



ディープラーニングGPUベンチマークは、画像認識から自然言語処理まで、複雑な問題を解決する方法に革命をもたらしました。ただし、これらのモデルのトレーニングはしばしば高性能GPUに依存しているが、限られたハードウェアを備えたエッジデバイスやシステムなどのリソース制約のある環境で効果的に展開することで、独自の課題が発生します。 CPUは、広く利用可能で費用効率が高いため、そのようなシナリオで推論のバックボーンとして機能します。しかし、CPUに展開されたモデルが精度を損なうことなく最適なパフォーマンスを提供することをどのように保証するのでしょうか?
この記事では、CPUのディープラーニングモデルの推論のベンチマークに分かれており、3つの重要なメトリックに焦点を当てています。スパム分類の例を使用して、Pytorch、Tensorflow、Jax、ONNXランタイムハンドルの推論ワークロードなどの人気のあるフレームワークをどのように検討します。最後に、パフォーマンスを測定し、展開を最適化し、リソース制約の環境でCPUベースの推論に適したツールとフレームワークを選択する方法を明確に理解することができます。
影響:最適な推論の実行は、かなりの金額を節約し、他のワークロードのリソースを解放することができます。
学習目標
- AIモデルトレーニングと推論のハードウェアパフォーマンスを評価する際の深い学習CPUベンチマークの役割を理解します。
- Pytorch、Tensorflow、Jax、ONNXランタイム、およびOpenVinoランタイムを評価して、ニーズに最適なものを選択します。
- 正確なパフォーマンスデータを収集し、推論を最適化するためのPsutilや時間などのマスターツール。
- モデルを準備し、推論を実行し、パフォーマンスを測定し、画像分類やNLPなどの多様なタスクに手法を適用します。
- リソースを効率的に管理しながら、ボトルネックを特定し、モデルを最適化し、パフォーマンスを向上させます。
この記事は、データサイエンスブログソンの一部として公開されました。
目次
- ランタイム加速により推論を最適化します
- モデル推論パフォーマンスメトリック
- 仮定と制限
- ツールとフレームワーク
- 依存関係をインストールします
- 問題ステートメントと入力仕様
- モデルアーキテクチャとフォーマット
- ベンチマークのための追加のネットワークの例
- ベンチマークワークフロー
- ベンチマーク関数Definiton
- モデル推論と各フレームワークのベンチマークを実行します
- 結果と考察
- 結論
- よくある質問
ランタイム加速により推論を最適化します
推論速度は、機械学習アプリケーションのユーザーエクスペリエンスと運用効率に不可欠です。ランタイム最適化は、実行を合理化することにより、これを強化する上で重要な役割を果たします。 ONNXランタイムのようなハードウェアアクセラル化ライブラリを使用すると、特定のアーキテクチャに合わせた最適化を利用して、遅延(推論あたりの時間)を削減します。
さらに、ONNXなどの軽量モデル形式はオーバーヘッドを最小限に抑え、より速いロードと実行を可能にします。最適化されたランタイムは、利用可能なCPUコア全体に計算を分配し、メモリ管理を改善するための並列処理を活用し、特にリソースが限られているシステムのパフォーマンスを向上させます。このアプローチは、精度を維持しながら、モデルをより速く、より効率的にします。
モデル推論パフォーマンスメトリック
モデルのパフォーマンスを評価するために、3つの重要なメトリックに焦点を当てます。
遅延
- 定義:レイテンシとは、入力を受信した後にモデルが予測を行うのにかかる時間を指します。これは、多くの場合、入力データの送信から出力の受信までの時間として測定されます(予測)
- 重要性:リアルタイムまたはほぼリアルタイムアプリケーションでは、高遅延が遅延につながり、応答が遅くなる可能性があります。
- 測定:レイテンシは通常、ミリ秒(MS)または秒単位で測定されます。レイテンシが短いことは、システムがより応答性が高く効率的であり、即時の意思決定またはアクションを必要とするアプリケーションにとって重要であることを意味します。
CPU利用
- 定義:CPU使用率は、推論タスクの実行中に消費されるCPUの処理能力の割合です。これは、モデルの推論中にシステムの計算リソースがどれだけ使用されているかを教えてくれます。
- 重要性:CPUの使用量が高いということは、マシンが他のタスクを同時に処理し、ボトルネックにつながるのに苦労する可能性があることを意味します。 CPUリソースを効率的に使用すると、モデルの推論がシステムリソースを独占しないようにします。
- 測定値:通常、利用可能なCPUリソースの合計の割合(%)として測定されます。同じワークロードの使用率が低いことは、一般に、CPUリソースをより効果的に利用するより最適化されたモデルを示しています。
メモリ利用
- 定義:メモリ利用とは、推論プロセス中にモデルが使用するRAMの量を指します。モデルのパラメーター、中間計算、および入力データによってメモリ消費を追跡します。
- 重要性:メモリの使用量を最適化することは、メモリが制限されているエッジデバイスまたはシステムにモデルを展開する場合に特に重要です。メモリ消費量が多いと、メモリオーバーフロエ、処理が遅くなるか、システムがクラッシュする可能性があります。
