



機械学習(ML)は現在、より正確なデータ駆動型の決定を下すために、ビジネスや研究者に力を与えています。個々のニーズに合わせて。

目次
- モデル選択定義
- モデル選択の重要性
- 初期モデルセットを選択する方法は?
- 選択したモデル(モデル選択手法)から最適なモデルを選択する方法は?
- 結論は
- よくある質問
モデル選択定義
モデル選択とは、モデルのパフォーマンスと問題要件との一貫性に基づいて、さまざまなオプションを評価することにより、特定のタスクに最も適した機械学習モデルを特定するプロセスを指します。これには、問題の種類(分類や回帰など)、データの特性、関連するパフォーマンスメトリック、および装着不足とオーバーフィッティングの間のトレードオフなどの要因を考慮します。コンピューティングリソースや解釈可能性の必要性などの実用的な制限も、選択に影響を与える可能性があります。目標は、最高のパフォーマンスを提供し、プロジェクトの目標と制約を満たすモデルを選択することです。
モデル選択の重要性
適切な機械学習(ML)モデルを選択することは、成功したAIソリューションを開発する上で重要なステップです。モデル選択の重要性は、MLアプリケーションのパフォーマンス、効率、および実現可能性への影響にあります。その重要性の理由は次のとおりです。
1。精度とパフォーマンス
異なるモデルは、さまざまなタスクタイプで優れています。たとえば、決定ツリーは分類されたデータに適している場合がありますが、畳み込みニューラルネットワーク(CNN)は画像認識に適しています。間違ったモデルを選択すると、最適ではない予測または高いエラー率が発生し、ソリューションの信頼性が低下します。
2。効率とスケーラビリティ
MLモデルの計算の複雑さは、トレーニングと推論時間に影響します。大規模またはリアルタイムのアプリケーションの場合、線形回帰やランダムフォレストなどの軽量モデルは、計算集中的なニューラルネットワークよりも適切かもしれません。
データの増加に合わせて効果的にスケーリングできないモデルは、ボトルネックにつながる可能性があります。
3。解釈可能性
アプリケーションによっては、解釈可能性が優先事項になる場合があります。たとえば、ヘルスケアまたは金融分野では、利害関係者はしばしば予測の明確な理由を持つ必要があります。単純なモデル(ロジスティック回帰など)は、ブラックボックスモデル(深いニューラルネットワークなど)よりも好ましい場合があります。
4。フィールドの適用性
一部のモデルは、特定のデータ型またはフィールド用に設計されています。時系列の予測は、ARIMAやLSTMなどのモデルの恩恵を受けますが、自然言語処理タスクはしばしばコンバーターベースのアーキテクチャを利用します。
5。リソースの制限
すべての組織が複雑なモデルを実行するコンピューティング能力を持っているわけではありません。リソースの制約内でうまく機能するよりシンプルなモデルは、パフォーマンスと実現可能性のバランスをとることができます。
6。過剰装着と一般化
多くのパラメーターを持つ複雑なモデルは、潜在的なパターンではなくノイズをキャプチャする簡単に過度に搭載されています。新しいデータに適切に一般化するモデルを選択すると、実際のパフォーマンスが向上します。
7。適応性
動的環境では、データ分布または要件の変更に適応するモデルの能力が重要です。たとえば、オンライン学習アルゴリズムは、データのリアルタイムの進化により適しています。
8。コストと開発時間
一部のモデルでは、多くのハイパーパラメーターの調整、機能エンジニアリング、またはラベリングデータが必要であり、開発コストと時間が増加します。適切なモデルを選択すると、開発と展開を簡素化できます。
初期モデルセットを選択する方法は?
