
ホームページ >テクノロジー周辺機器 >AI >小言語モデルのパフォーマンス評価
小言語モデルのパフォーマンス評価

- Christopher Nolanオリジナル
- 2025-03-17 09:16:15997ブラウズ
この記事では、リソースが制約された環境に対する効率と適合性に焦点を当てた、より大きなカウンターパートよりも、小言語モデル(SLM)の利点について説明します。 SLMは、100億個のパラメーターを持つパラメーターが多いため、エッジコンピューティングとリアルタイムアプリケーションに速度とリソースの効率が重要です。この記事では、Google ColabでOllamaを使用した作成、アプリケーション、および実装について詳しく説明しています。
このガイドがカバーしています:
- SLMSの理解: SLMSの定義特性とLLMSとの重要な違いを学びます。
- SLM作成技術: LLMから効率的なSLMを作成するために使用される知識の蒸留、剪定、および量子化方法を調べます。
- パフォーマンス評価:さまざまなSLMS(Llama 2、Microsoft Phi、Qwen 2、Gemma 2、Mistral 7b)のパフォーマンスを、それらの出力の比較分析を介して比較します。
- 実用的な実装: Ollamaを使用してGoogleコラブでSLMを実行するための段階的なガイド。
- SLMSのアプリケーション:チャットボット、仮想アシスタント、エッジコンピューティングシナリオなどのSLMSが優れている多様なアプリケーションを発見します。
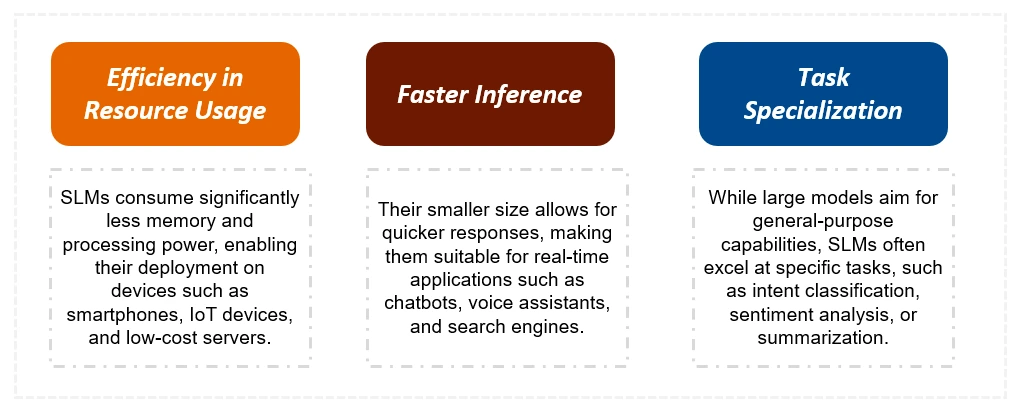
主な違い:SLMS対LLMS
SLMはLLMSよりも大幅に小さく、トレーニングデータと計算リソースが少なくなります。これにより、推論時間が速くなり、コストが削減されます。 LLMSは複雑な一般的なタスクで優れていますが、SLMは特定のタスクに最適化されており、リソース制限デバイスに適しています。以下の表は、重要な区別をまとめたものです。
| 特徴 | 小言語モデル(SLM) | 大きな言語モデル(LLMS) |
|---|---|---|
| サイズ | 大幅に小さく(100億パラメーター未満) | はるかに大きい(数千億または数兆のパラメーター) |
| トレーニングデータ | より小さく、フォーカスされたデータセット | 大規模で多様なデータセット |
| トレーニング時間 | 短い(週) | 長い(月) |
| リソース | 低い計算要件 | 高い計算要件 |
| タスクの習熟度 | 特殊なタスク | 汎用タスク |
| 推論 | エッジデバイスで実行できます | 通常、強力なGPUが必要です |
| 応答時間 | もっと早く | もっとゆっくり |
| 料金 | より低い | より高い |
SLMの構築:テクニックと例
このセクションでは、LLMSからSLMを作成するために使用される方法について詳しく説明します。
- 知識の蒸留:より小さな「学生」モデルは、より大きな「教師」モデルの出力から学習します。
- 剪定:より大きなモデルで、それほど重要でない接続またはニューロンを削除します。
- 量子化:モデルパラメーターの精度を減らし、メモリ要件を下げます。
この記事では、Llama 2、Microsoft Phi、Qwen 2、Gemma 2、およびMistral 7bなど、いくつかの最先端のSLMの詳細な比較を示し、独自の機能とパフォーマンスベンチマークを強調しています。

Google ColabでOllamaでSLMを実行します
実用的なガイドは、Google ColabでSLMSを実行してOllamaを使用してSLMを実行する方法を示しており、インストール、モデル選択、および迅速な実行のためのコードスニペットを提供します。この記事では、異なるモデルからの出力を紹介し、サンプルタスクでのパフォーマンスを直接比較できるようにします。
結論とFAQ
この記事は、SLMSの利点とさまざまなアプリケーションへの適合性を要約することで締めくくります。よくある質問セクションでは、SLM、知識の蒸留、剪定と量子化の違いに関する一般的なクエリに対処します。重要なポイントは、SLMが効率とパフォーマンスの間で達成するバランスを強調し、開発者と企業にとって貴重なツールになっています。
以上が小言語モデルのパフォーマンス評価の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。