- 測定:メモリの利用は、メガバイト(MB)またはギガバイト(GB)の測定値です。推論のさまざまな段階でメモリ消費を追跡すると、メモリの非効率性またはメモリリークを特定するのに役立ちます。
仮定と制限
このベンチマーク研究を焦点を合わせて実用的に保つために、次の仮定を行い、いくつかの境界を設定しました。
- ハードウェアの制約:テストは、CPUコアが制限されている単一のマシンで実行するように設計されています。最新のハードウェアは並行したワークロードを処理できますが、このセットアップは、エッジデバイスまたは小規模な展開でよく見られる制約を反映しています。
- マルチシステムの並列化はありません:分散コンピューティングセットアップやクラスターベースのソリューションは組み込まれていません。ベンチマークは、CPUコアとメモリが限られているシングルノード環境に適したパフォーマンススタンドアロン条件を反映しています。
- 範囲:主な焦点は、CPU推論のパフォーマンスのみにあります。 GPUベースの推論はリソース集約型タスクの優れたオプションですが、このベンチマークは、コストに敏感またはポータブルアプリケーションでより一般的なCPUのみのセットアップに関する洞察を提供することを目的としています。
これらの仮定により、ベンチマークは、リソースに制約のあるハードウェアを扱う開発者とチーム、または分散システムの複雑さを追加せずに予測可能なパフォーマンスを必要とする人に関連することを保証します。
ツールとフレームワーク
CPUの深い学習モデルの推論をベンチマークして最適化するために使用される重要なツールとフレームワークを調査し、リソースに制約のある環境で効率的な実行の機能に関する洞察を提供します。
プロファイリングツール
- Python Time (Time Library) :PythonのTime Libraryは、コードブロックの実行時間を測定するための軽量ツールです。スタートとエンドのタイムスタンプを記録することにより、モデルの推論やデータ処理などの操作にかかった時間を計算するのに役立ちます。
- Psutil(CPU、メモリプロファイリング) : Psuti Lは、Sustemの監視とプロファイリングのためのPythonライブラリです。 CPUの使用、メモリ消費、ディスクI/Oなどに関するリアルタイムデータを提供し、モデルトレーニングまたは推論中の使用を分析するのに理想的です。
推論のためのフレームワーク
- Tensorflow :トレーニングと推論の両方のタスクの両方に広く使用されている深い学習のための堅牢なフレームワーク。さまざまなモデルと展開戦略を強力にサポートします。
- Pytorch:使いやすさと動的な計算グラフで知られるPytorchは、研究と生産の展開に人気のある選択肢です。
- ONNXランタイム:ONXX(オープンニューラルネットワーク交換)モデルを実行するためのオープンソースのクロスプラットフォームエンジンは、さまざまなハードウェアとフレームワークにわたって効率的な推論を提供します。
- JAX :高性能の数値コンピューティングと機械学習に焦点を当てた機能フレームワークは、自動分化とGPU/TPU加速を提供します。
- OpenVino:Intelハードウェア用に最適化されたOpenVinoは、Intel CPU、GPU、VPUでモデルの最適化と展開のためのツールを提供します。
ハードウェアの仕様と環境
以下の構成でGitHub CodeSpace(Virtual Machine)を利用しています。
- 仮想マシンの仕様: 2コア、8 GB RAM、32 GBストレージ
- Pythonバージョン: 3.12.1
依存関係をインストールします
使用されるパッケージのバージョンは次のとおりであり、このプライマリには5つの深い学習推論ライブラリが含まれます:Tensorflow、Pytorch、Onnx Runtime、Jax、およびOpenVino:
!ピップインストールnumpy == 1.26.4 !ピップインストールTORCH == 2.2.2 !ピップインストールtensorflow == 2.16.2 !pipインストールonnx == 1.17.0 !pipインストールonnxruntime == 1.17.0!pipインストールjax == 0.4.30 !ピップインストールjaxlib == 0.4.30 !PIPインストールOpenVino == 2024.6.0 !pipインストールmatplotlib == 3.9.3 !PIPインストールMATPLOTLIB:3.4.3 !ピップインストール枕:8.3.2 !ピップインストールPsutil:5.8.0
問題ステートメントと入力仕様
モデル推論は、ネットワークの重みと入力データの間でいくつかのマトリックス操作を実行することで構成されているため、モデルトレーニングやデータセットは必要ありません。この例では、ベンチマークプロセスでは、標準の分類ユースケースをシミュレートしました。これは、スパム検出やローン申請の決定(承認または拒否)などの一般的なバイナリ分類タスクをシミュレートします。これらの問題のバイナリ性は、異なるフレームワーク全体でモデルのパフォーマンスを比較するのに理想的です。このセットアップは実際のシステムを反映していますが、大きなデータセットや事前に訓練されたモデルを必要とせずに、フレームワーク全体の推論パフォーマンスに集中することができます。