まず、持っているデータと実行するタスクに基づいてモデルのセットを選択する必要があります。これにより、各MLモデルのテストに比べて時間を節約できます。

1。タスクに基づいて:
- 分類:目標がカテゴリ(「スパム」対「非スパム」など)を予測することである場合、分類モデルを使用する必要があります。
- モデルの例:ロジスティック回帰、意思決定ツリー、ランダムフォレスト、サポートベクターマシン(SVM)、k-nearest neightr(k-nn)、ニューラルネットワーク。
- 回帰:目標が継続的な値(住宅価格、株価など)を予測することである場合、回帰モデルを使用する必要があります。
- モデルの例:線形回帰、決定ツリー、ランダムフォレスト回帰、サポートベクトル回帰、ニューラルネットワーク。
- クラスタリング:目標が以前のタグなしでデータをクラスターにグループ化することである場合、クラスタリングモデルが使用されます。
- モデルの例:K-Mean、DBSCAN、階層クラスタリング、ガウスハイブリッドモデル。
- 異常検出:ターゲットがまれなイベントまたは外れ値を特定する場合、異常検出アルゴリズムを使用します。
- モデルの例:孤立した森林、単一クラスSVM、および自動エンコーダー。
- 時系列の予測:目標が時間データに基づいて将来の値を予測することである場合。
- モデルの例:アリマ、指数関数的なスムージング、LSTM、預言者。
2。データに基づいています
タイプ
- 構造化データ(表データ):意思決定ツリー、ランダムフォレスト、xgboost、ロジスティック回帰などのモデルを使用します。
- 非構造化データ(テキスト、画像、オーディオなど): CNN(画像用)、RNNまたはコンバーター(テキスト用)、オーディオ処理モデルなどのモデルを使用します。
サイズ
- 小さなデータセット:複雑なモデルが過剰に搭載される可能性があるため、単純なモデル(ロジスティック回帰や決定ツリーなど)はうまく機能する傾向があります。
- 大規模なデータセット:ディープラーニングモデル(ニューラルネットワーク、CNN、RNNなど)は、大量のデータを処理するのに適しています。
品質
- 欠損値:一部のモデル(ランダムフォレストなど)は欠損値を処理できますが、他のモデル(SVMなど)を帰属させる必要があります。
- 騒音と外れ値:堅牢なモデル(ランダムフォレストなど)または正規化(ラッソなど)のモデルは、ノイズデータを処理するための良い選択です。
選択したモデル(モデル選択手法)から最適なモデルを選択する方法は?
モデル選択は機械学習の重要な側面であり、特定のデータセットと問題で最高のパフォーマンスモデルを特定するのに役立ちます。 2つの主な手法は、それぞれが独自のモデル評価方法を備えた再サンプリング方法と確率測定です。
1。リサンプリング方法
再サンプリング方法では、データのサブセットを再配置および再利用して、目に見えないサンプル上のモデルのパフォーマンスをテストします。これにより、新しいデータを一般化するモデルの能力を評価するのに役立ちます。 2つの主な再サンプリング手法は次のとおりです。
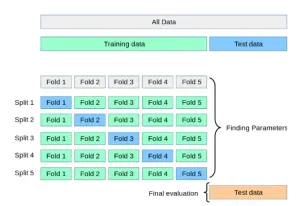
相互検証
相互検証は、モデルのパフォーマンスを評価するために使用される系統的な再サンプリング手順です。この方法では:
- データセットは、グループまたは折り目に分割されます。
- 1つのグループはテストデータとして使用され、残りはトレーニングに使用されます。
- このモデルは、すべての折り目でトレーニングおよび評価されます。
- すべての反復の平均パフォーマンスを計算して、信頼できる精度メトリックを提供します。
相互検証は、サポートベクトルマシン(SVM)やロジスティック回帰などのモデルを比較して、特定の問題に適しているモデルを決定する場合に特に役立ちます。
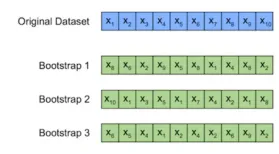
ブートストラップメソッド
Bootstrapは、モデルのパフォーマンスを推定するための代替方法でデータをランダムにサンプリングするサンプリング手法です。
主な機能
- 主に小さなデータセットで使用されます。
- サンプルデータとテストデータのサイズは、元のデータセットと一致します。
- 通常、最高スコアを生成するサンプルが使用されます。
このプロセスでは、観測値をランダムに選択し、それを記録し、データセットに戻し、プロセスをn回繰り返すことが含まれます。生成されたブートサンプルは、モデルの堅牢性に関する洞察を提供します。
2。確率測定
