



Cでデータ構造とアルゴリズムを実装することは、次の手順に分けることができます。1。基本的な知識を確認し、データ構造とアルゴリズムの基本概念を理解します。 2。配列やリンクリストなどの基本的なデータ構造を実装します。 3.バイナリ検索ツリーなどの複雑なデータ構造を実装します。 4.クイックソートやバイナリ検索などの一般的なアルゴリズムを記述します。 5.一般的な間違いを避けるために、デバッグスキルを適用します。 6.パフォーマンスの最適化を実行し、適切なデータ構造とアルゴリズムを選択します。これらの手順を通じて、データ構造とアルゴリズムをゼロから構築および適用して、プログラミングの効率と問題解決機能を改善できます。

導入
プログラミングの世界では、データ構造とアルゴリズムは、すべての開発者が習得しなければならないコアの知識です。インタビュー中のホットトピックだけでなく、効率的で信頼できるコードを書くための基礎でもあります。今日、私たちはこれらの概念をCで実装する方法に飛び込み、いくつかの実用的な経験とヒントを共有します。この記事を通して、一般的なデータ構造とアルゴリズムをゼロから構築する方法を学び、実際のプロジェクトにそれらを適用する方法を学びます。
基本的な知識のレビュー
Cジャーニーを開始する前に、データ構造とアルゴリズムの基本概念を確認しましょう。データ構造はデータを整理および保存する方法ですが、アルゴリズムは問題を解決するための一連の手順です。強力なプログラミング言語として、Cはこれらの概念を実装するための豊富なツールとライブラリを提供します。
Cの基本的なデータ構造には、配列、リンクリスト、スタック、キュー、ツリー、グラフなどが含まれますが、一般的なアルゴリズムはソーティング、検索、グラフトラバーサルなどをカバーします。これらの基本知識を理解することは、さらなる学習と実現の鍵です。
コアコンセプトまたは関数分析
データ構造の定義と機能
データ構造はプログラミングの基礎であり、メモリ内でデータが編成され、アクセスされる方法を決定します。たとえば、配列を採用してみましょう。配列は、要素がメモリに連続的に保存される線形データ構造であり、ランダムアクセスが非常に効率的になります。
// array example int arr [5] = {1、2、3、4、5};
std :: cout << arr [2] << std :: endl; //出力3アルゴリズムの仕組み
アルゴリズムは問題を解決するための特定の手順であり、それらがどのように機能するかを理解することは、最適化とデバッグに不可欠です。クイックソートを例にとると、クイックソートを使用してベンチマーク値を選択し、配列を2つの部分に分割してから、2つの部分を再帰的に並べ替えます。
//クイックソート例void Quicksort(int arr []、int low、int high){
if(low <high){
int pi = partition(arr、low、high);
QuickSort(arr、low、pi -1);
QuickSort(arr、pi 1、high);
}
}
intパーティション(int arr []、int low、int high){
int pivot = arr [high];
int i =(low -1);
for(int j = low; j <= high -1; j){
if(arr [j] <pivot){
私 ;
std :: swap(arr [i]、arr [j]);
}
}
std :: swap(arr [i 1]、arr [high]);
return(i 1);
}クイックソートのコアは、適切なベンチマーク値と効率的なパーティション化プロセスを選択することです。これにより、平均時間の複雑さがあります(n log n)。
使用の例
基本的な使用法
Cにシンプルなリンクリストを実装する方法を見てみましょう。リンクリストは、頻繁な挿入および削除操作に適した動的なデータ構造です。
//リンクリストノード定義struct node {
INTデータ;
node* next;
ノード(int val):data(val)、next(nullptr){}
};
// Linked List ClassLinkedList {
プライベート:
ノード*ヘッド;
公共:
linkedlist():head(nullptr){}