問題ステートメント
サンプルタスクでは、一連の入力機能に基づいて、特定のサンプルがスパムであるかどうか(ローンの承認または拒否)であるかどうかを予測することが含まれます。このバイナリ分類の問題は計算上効率的であり、マルチクラス分類タスクの複雑さなしに推論パフォーマンスの集中的な分析を可能にします。
入力仕様
実際の電子メールデータをシミュレートするために、ランダムに入力を生成しました。これらの埋め込みは、スパムフィルターによって処理される可能性のあるデータのタイプを模倣しますが、外部データセットの必要性を回避します。このシミュレートされた入力データにより、特定の外部データセットに頼らずにベンチマークが可能になり、モデルの推論時間、メモリ使用量、CPUパフォーマンスのテストに最適です。または、画像分類、NLPタスク、またはその他の深い学習タスクを使用して、このベンチマークプロセスを実行することもできます。
モデルアーキテクチャとフォーマット
モデルの選択は、プロファイリングプロセスから得られた推論のパフォーマンスと洞察に直接影響するため、ベンチマークの重要なステップです。前のセクションで述べたように、このベンチマーク調査では、特定のメールがスパムであるかどうかを識別する標準的な分類ユースケースを選択しました。このタスクは、計算的に効率的であるが、フレームワーク全体の比較に意味のある結果を提供する簡単な2クラスの分類問題です。
ベンチマーク用のモデルアーキテクチャ
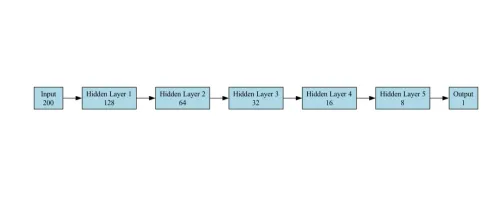
分類タスクのモデルは、バイナリ分類用に設計されたフィードフォワードニューラルネットワーク(FNN)です(スパム対スパムではない)。次のレイヤーで構成されています。
- 入力層:サイズ200のベクトル(埋め込み機能)を受け入れます。 Pytorchの例を提供しましたが、他のフレームワークはまったく同じネットワーク構成に従います
self.fc1 = torch.nn.linear(200,128)
- 隠されたレイヤー:ネットワークには5つの隠されたレイヤーがあり、それぞれの連続したレイヤーには以前のレイヤーよりも少ないユニットが含まれています。
self.fc2 = torch.nn.linear(128、64) self.fc3 = torch.nn.linear(64、32) self.fc4 = torch.nn.linear(32、16) self.fc5 = torch.nn.linear(16、8) self.fc6 = torch.nn.linear(8、1)
- 出力層:シグモイド活性化関数を備えた単一のニューロンは、確率を出力します(スパムではない場合は0、スパムの場合は1)。バイナリ分類のために最終出力としてシグモイド層を利用しました。
self.sigmoid = torch.nn.sigmoid()
モデルはシンプルですが、分類タスクに効果的です。
ユースケースでベンチマークに使用されるモデルアーキテクチャ図を以下に示します。
ベンチマークのための追加のネットワークの例
- 画像分類: ResNet-50(中程度の複雑さ)やMobileNet(軽量)などのモデルを、画像認識を含むタスクのベンチマークスイートに追加できます。 ResNet-50は、計算の複雑さと精度のバランスを提供しますが、MobileNetは低リソース環境に最適化されています。
- NLPタスク: Distilbert :自然言語の理解に適したBERTモデルのより小さく、より高速なバリアント。
モデル形式
- ネイティブ形式:各フレームワークは、Pytorch用の.ptやTensorflowの.h5などのネイティブモデル形式をサポートしています。
- Unified Format(onnx) :フレームワーク全体の互換性を確保するために、PytorchモデルをONNX形式(Model.onnx)にエクスポートしました。 ONNX(Open Neural Network Exchange)はブリッジとして機能し、Pytorch、Tensorflow、Jax、OpenVinoなどの他のフレームワークでモデルを使用できます。これは、相互運用性が重要なマルチフレームワークのテストと現実世界の展開シナリオに特に役立ちます。
- これらの形式は、それぞれのフレームワーク用に最適化されているため、これらのエコシステム内で簡単に保存、読み込み、展開できます。
ベンチマークワークフロー
このワークフローは、分類タスクを使用して、複数のディープ学習フレームワーク(Tensorflow、Pytorch、OnNX、Jax、およびOpenVino)の推論パフォーマンスを比較することを目的としています。タスクには、ランダムに生成された入力データを使用し、各フレームワークをベンチマークして、予測のために取られた平均時間を測定することが含まれます。
- Pythonパッケージをインポートします
- GPUの使用を無効にし、Tensorflowロギングを抑制します
- 入力データ準備
- 各フレームワークのモデル実装
- ベンチマーク関数定義
- 各フレームワークのモデル推論とベンチマーク実行
- ベンチマーク結果の視覚化とエクスポート
必要なPythonパッケージをインポートします
