



検索された生成(RAG)は、情報検索を組み込むことにより、大規模な言語モデル(LLM)を強化します。これにより、LLMは外部の知識ベースにアクセスできるようになり、より正確で最新の、および文脈的に適切な応答が得られます。高度なぼろきれの手法である是正ぼろきれ(CRAG)は、取得された文書の自己反省と自己評価メカニズムを導入することにより、精度をさらに強化します。
主要な学習目標
この記事では:
- CRAGのコアメカニズムとWeb検索との統合。
- バイナリスコアリングとクエリの書き換えを使用したCRAGのドキュメント関連評価。
- 岩山と伝統的なぼろきれの重要な区別。
- Python、Langchain、およびTavilyを使用した実践的なクラッグの実装。
- 検索と応答の精度を最適化するために、評価者、クエリライター、およびWeb検索ツールを構成する実用的なスキル。
Data Science Blogathonの一部として公開されています。
目次
- クラッグの根本的なメカニズム
- クラッグ対伝統的なぼろきれ
- 実用的な岩山の実装
- クラッグの課題
- 結論
- よくある質問
クラッグの根本的なメカニズム
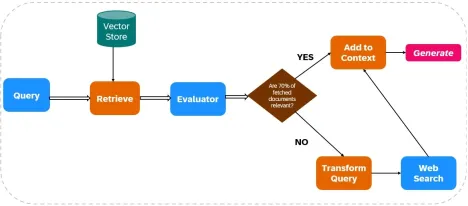
CRAGは、Web検索を検索プロセスと生成プロセスに統合することにより、LLM出力の信頼性を高めます(図1を参照)。
ドキュメント取得:
- データの摂取:関連するデータはインデックス化されており、Web検索ツール(Tavily AIなど)がリアルタイムデータ取得のために構成されています。
- 初期検索:ユーザーのクエリに基づいて、ドキュメントは静的な知識ベースから取得されます。
関連性評価:
評価者は、取得されたドキュメントの関連性を評価します。文書の70%以上が無関係であるとみなされる場合、是正措置が開始されます。それ以外の場合、応答生成が進行します。
Web検索統合:
ドキュメントの関連性が不十分な場合、CragはWeb検索を使用します。
- クエリの改良:元のクエリは、Web検索結果を最適化するように変更されています。
- Web検索の実行: Tavily AIなどのツールは追加データを取得し、現在および多様な情報へのアクセスを保証します。
応答生成:
CRAGは、初期検索とWeb検索の両方からのデータを合成して、コヒーレントで正確な応答を作成します。
クラッグ対伝統的なぼろきれ
CRAGは、検証なしで検索されたドキュメントに依存している従来のぼろとは異なり、取得した情報を積極的に検証および改良します。 CRAGは、多くの場合、リアルタイムのWeb検索を組み込んでおり、静的な知識ベースへの従来のRagの依存とは異なり、最新情報へのアクセスを提供します。これにより、高精度とリアルタイムのデータ統合が必要なアプリケーションにCragが理想的になります。
実用的な岩山の実装
このセクションでは、Python、Langchain、およびTavilyを使用した岩山の実装について詳しく説明しています。
ステップ1:ライブラリのインストール
必要なライブラリをインストールする:
!ピップインストールTiktoken Langchain-Openai Langchainhub Chromadb Langchain Langgraph tavily-python !PIPインストール-QuPypdf langchain_community
ステップ2:APIキー構成
APIキーを設定します:
OSをインポートします os.environ ["tavily_api_key"] = "" os.environ ["openai_api_key"] = ""
ステップ3:ライブラリの輸入
必要なライブラリをインポートします(Brevityのために省略されていますが、元の例と同様)。
ステップ4:チャンクおよびレトリーバーの作成を文書化します
(Brevityのためにコードは省略されていますが、PYPDFLOADER、recursIveCharacterTextSplitter、OpenAiemBedings、およびChromaを使用して、元の例と同様)。
ステップ5:ラグチェーンのセットアップ
(Brevityのためにコードは省略されていますが、元の例と同様に、 hub.pull("rlm/rag-prompt")およびChatOpenAI使用しています)。
ステップ6:評価者のセットアップ
(Brevityのためにコードは省略されていますが、元の例と同様に、 Evaluatorクラスを定義し、評価のためにChatOpenAI使用しています)。
ステップ7:クエリライターのセットアップ
(Brevityのためにコードは省略されていますが、元の例と同様に、 ChatOpenAIを使用してクエリの書き換えに)。
ステップ8:Web検索セットアップ
langchain_community.tools.tools.tavily_search Import tavilysearchresultsから web_search_tool = tavilysearchresults(k = 3)
ステップ9-12:ランググラフワークフローのセットアップと実行
(Brevityのために省略されたコードですが、概念的には元の例と類似して、 GraphState 、Function Nodes( retrieve 、 generate 、 evaluate_documents 、 transform_query 、 web_search )を定義し、 StateGraphを使用して接続します。)従来のRAGとの最終出力と比較も概念的に似ています。
クラッグの課題
Cragの有効性は、評価者の精度に大きく依存します。弱い評価者はエラーを導入できます。スケーラビリティと適応性も懸念事項であり、継続的な更新とトレーニングが必要です。 Web検索統合は、偏った情報または信頼できない情報のリスクを導入し、堅牢なフィルタリングメカニズムを必要とします。
結論
クラッグにより、LLM出力の精度と信頼性が大幅に向上します。リアルタイムのWebデータで取得した情報を評価および補足する能力により、高精度と最新の情報を要求するアプリケーションにとって価値があります。ただし、評価者の精度とWebデータの信頼性に関連する課題に対処するには、継続的な改良が重要です。