確率メトリックは、統計的メトリックと複雑さに基づいてモデルのパフォーマンスを評価します。これらのアプローチは、パフォーマンスとシンプルさのバランスをとることに焦点を当てています。再サンプリングとは異なり、パフォーマンスはトレーニングデータを使用して計算されるため、個別のテストセットは必要ありません。
アカギ情報ガイドライン(AIC)
AICは、フィット感とその複雑さの良さのバランスをとることにより、モデルを評価します。それは情報理論に由来し、過剰適合を避けるためにモデルのパラメーターの数を罰します。
式:

- 適合度:より高い可能性は、データのより良い適合を意味します。
- 複雑さのペナルティ: 2Kという用語は、過剰適合を避けるためのより多くのパラメーターを備えたモデルにペナルティを科します。
- 説明: AICスコアが低いほど、モデルは良くなります。ただし、AICは、フィット感と複雑さのバランスを取り、他の基準よりも厳格ではないため、過度に複雑なモデルに向かって歪むことがあります。
ベイジアン情報基準(BIC)
BICはAICに似ていますが、モデルの複雑さに対する罰はより強く、より保守的になります。これは、過剰適合が問題である時系列および回帰モデルのモデル選択に特に役立ちます。
式:

- フィット感の良さ: AICと同様に、より高い可能性はスコアを改善します。
- 複雑なペナルティ:この用語は、より多くのパラメーターでモデルを罰し、サンプルサイズnが増加するとペナルティが増加します。
- 説明: BICは、追加のパラメーターに対するより厳しいペナルティを意味するため、AICよりも単純なモデルである傾向があります。
最小説明長(MDL)
MDLは、データを最も効率的に圧縮するモデルを選択する原則です。情報理論に根ざしており、モデルとデータを説明するための総コストを最小限に抑えることを目的としています。
式:

- シンプルさと効率: MDLは、シンプルさ(モデルの説明の短い)と精度(データを表現する能力)の間の最適なバランスをモデル化する傾向があります。
- 圧縮:優れたモデルは、データの簡潔な要約を提供し、その説明の長さを効果的に削減します。
- 説明: MDLが最も低いモデルが推奨されます。
結論は
特定のユースケースに最適な機械学習モデルを選択するには、体系的なアプローチ、問題要件のバランス、データ特性、および実用的な制限が必要です。タスクの性質、データの構造、およびモデルの複雑さ、精度、および解釈可能性に関与するトレードオフを理解することにより、候補モデルを絞り込むことができます。交差検証や確率メトリック(AIC、BIC、MDL)などの技術は、これらの候補者が厳密に評価されていることを保証し、適切に一般化して目標を達成するモデルを選択できます。
最終的に、モデル選択プロセスは反復的でコンテキスト駆動型です。問題領域、リソースの制約、パフォーマンスと実現可能性のバランスを考慮することが重要です。ドメインの専門知識、実験、評価メトリックを慎重に統合することにより、最良の結果を提供するだけでなく、アプリケーションの実用的および運用上のニーズを満たすMLモデルを選択できます。
オンラインAI/MLコースを探している場合は、Exprore:認定AIおよびMLブラックベルトプラスプログラム
よくある質問
Q1。
A:最適なMLモデルの選択は、問題の種類(分類、回帰、クラスタリングなど)、データのサイズと品質、および精度、解釈可能性、計算効率の間に必要なトレードオフに依存します。最初に問題の種類を決定します(たとえば、データの分類に使用される数値または分類を予測するために使用される回帰)。小さなデータセットの場合、または解釈可能性が重要な場合は、線形回帰や決定ツリーなどの単純なモデルを使用し、より高い精度を必要とするより大きなデータセットの場合、ランダムフォレストやニューラルネットワークなどのより複雑なモデルを使用します。目標(精度、精度、RMSEなど)に関連するメトリックを使用してモデルを常に評価し、複数のアルゴリズムをテストして最適なフィット感を見つけてください。
Q2 MLモデルを比較する方法
A:2つのMLモデルを比較するには、一貫した評価メトリックを使用して同じデータセットでパフォーマンスを評価します。データをトレーニングセットとテストセットに分割し(またはクロス検証を使用)、正確性、精度、RMSEなどの質問に関連するメトリックを使用して、公平性を確保し、各モデルを評価します。結果は分析されて、どのモデルがパフォーマンスが向上するかを判断しますが、解釈可能性、トレーニング時間、スケーラビリティなどのトレードオフも検討します。パフォーマンスの違いが小さい場合は、統計テストを使用して有意性を確認します。最終的に、パフォーマンスとユースケースの実際の要件のバランスをとるモデルが選択されます。
Q3。販売を予測するのに最適ですか?