ベンチマークのディープラーニングモデルを始めるには、まず、シームレスな統合とパフォーマンス評価を可能にする必須のPythonパッケージをインポートする必要があります。
インポート時間 OSをインポートします npとしてnumpyをインポートします トーチをインポートします tfとしてtensorflowをインポートします Tensorflow.kerasからインポート入力から onnxruntimeをortとしてインポートします pltとしてmatplotlib.pyplotをインポートします PILインポート画像から psutilをインポートします Jaxをインポートします JAX.numpyをJNPとしてインポートします OpenVino.Runtime Import Coreから CSVをインポートします
GPUの使用を無効にし、Tensorflowロギングを抑制します
os.environ ["cuda_visible_devices"] = "-1"#disable gpu os.environ ["tf_cpp_min_log_level"] = "3" #suppress tensorflow log
入力データ準備
このステップでは、スパム分類の入力データをランダムに生成します。
- サンプルの寸法(200ダイムシオン機能)
- クラスの数(2:スパムかスパムではない)
numpyを使用してランドームデータを生成して、モデルの入力機能として機能します。
#Generateダミーデータ input_data = np.random.rand(1000、200).astype(np.float32)
モデル定義
このステップでは、NetWrokアーキテクチャを定義するか、各深い学習フレームワーク(Tensorflow、Pytorch、ONNX、Jax、OpenVino)からモデルをセットアップします。各フレームワークには、モデルをロードして推論のために設定するための特定の方法が必要です。
- Pytorchモデル:Pytorchでは、5つの完全に接続された層を持つ単純な神経ニューラルネットワークアーキテクチャを定義します。
- Tensorflowモデル: Tensorflowモデルは、Keras APIを使用して定義され、分類タスクの単純なFeedForwardニューラルネットワークで構成されています。
- JAXモデル:モデルはパラメーターで初期化され、予測関数はJaxのJust-in-Time(JIT)コンパイルを使用して効率的な実行を使用してコンパイルされます。
- ONNXモデル: ONNXの場合、Pytorchからモデルをエクスポートします。 ONNX形式にエクスポートした後、onnxRuntimeを使用してモデルをロードします。推論API。これにより、さまざまなハードウェア仕様にわたってモデルに推論を実行できます。
- OpenVinoモデル:OpenVinoは、最適化および展開モデル、特に他のフレームワーク(PytorchやTensorflowなど)を使用してトレーニングされたものを実行するために使用されます。 ONNXモデルをロードし、OpenVinoのランタイムでコンパイルします。
Pytorch
クラスpytorchmodel(torch.nn.module):
def __init __(self):
スーパー(pytorchmodel、self).__ init __()
self.fc1 = torch.nn.linear(200、128)
self.fc2 = torch.nn.linear(128、64)
self.fc3 = torch.nn.linear(64、32)
self.fc4 = torch.nn.linear(32、16)
self.fc5 = torch.nn.linear(16、8)
self.fc6 = torch.nn.linear(8、1)
self.sigmoid = torch.nn.sigmoid()
def worward(self、x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = torch.relu(self.fc4(x))
x = torch.relu(self.fc5(x))
x = self.sigmoid(self.fc6(x))
xを返します
#Pytorchモデルを作成します
pytorch_model = pytorchmodel()
Tensorflow
tensorflow_model = tf.keras.sequential([[
入力(shape =(200、))、
tf.keras.layers.dense(128、activation = 'lelu')、
tf.keras.layers.dense(64、activation = 'lelu')、
tf.keras.layers.dense(32、activation = 'lelu')、
tf.keras.layers.dense(16、activation = 'lelu')、
tf.keras.layers.dense(8、activation = 'lelu')、
tf.keras.layers.dense(1、activation = 'sigmoid')
]))
tensorflow_model.compile()
ジャックス
def jax_model(x):
x = jax.nn.relu(jnp.dot(x、jnp.ones(((200、128)))))