void insert(int val){
node* newNode = new Node(val);
newNode-> next = head;
head = newNode;
}
void display(){
node* current = head;
while(current!= nullptr){
std :: cout << current-> data << "";
current = current-> next;
}
std :: cout << std :: endl;
}
};
// LinkedListのサンプルリストを使用します。
list.insert(3);
list.insert(2);
list.insert(1);
list.display(); //出力:1 2 3高度な使用
次に、迅速な検索とソートに適した、より複雑なデータ構造であるバイナリ検索ツリー(BST)を実装しましょう。
//バイナリ検索ツリーノード定義構造treeNode {
int val;
treeNode*左;
treenode*右;
treenode(int x):val(x)、left(nullptr)、右(nullptr){}
};
// binarysearchtree {
プライベート:
treenode* root;
treeNode* insertrecursive(treenode* node、int val){
if(node == nullptr){
new TreeNode(val)を返します。
}
if(val <node-> val){
node-> left = insertrecursive(node-> left、val);
} else if(val> node-> val){
node-> right = insertrecursive(node-> right、val);
}
ノードを返す;
}
void inordertraversalRecursive(treeNode* node){
if(node!= nullptr){
InORDERTRAVERSALRECURSIVE(node-> left);
std :: cout << node-> val << "";
inORDERTRAVERSALRECURSIVE(node-> right);
}
}
公共:
binarysearchtree():root(nullptr){}
void insert(int val){
root = insertrecursive(root、val);
}
void inordertraversal(){
InORDERTRAVERSALRECURSIVE(root);
std :: cout << std :: endl;
}
};
// binarysearchtreeの例を使用します。
bst.insert(5);
bst.insert(3);
bst.insert(7);
bst.insert(1);
bst.insert(9);
bst.inordertraversal(); //出力:1 3 5 7 9一般的なエラーとデバッグのヒント
一般的なエラーには、データ構造とアルゴリズムを実装する際のメモリリーク、バウンドアウトアクセス、および論理エラーが含まれます。デバッグのヒントは次のとおりです。
-
std::unique_ptrやstd::shared_ptrなどのスマートポインターを使用して、メモリを管理し、メモリリークを回避します。 - コードの正確性、特に境界の状況を確認するためのユニットテストを記述します。
- デバッガー(GDBなど)を使用して、プログラムの実行を追跡し、論理エラーを見つけます。
パフォーマンスの最適化とベストプラクティス
実世界のプロジェクトでは、パフォーマンスの最適化とベストプラクティスが重要です。ここにいくつかの提案があります:
- 適切なデータ構造とアルゴリズムを選択します。たとえば、ハッシュテーブルを使用して迅速な検索に使用し、優先キューにヒープを使用します。
- 最適化アルゴリズムの時間の複雑さ:たとえば、動的プログラミングを使用して重複するサブ問題を解決し、貪欲なアルゴリズムを使用して最適化の問題を解決します。
- コードの読みやすさと保守性を向上させる:意味のある変数と関数名を使用し、コメントとドキュメントを追加し、コードスタイルガイドに従ってください。
