriptとブラウザの関係を知っています。 JavaScriptは、フロントエンド開発のコア言語です。ブラウザで直接実行され、Webページが鮮明で興味深いものになります。なぜJavascrを疑問に思ったことがありますか


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

メモ帳++7.3.1
使いやすく無料のコードエディター

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