x = jax.nn.relu(jnp.dot(x、jnp.ones((128、64)))))
x = jax.nn.relu(jnp.dot(x、jnp.ones((64、32)))))
x = jax.nn.relu(jnp.dot(x、jnp.ones((32、16)))))
x = jax.nn.relu(jnp.dot(x、jnp.ones((16、8))))
x = jax.nn.sigmoid(jnp.dot(x、jnp.ones((8、1))))
xを返します
onnx
#PytorchモデルをONNXに変換します
dummy_input = torch.randn(1、200)
onnx_model_path = "model.onnx"
torch.onnx.export(
pytorch_model、
dummy_input、
onnx_model_path、
export_params = true、
opset_version = 11、
input_names = ['input']、
output_names = ['output']、
dynamic_axes = {'input':{0: 'batch_size'}、 'output':{0: 'batch_size'}}
))
onnx_session = ort.inferencessession(onnx_model_path)
OpenVino
#OpenVinoモデルの定義 core = core() openvino_model = core.read_model(model = "model.onnx") compiled_model = core.compile_model(openvino_model、device_name = "cpu")
ベンチマーク関数Definiton
この関数は、predict_function、input_data、およびnum_runsの3つの引数を実行することにより、さまざまなフレームワークにわたってベンチマークテストを実行します。デフォルトでは、1,000回実行されますが、要件に応じて増やすことができます。
def benchmark_model(predict_function、input_data、num_runs = 1000):
start_time = time.time()
process = psutil.process(os.getpid())
cpu_usage = []
memory_usage = []
_ in range(num_runs):
predict_function(input_data)
cpu_usage.append(process.cpu_percent())
memory_usage.append(process.memory_info()。rss)
end_time = time.time()
avg_latency =(end_time -start_time) / num_runs
avg_cpu = np.mean(cpu_usage)
avg_memory = np.mean(memory_usage) /(1024 * 1024)#mbに変換
return avg_latency、avg_cpu、avg_memory
モデル推論と各フレームワークのベンチマークを実行します
モデルを読み込んだので、各フレームワークのパフォーマンスをベンチマークする時が来ました。ベンチマークプロセスは、生成された入力データに推論を実行します。
Pytorch
#ベンチマークPytorchモデル
def pytorch_predict(input_data):
pytorch_model(torch.tensor(input_data))
pytorch_latency、pytorch_cpu、pytorch_memory = benchmark_model(lambda x:pytorch_predict(x)、input_data)
Tensorflow
#ベンチマークTensorflowモデル
def tensorflow_predict(input_data):
tensorflow_model(input_data)
tensorflow_latency、tensorflow_cpu、tensorflow_memory = benchmark_model(lambda x:tensorflow_predict(x)、input_data)
ジャックス
#ベンチマークJaxモデル
def jax_predict(input_data):
jax_model(jnp.array(input_data))
jax_latency、jax_cpu、jax_memory = benchmark_model(lambda x:jax_predict(x)、input_data)
onnx
#ベンチマークONNXモデル
def onnx_predict(input_data):
#バッチで入力を処理します
範囲のIの場合(input_data.shape [0]):
single_input = input_data [i:i 1]#単一入力を抽出します
onnx_session.run(none、{onnx_session.get_inputs()[0] .name:single_input})