キーテイクアウト(オリジナルに似ていますが、簡潔さのために言い換えられます)
- CRAGは、現在の関連情報のWeb検索を使用してLLM応答を強化します。
- その評価者は、応答生成のための高品質の情報を保証します。
- クエリ変換は、Web検索結果を最適化します。
- RAGとは異なり、RAGはリアルタイムのWebデータを動的に統合します。
- クラッグは情報を積極的に検証し、エラーを減らします。
- CRAGは、高精度とリアルタイムデータを必要とするアプリケーションに有益です。
よくある質問(オリジナルに似ていますが、簡潔さのために言い換えられます)
- Q1:岩山とは何ですか? A:正確性と信頼性の向上のためにWeb検索を統合する高度なRAGフレームワーク。
- Q2:クラッグ対伝統的なぼろきれ? A:CRAGは、取得した情報を積極的に検証および改良します。
- Q3:評価者の役割? A:ドキュメントの関連性の評価と修正のトリガー。
- Q4:文書が不十分ですか? A:Web検索付きのCrag Supplements。
- Q5:信頼できないWebコンテンツの処理? A:高度なフィルタリング方法が必要です。
(注:画像は変更されておらず、元の入力のように含まれています。)
以上が動作中の是正布(岩石)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 生成エンジン最適化に関するビジネスリーダーのガイド(GEO)May 03, 2025 am 11:14 AM
生成エンジン最適化に関するビジネスリーダーのガイド(GEO)May 03, 2025 am 11:14 AMGoogleはこのシフトをリードしています。その「AIの概要」機能はすでに10億人以上のユーザーにサービスを提供しており、誰もがリンクをクリックする前に完全な回答を提供しています。[^2] 他のプレイヤーも速く地位を獲得しています。 ChatGpt、Microsoft Copilot、およびPE
 このスタートアップは、AIエージェントを使用して悪意のある広告となりすましアカウントと戦っていますMay 03, 2025 am 11:13 AM
このスタートアップは、AIエージェントを使用して悪意のある広告となりすましアカウントと戦っていますMay 03, 2025 am 11:13 AM2022年、彼はソーシャルエンジニアリング防衛のスタートアップDoppelを設立してまさにそれを行いました。そして、サイバー犯罪者が攻撃をターボチャージするためのより高度なAIモデルをハーネスするにつれて、DoppelのAIシステムは、企業が大規模に戦うのに役立ちました。
 世界モデルがどのように生成AIとLLMの未来を根本的に再形成しているかMay 03, 2025 am 11:12 AM
世界モデルがどのように生成AIとLLMの未来を根本的に再形成しているかMay 03, 2025 am 11:12 AM出来上がりは、適切な世界モデルとの対話を介して、生成AIとLLMを実質的に後押しすることができます。 それについて話しましょう。 革新的なAIブレークスルーのこの分析は、最新のAIで進行中のForbes列のカバレッジの一部であり、
 2050年5月:私たちは祝うために何を残しましたか?May 03, 2025 am 11:11 AM
2050年5月:私たちは祝うために何を残しましたか?May 03, 2025 am 11:11 AM労働者2050年。全国の公園は、ノスタルジックなパレードが街の通りを通り抜ける一方で、伝統的なバーベキューを楽しんでいる家族でいっぱいです。しかし、お祝いは現在、博物館のような品質を持っています。
 あなたが聞いたことがないディープフェイク検出器はそれが98%正確ですMay 03, 2025 am 11:10 AM
あなたが聞いたことがないディープフェイク検出器はそれが98%正確ですMay 03, 2025 am 11:10 AMこの緊急かつ不安な傾向に対処するために、TEM Journalの2025年2月版の査読済みの記事は、その技術のディープフェイクが現在存在する場所に関する最も明確でデータ駆動型の評価の1つを提供します。 研究者
 Quantum Talent Wars:The Hidden Crisis Treatenting Tech'の次のフロンティアMay 03, 2025 am 11:09 AM
Quantum Talent Wars:The Hidden Crisis Treatenting Tech'の次のフロンティアMay 03, 2025 am 11:09 AM新薬を策定するのにかかる時間を大幅に短縮することから、より環境に優しいエネルギーを生み出すまで、企業が新境地を破る大きな機会があります。 しかし、大きな問題があります:スキルを持っている人々が深刻な不足があります
 プロトタイプ:これらの細菌は電気を生成できますMay 03, 2025 am 11:08 AM
プロトタイプ:これらの細菌は電気を生成できますMay 03, 2025 am 11:08 AM数年前、科学者は、特定の種類のバクテリアが酸素を摂取するのではなく、電気を生成することで呼吸するように見えることを発見しましたが、どのようにしたのかは謎でした。 Journal Cellに掲載された新しい研究は、これがどのように起こるかを特定しています:微生物
 AIとサイバーセキュリティ:新政権の100日間の計算May 03, 2025 am 11:07 AM
AIとサイバーセキュリティ:新政権の100日間の計算May 03, 2025 am 11:07 AM今週のRSAC 2025会議で、SNYKは「The First 100 Days:How AI、Policy&Cybersecurity Collide」というタイトルのタイムリーなパネルを開催しました。ニコール・ペルロス、元ジャーナリストとパートネ


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール
ホットトピック
 7938
7938 15165214141252130325125029
15165214141252130325125029