A:販売を予測するのに最適なMLモデルは、データセットと要件に依存しますが、一般的に使用されるモデルには、線形回帰、決定ツリー、Xgboostなどの勾配ブーストアルゴリズムが含まれます。線形回帰は、明確な線形傾向を持つ単純なデータセットに適しています。より複雑な関係や相互作用のために、勾配ブーストまたはランダムフォレストはしばしばより高い精度を提供します。データに時系列パターンが含まれる場合、Arima、Sarima、または長期記憶(LSTM)ネットワークなどのモデルがより適切です。販売予測需要の予測パフォーマンス、解釈可能性、およびスケーラビリティのバランスをとるモデルを選択します。
以上がUSECaseに最適なMLモデルを選択する方法は?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 ChatGPTが使えない!原因とすぐ試せる対処法を解説【2025年最新】May 14, 2025 am 05:04 AM
ChatGPTが使えない!原因とすぐ試せる対処法を解説【2025年最新】May 14, 2025 am 05:04 AMChatGptはアクセスできませんか?この記事では、さまざまな実用的なソリューションを提供しています!多くのユーザーは、ChatGPTを毎日使用する場合、アクセス不能や応答が遅いなどの問題に遭遇する可能性があります。この記事では、さまざまな状況に基づいてこれらの問題を段階的に解決するように導きます。 ChatGPTのアクセス不能性と予備的なトラブルシューティングの原因 まず、問題がOpenaiサーバー側にあるのか、ユーザー自身のネットワークまたはデバイスの問題にあるのかを判断する必要があります。 以下の手順に従って、トラブルシューティングしてください。 ステップ1:OpenAIの公式ステータスを確認してください OpenAIステータスページ(status.openai.com)にアクセスして、ChatGPTサービスが正常に実行されているかどうかを確認してください。赤または黄色のアラームが表示されている場合、それは開くことを意味します
 ASIのリスクを計算することは、人間の心から始まりますMay 14, 2025 am 05:02 AM
ASIのリスクを計算することは、人間の心から始まりますMay 14, 2025 am 05:02 AM2025年5月10日、MIT物理学者のMax Tegmarkは、AI Labsが人工的なスーパーインテリジェンスを解放する前にOppenheimerの三位一体計算をエミュレートすべきだとGuardianに語った。 「私の評価では、「コンプトン定数」、競争が
 ChatGPTで作詞・作曲する方法とおすすめツールをわかりやすく解説May 14, 2025 am 05:01 AM
ChatGPTで作詞・作曲する方法とおすすめツールをわかりやすく解説May 14, 2025 am 05:01 AMAI Music Creation Technologyは、1日ごとに変化しています。この記事では、ChatGPTなどのAIモデルを例として使用して、AIを使用して音楽の作成を支援し、実際のケースで説明する方法を詳細に説明します。 Sunoai、Hugging Face、PythonのMusic21 Libraryを通じて音楽を作成する方法を紹介します。 これらのテクノロジーを使用すると、誰もがオリジナルの音楽を簡単に作成できます。ただし、AIに生成されたコンテンツの著作権問題は無視できないことに注意する必要があります。使用する際には注意する必要があります。 音楽分野でのAIの無限の可能性を一緒に探りましょう! Openaiの最新のAIエージェント「Openai Deep Research」が紹介します。 [chatgpt] ope
 ChatGPT-4とは?できることや料金、GPT-3.5との違いを徹底解説!May 14, 2025 am 05:00 AM