onnx_latency、onnx_cpu、onnx_memory = benchmark_model(lambda x:onnx_predict(x)、input_data)
OpenVino
#ベンチマークOpenVinoモデル
def openvino_predict(input_data):
#バッチで入力を処理します
範囲のIの場合(input_data.shape [0]):
single_input = input_data [i:i 1]#単一入力を抽出します
compiled_model.infer_new_request({0:single_input})
OpenVino_Latency、OpenVino_CPU、OpenVino_Memory = benchmark_model(lambda x:openvino_predict(x)、input_data)
結果と考察
ここでは、前述のディープラーニングフレームワークのパフォーマンスベンチマークの結果について説明します。それらを比較します - レイテンシ、CPU使用、およびメモリ使用量。迅速な比較のために表のデータとプロットを含めました。
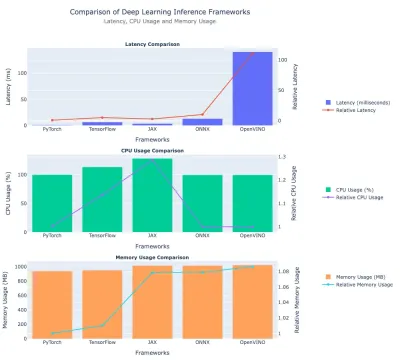
レイテンシー比較
| フレームワーク | レイテンシ(MS) | 相対的なレイテンシ(対pytorch) |
| Pytorch | 1.26 | 1.0(ベースライン) |
| Tensorflow | 6.61 | 〜5.25× |
| ジャックス | 3.15 | 〜2.50× |
| onnx | 14.75 | 〜11.72× |
| OpenVino | 144.84 | 〜115× |
洞察:
- Pytorchは、最速1.26ミリ秒のレイテンシを持つ最速のフレームワークとしてリードしています。
- Tensorflowのレイテンシは6.61ミリ秒、Pytorchの時間は約5.25×です。
- Jaxは、絶対的なレイテンシでPytorchとTensorflowの間に位置しています。
- ONNXも比較的遅く、 〜14.75ミリ秒です。
- OpenVinoは、この実験で最も遅い、約145ミリ秒(Pytorchよりも115×遅い)で。
CPUの使用
| フレームワーク | CPU使用(%) | 相対的なCPU使用 1 |
| Pytorch | 99.79 | 〜1.00 |
| Tensorflow | 112.26 | 〜1.13 |
| ジャックス | 130.03 | 〜1.31 |
| onnx | 99.58 | 〜1.00 |
| OpenVino | 99.32 | 1.00(ベースライン) |
洞察:
- Jaxは、最もCPU( 〜130% )を使用し、OpenVinoよりも〜31%高くなっています。
- Tensorflowは〜112%で、pytorch/onnx/openvinoを超えていますが、それでもJAXよりも低くなっています。
- Pytorch、onnx、およびopenvinoのすべてに、 〜99-100%のCPU使用量が類似しています。
メモリの使用
| フレームワーク | メモリ(MB) | 相対的なメモリ使用(対pytorch) |
| Pytorch | 〜959.69 | 1.0(ベースライン) |
| Tensorflow | 〜969.72 | 〜1.01× |
| ジャックス | 〜1033.63 | 〜1.08× |
| onnx | 〜1033.82 | 〜1.08× |
| OpenVino | 〜1040.80 | 〜1.08–1.09× |
洞察:
- PytorchとTensorflowは、約960-970 MB前後のメモリ使用量も同様です
- Jax、onnx、およびopenVinoは、約1,030〜1,040 MBのメモリを使用しており、Pytorchよりも約8〜9%多く使用されています。
ディープラーニングフレームワークのパフォーマンスを比較するプロットは次のとおりです。
結論
この記事では、スパム分類タスクを参照として使用する顕著なディープラーニングフレームワークの推論パフォーマンス(Tensorflow、Pytorch、ONNX、JAX、およびOpenVino)を評価するための包括的なベンチマークワークフローを提示しました。レイテンシ、CPUの使用量、メモリ消費などの主要なメトリックを分析することにより、結果は、フレームワークと異なる展開シナリオに対するそれらの適合性とのトレードオフを強調しました。
Pytorchは、低遅延と効率的なメモリ使用量で優れている最もバランスのとれたパフォーマンスを実証し、リアルタイムの予測や推奨システムなどの遅延に敏感なアプリケーションに最適です。 Tensorflowは、中程度のリソース消費量を伴う中央のソリューションを提供しました。 Jaxは高い計算スループットを紹介しましたが、CPU使用率の増加を犠牲にして、これはリソースに制約のある環境の制限要因である可能性があります。一方、ONNXとOpenVinoはレイテンシに遅れをとっており、OpenVinoのパフォーマンスはハードウェアアクセラレーションがないことで特に妨げられています。
これらの調査結果は、フレームワークの選択を展開ニーズに合わせることの重要性を強調しています。速度、リソースの効率、または特定のハードウェアを最適化するかどうかにかかわらず、トレードオフを理解することは、実際の環境での効果的なモデル展開に不可欠です。