パフォーマンスの比較に関しては、例を見てみましょう。大きな配列に要素を見つける必要があるとし、線形検索の時間の複雑さはO(n)であり、バイナリ検索の使用時間の複雑さはO(log n)です。以下は、バイナリ検索の実装です。
//バイナリ検索の例int binarysearch(int arr []、int left、int right、int x){
while(左<=右){
int mid =左(右 - 左) / 2;
if(arr [mid] == x){
途中で戻ります。
}
if(arr [mid] <x){
左= 1ミッド1;
} それ以外 {
右= MID -1;
}
}
return -1; // 見つかりません}
// int arr [] = {2、3、4、10、40}を使用します。
int n = sizeof(arr) / sizeof(arr [0]);
int x = 10;
int result = binarysearch(arr、0、n -1、x);
(結果== -1)? std :: cout << "要素は配列に存在しません」
:std :: cout << "要素はindexに存在します" << result;適切なアルゴリズムを選択することにより、プログラムのパフォーマンスを大幅に改善できます。
要するに、データ構造とアルゴリズムはプログラミングの中核です。それらをマスターすることは、効率的なコードを作成するのに役立つだけでなく、プログラミング思考と問題解決能力を向上させることもできます。この記事が、Cでデータ構造とアルゴリズムを実装するためのいくつかの実用的なガイダンスとインスピレーションを提供できることを願っています。
以上がCのデータ構造とアルゴリズム:実用的な実装ガイドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM
特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM特斯拉是一个典型的AI公司,过去一年训练了75000个神经网络,意味着每8分钟就要出一个新的模型,共有281个模型用到了特斯拉的车上。接下来我们分几个方面来解读特斯拉FSD的算法和模型进展。01 感知 Occupancy Network特斯拉今年在感知方面的一个重点技术是Occupancy Network (占据网络)。研究机器人技术的同学肯定对occupancy grid不会陌生,occupancy表示空间中每个3D体素(voxel)是否被占据,可以是0/1二元表示,也可以是[0, 1]之间的
 基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM
基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM译者 | 朱先忠审校 | 孙淑娟在我之前的博客中,我们已经了解了如何使用因果树来评估政策的异质处理效应。如果你还没有阅读过,我建议你在阅读本文前先读一遍,因为我们在本文中认为你已经了解了此文中的部分与本文相关的内容。为什么是异质处理效应(HTE:heterogenous treatment effects)呢?首先,对异质处理效应的估计允许我们根据它们的预期结果(疾病、公司收入、客户满意度等)选择提供处理(药物、广告、产品等)的用户(患者、用户、客户等)。换句话说,估计HTE有助于我
 Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM
Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM译者 | 朱先忠审校 | 孙淑娟引言模型超参数(或模型设置)的优化可能是训练机器学习算法中最重要的一步,因为它可以找到最小化模型损失函数的最佳参数。这一步对于构建不易过拟合的泛化模型也是必不可少的。优化模型超参数的最著名技术是穷举网格搜索和随机网格搜索。在第一种方法中,搜索空间被定义为跨越每个模型超参数的域的网格。通过在网格的每个点上训练模型来获得最优超参数。尽管网格搜索非常容易实现,但它在计算上变得昂贵,尤其是当要优化的变量数量很大时。另一方面,随机网格搜索是一种更快的优化方法,可以提供更好的
 因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM
因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM导读:因果推断是数据科学的一个重要分支,在互联网和工业界的产品迭代、算法和激励策略的评估中都扮演者重要的角色,结合数据、实验或者统计计量模型来计算新的改变带来的收益,是决策制定的基础。然而,因果推断并不是一件简单的事情。首先,在日常生活中,人们常常把相关和因果混为一谈。相关往往代表着两个变量具有同时增长或者降低的趋势,但是因果意味着我们想要知道对一个变量施加改变的时候会发生什么样的结果,或者说我们期望得到反事实的结果,如果过去做了不一样的动作,未来是否会发生改变?然而难点在于,反事实的数据往往是
 使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PM
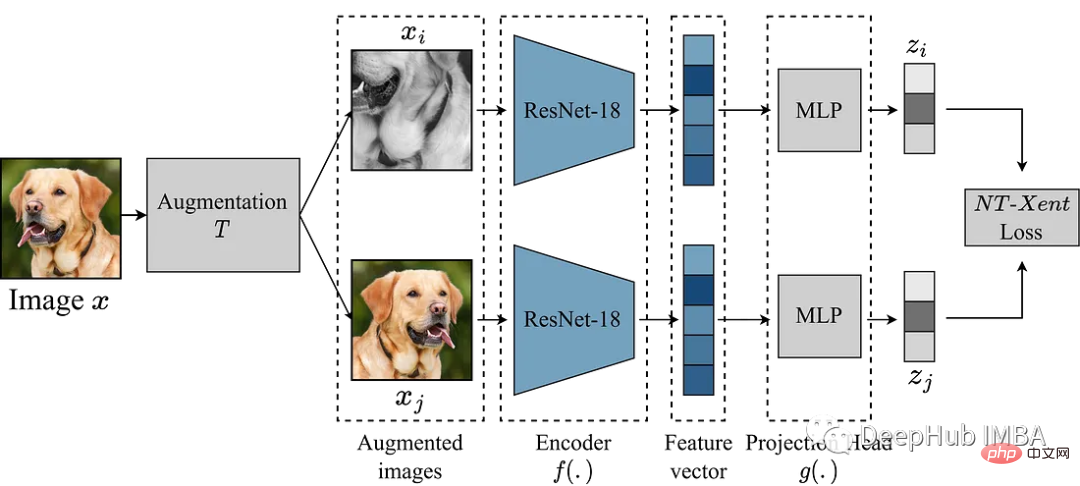
使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PMSimCLR(Simple Framework for Contrastive Learning of Representations)是一种学习图像表示的自监督技术。 与传统的监督学习方法不同,SimCLR 不依赖标记数据来学习有用的表示。 它利用对比学习框架来学习一组有用的特征,这些特征可以从未标记的图像中捕获高级语义信息。SimCLR 已被证明在各种图像分类基准上优于最先进的无监督学习方法。 并且它学习到的表示可以很容易地转移到下游任务,例如对象检测、语义分割和小样本学习,只需在较小的标记
 盒马供应链算法实战Apr 10, 2023 pm 09:11 PM
盒马供应链算法实战Apr 10, 2023 pm 09:11 PM一、盒马供应链介绍1、盒马商业模式盒马是一个技术创新的公司,更是一个消费驱动的公司,回归消费者价值:买的到、买的好、买的方便、买的放心、买的开心。盒马包含盒马鲜生、X 会员店、盒马超云、盒马邻里等多种业务模式,其中最核心的商业模式是线上线下一体化,最快 30 分钟到家的 O2O(即盒马鲜生)模式。2、盒马经营品类介绍盒马精选全球品质商品,追求极致新鲜;结合品类特点和消费者购物体验预期,为不同品类选择最为高效的经营模式。盒马生鲜的销售占比达 60%~70%,是最核心的品类,该品类的特点是用户预期时
 研究表明强化学习模型容易受到成员推理攻击Apr 09, 2023 pm 08:01 PM
研究表明强化学习模型容易受到成员推理攻击Apr 09, 2023 pm 08:01 PM译者 | 李睿 审校 | 孙淑娟随着机器学习成为人们每天都在使用的很多应用程序的一部分,人们越来越关注如何识别和解决机器学习模型的安全和隐私方面的威胁。 然而,不同机器学习范式面临的安全威胁各不相同,机器学习安全的某些领域仍未得到充分研究。尤其是强化学习算法的安全性近年来并未受到太多关注。 加拿大的麦吉尔大学、机器学习实验室(MILA)和滑铁卢大学的研究人员开展了一项新研究,主要侧重于深度强化学习算法的隐私威胁。研究人员提出了一个框架,用于测试强化学习模型对成员推理攻击的脆弱性。 研究
 人类反超 AI:DeepMind 用 AI 打破矩阵乘法计算速度 50 年记录一周后,数学家再次刷新Apr 11, 2023 pm 01:16 PM
人类反超 AI:DeepMind 用 AI 打破矩阵乘法计算速度 50 年记录一周后,数学家再次刷新Apr 11, 2023 pm 01:16 PM10 月 5 日,AlphaTensor 横空出世,DeepMind 宣布其解决了数学领域 50 年来一个悬而未决的数学算法问题,即矩阵乘法。AlphaTensor 成为首个用于为矩阵乘法等数学问题发现新颖、高效且可证明正确的算法的 AI 系统。论文《Discovering faster matrix multiplication algorithms with reinforcement learning》也登上了 Nature 封面。然而,AlphaTensor 的记录仅保持了一周,便被人类


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

Dreamweaver Mac版
ビジュアル Web 開発ツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません
ホットトピック
 7412
7412 15135952
15135952