ChatGPT-4とは?できることや料金、GPT-3.5との違いを徹底解説!May 14, 2025 am 05:00 AMChATGPT-4の出現により、AIアプリケーションの可能性が大幅に拡大しました。 GPT-3.5と比較して、CHATGPT-4は大幅に改善されました。強力なコンテキスト理解能力を備えており、画像を認識して生成することもできます。普遍的なAIアシスタントです。それは、ビジネス効率の改善や創造の支援など、多くの分野で大きな可能性を示しています。ただし、同時に、その使用における予防策にも注意を払わなければなりません。 この記事では、ChATGPT-4の特性を詳細に説明し、さまざまなシナリオの効果的な使用方法を紹介します。この記事には、最新のAIテクノロジーを最大限に活用するためのスキルが含まれています。参照してください。 Openaiの最新のAIエージェント、「Openai Deep Research」の詳細については、以下のリンクをクリックしてください
 ChatGPTのアプリの使い方を解説!日本語対応で音声会話機能もMay 14, 2025 am 04:59 AM
ChatGPTのアプリの使い方を解説!日本語対応で音声会話機能もMay 14, 2025 am 04:59 AMChatGPTアプリ:AIアシスタントで創造性を解き放つ!初心者向けガイド ChatGPTアプリは、文章作成、翻訳、質問応答など、多様なタスクに対応する革新的なAIアシスタントです。創作活動や情報収集にも役立つ、無限の可能性を秘めたツールです。 この記事では、ChatGPTスマホアプリのインストール方法から、音声入力機能やプラグインといったアプリならではの機能、そしてアプリ利用上の注意点まで、初心者にも分かりやすく解説します。プラグインの制限やデバイス間の設定同期についてもしっかりと触れていきま
 ChatGPTの中文版の利用方法は?登録手順や料金について解説May 14, 2025 am 04:56 AM
ChatGPTの中文版の利用方法は?登録手順や料金について解説May 14, 2025 am 04:56 AMChatgpt中国語版:中国語のAIの対話の新しい体験のロックを解除する ChatGptは世界中で人気がありますが、中国語版も提供していることをご存知ですか?この強力なAIツールは、毎日の会話をサポートするだけでなく、プロのコンテンツを処理し、簡素化された伝統的な中国語と互換性があります。中国のユーザーであろうと、中国語を学んでいる友人であろうと、あなたはそれから利益を得ることができます。 この記事では、アカウント設定、中国語の迅速な単語入力、フィルターの使用、さまざまなパッケージの選択を含むChatGpt中国語のバージョンの使用方法を詳細に紹介し、潜在的なリスクと対応戦略を分析します。さらに、ChatGpt中国語版を他の中国のAIツールと比較して、その利点とアプリケーションシナリオをよりよく理解するのに役立ちます。 Openaiの最新のAIインテリジェンス
 5 AIエージェントの神話あなたは今信じるのをやめる必要がありますMay 14, 2025 am 04:54 AM
5 AIエージェントの神話あなたは今信じるのをやめる必要がありますMay 14, 2025 am 04:54 AMこれらは、生成AIの分野で次の飛躍と考えることができ、ChatGptやその他の大規模なモデルのチャットボットを提供しました。単に質問に答えたり情報を生成したりするのではなく、彼らは私たちに代わって行動を起こすことができます。
 ChatGPTで複数アカウントを作成・管理する不法をわかりやすく解説May 14, 2025 am 04:50 AM
ChatGPTで複数アカウントを作成・管理する不法をわかりやすく解説May 14, 2025 am 04:50 AMChatGPTを活用した効率的な複数アカウント管理術|ビジネスとプライベートの使い分けも徹底解説! 様々な場面で活用されているChatGPTですが、複数アカウントの管理に頭を悩ませている方もいるのではないでしょうか。この記事では、ChatGPTの複数アカウント作成方法、利用上の注意点、そして安全かつ効率的な運用方法を詳しく解説します。ビジネス利用とプライベート利用の使い分け、OpenAIの利用規約遵守といった重要な点にも触れ、複数アカウントを安全に活用するためのガイドを提供します。 OpenAI


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