キーテイクアウト
- ディープラーニングCPUベンチマークは、AIタスクの最適なハードウェアの選択を支援するCPUパフォーマンスに関する重要な洞察を提供します。
- 深い学習CPUベンチマークを活用すると、高性能CPUを識別することにより、効率的なモデルトレーニングと推論が保証されます。
- 最高の遅延(1.26ミリ秒)を達成し、リアルタイムおよびリソース制限されたアプリケーションに最適な効率的なメモリ使用量を維持しました。
- CPUの使用量がわずかに高いバランスレイテンシ(6.61ミリ秒)。中程度のパフォーマンスの妥協を必要とするタスクに適しています。
- 競争力のある待ち時間(3.15ミリ秒)を提供しましたが、過度のCPU使用率( 130% )を犠牲にして、制約付きセットアップでの有用性を制限しました。
- より高い遅延(14.75ミリ秒)を示しましたが、そのクロスプラットフォームサポートにより、マルチフレームワークの展開に柔軟になります。
よくある質問
Q1。リアルタイムアプリケーションにPytorchが好まれるのはなぜですか?A. Pytorchの動的計算グラフと効率的な実行パイプラインにより、低遅延の推論(1.26ミリ秒)が可能になり、推奨システムやリアルタイム予測などのアプリケーションに適しています。
Q2。この研究でOpenVinoのパフォーマンスに影響を与えたものは何ですか?A. OpenVinoの最適化は、Intelハードウェア用に設計されています。この加速がなければ、そのレイテンシ(144.84ミリ秒)とメモリ使用(1040.8 MB)は、他のフレームワークと比較して競争力が低くなりました。
Q3。リソースに制約のある環境のフレームワークを選択するにはどうすればよいですか?A. CPUのみのセットアップの場合、Pytorchが最も効率的です。 Tensorflowは、中程度のワークロードの強力な選択肢です。より高いCPU使用率が許容されない限り、JAXのようなフレームワークを避けてください。
Q4。フレームワークのパフォーマンスにおいて、ハードウェアはどのような役割を果たしますか?A.フレームワークのパフォーマンスは、ハードウェアの互換性に大きく依存します。たとえば、OpenVinoはハードウェア固有の最適化を備えたIntel CPUに優れていますが、PytorchとTensorflowはさまざまなセットアップ全体で一貫して機能します。
Q5。ベンチマークの結果は、複雑なモデルやタスクで異なる可能性がありますか?A.はい、これらの結果は単純なバイナリ分類タスクを反映しています。パフォーマンスは、ResNetなどの複雑なアーキテクチャやNLPなどのタスクなどで異なる場合があり、これらのフレームワークが専門的な最適化を活用する可能性があります。
この記事に示されているメディアは、Analytics Vidhyaが所有しておらず、著者の裁量で使用されています。
以上がディープラーニングCPUベンチマークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 ChatGPTが使えない!原因とすぐ試せる対処法を解説【2025年最新】May 14, 2025 am 05:04 AM
ChatGPTが使えない!原因とすぐ試せる対処法を解説【2025年最新】May 14, 2025 am 05:04 AMChatGptはアクセスできませんか?この記事では、さまざまな実用的なソリューションを提供しています!多くのユーザーは、ChatGPTを毎日使用する場合、アクセス不能や応答が遅いなどの問題に遭遇する可能性があります。この記事では、さまざまな状況に基づいてこれらの問題を段階的に解決するように導きます。 ChatGPTのアクセス不能性と予備的なトラブルシューティングの原因 まず、問題がOpenaiサーバー側にあるのか、ユーザー自身のネットワークまたはデバイスの問題にあるのかを判断する必要があります。 以下の手順に従って、トラブルシューティングしてください。 ステップ1:OpenAIの公式ステータスを確認してください OpenAIステータスページ(status.openai.com)にアクセスして、ChatGPTサービスが正常に実行されているかどうかを確認してください。赤または黄色のアラームが表示されている場合、それは開くことを意味します
 ASIのリスクを計算することは、人間の心から始まりますMay 14, 2025 am 05:02 AM
ASIのリスクを計算することは、人間の心から始まりますMay 14, 2025 am 05:02 AM2025年5月10日、MIT物理学者のMax Tegmarkは、AI Labsが人工的なスーパーインテリジェンスを解放する前にOppenheimerの三位一体計算をエミュレートすべきだとGuardianに語った。 「私の評価では、「コンプトン定数」、競争が
 ChatGPTで作詞・作曲する方法とおすすめツールをわかりやすく解説May 14, 2025 am 05:01 AM
ChatGPTで作詞・作曲する方法とおすすめツールをわかりやすく解説May 14, 2025 am 05:01 AMAI Music Creation Technologyは、1日ごとに変化しています。この記事では、ChatGPTなどのAIモデルを例として使用して、AIを使用して音楽の作成を支援し、実際のケースで説明する方法を詳細に説明します。 Sunoai、Hugging Face、PythonのMusic21 Libraryを通じて音楽を作成する方法を紹介します。 これらのテクノロジーを使用すると、誰もがオリジナルの音楽を簡単に作成できます。ただし、AIに生成されたコンテンツの著作権問題は無視できないことに注意する必要があります。使用する際には注意する必要があります。 音楽分野でのAIの無限の可能性を一緒に探りましょう! Openaiの最新のAIエージェント「Openai Deep Research」が紹介します。 [chatgpt] ope
 ChatGPT-4とは?できることや料金、GPT-3.5との違いを徹底解説!May 14, 2025 am 05:00 AM
ChatGPT-4とは?できることや料金、GPT-3.5との違いを徹底解説!May 14, 2025 am 05:00 AMChATGPT-4の出現により、AIアプリケーションの可能性が大幅に拡大しました。 GPT-3.5と比較して、CHATGPT-4は大幅に改善されました。強力なコンテキスト理解能力を備えており、画像を認識して生成することもできます。普遍的なAIアシスタントです。それは、ビジネス効率の改善や創造の支援など、多くの分野で大きな可能性を示しています。ただし、同時に、その使用における予防策にも注意を払わなければなりません。 この記事では、ChATGPT-4の特性を詳細に説明し、さまざまなシナリオの効果的な使用方法を紹介します。この記事には、最新のAIテクノロジーを最大限に活用するためのスキルが含まれています。参照してください。 Openaiの最新のAIエージェント、「Openai Deep Research」の詳細については、以下のリンクをクリックしてください
 ChatGPTのアプリの使い方を解説!日本語対応で音声会話機能もMay 14, 2025 am 04:59 AM
ChatGPTのアプリの使い方を解説!日本語対応で音声会話機能もMay 14, 2025 am 04:59 AMChatGPTアプリ:AIアシスタントで創造性を解き放つ!初心者向けガイド ChatGPTアプリは、文章作成、翻訳、質問応答など、多様なタスクに対応する革新的なAIアシスタントです。創作活動や情報収集にも役立つ、無限の可能性を秘めたツールです。 この記事では、ChatGPTスマホアプリのインストール方法から、音声入力機能やプラグインといったアプリならではの機能、そしてアプリ利用上の注意点まで、初心者にも分かりやすく解説します。プラグインの制限やデバイス間の設定同期についてもしっかりと触れていきま
 ChatGPTの中文版の利用方法は?登録手順や料金について解説May 14, 2025 am 04:56 AM
ChatGPTの中文版の利用方法は?登録手順や料金について解説May 14, 2025 am 04:56 AMChatgpt中国語版:中国語のAIの対話の新しい体験のロックを解除する ChatGptは世界中で人気がありますが、中国語版も提供していることをご存知ですか?この強力なAIツールは、毎日の会話をサポートするだけでなく、プロのコンテンツを処理し、簡素化された伝統的な中国語と互換性があります。中国のユーザーであろうと、中国語を学んでいる友人であろうと、あなたはそれから利益を得ることができます。 この記事では、アカウント設定、中国語の迅速な単語入力、フィルターの使用、さまざまなパッケージの選択を含むChatGpt中国語のバージョンの使用方法を詳細に紹介し、潜在的なリスクと対応戦略を分析します。さらに、ChatGpt中国語版を他の中国のAIツールと比較して、その利点とアプリケーションシナリオをよりよく理解するのに役立ちます。 Openaiの最新のAIインテリジェンス
 5 AIエージェントの神話あなたは今信じるのをやめる必要がありますMay 14, 2025 am 04:54 AM
5 AIエージェントの神話あなたは今信じるのをやめる必要がありますMay 14, 2025 am 04:54 AMこれらは、生成AIの分野で次の飛躍と考えることができ、ChatGptやその他の大規模なモデルのチャットボットを提供しました。単に質問に答えたり情報を生成したりするのではなく、彼らは私たちに代わって行動を起こすことができます。
 ChatGPTで複数アカウントを作成・管理する不法をわかりやすく解説May 14, 2025 am 04:50 AM
ChatGPTで複数アカウントを作成・管理する不法をわかりやすく解説May 14, 2025 am 04:50 AMChatGPTを活用した効率的な複数アカウント管理術|ビジネスとプライベートの使い分けも徹底解説! 様々な場面で活用されているChatGPTですが、複数アカウントの管理に頭を悩ませている方もいるのではないでしょうか。この記事では、ChatGPTの複数アカウント作成方法、利用上の注意点、そして安全かつ効率的な運用方法を詳しく解説します。ビジネス利用とプライベート利用の使い分け、OpenAIの利用規約遵守といった重要な点にも触れ、複数アカウントを安全に活用するためのガイドを提供します。 OpenAI


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

WebStorm Mac版
便利なJavaScript開発ツール

