


Jina Embeddings v2:革命の長い文書のテキスト埋め込み
BERTなどの現在のテキスト埋め込みモデルは、512トークンの処理制限によって制約され、長いドキュメントでパフォーマンスを妨げます。 この制限は、多くの場合、コンテキストの損失と不正確な理解につながります。 Jina Embeddings V2は、最大8192トークンまでのシーケンスをサポートし、重要なコンテキストを維持し、広範なテキスト内で処理された情報の精度と関連性を大幅に改善することにより、この制限を上回ります。これは、複雑なテキストデータの処理における大きな進歩を表しています。キー学習ポイント
長いドキュメントを処理するときのBertのような伝統的なモデルの制限を理解してください。
- Jina Embeddings v2が8192トークンの容量と高度なアーキテクチャを通じてこれらの制限を克服する方法を学ぶ。
- Alibi、Glu、およびその3段階のトレーニング方法を含むJina Embeddings V2の革新的な機能の調査。 法的研究、コンテンツ管理、および生成AIにおける現実世界のアプリケーションの発見。
- Jina Embeddings v2を抱きしめてフェイスライブラリを使用してプロジェクトに統合する実践的な経験を積む。
- この記事は、データサイエンスブログの一部です
- 目次
長い文書を埋め込むことの課題 建築革新とトレーニング方法
パフォーマンス評価実際のアプリケーション
モデルの比較- 顔を抱きしめてジナ埋め込みv2を使用します
- 結論
- よくある質問
- 長い文書を埋め込むことの課題
- 長いドキュメントの処理は、自然言語処理(NLP)に大きな課題を提示します。従来の方法セグメントでテキストを処理し、コンテキストの切り捨てと断片化された埋め込みにつながり、元のドキュメントを誤って伝えます。これは次のとおりです
- 計算需要の増加
- メモリ消費量が多い
テキストの包括的な理解を必要とするタスクでのパフォーマンスの低下
Jina Embeddings v2は、トークンの制限を8192
に増やし、過度のセグメンテーションの必要性を排除し、ドキュメントのセマンティックの完全性を維持することにより、これらの問題に直接対処します。- 建築的革新とトレーニング方法
- Jina Embeddings v2は、最先端のイノベーションでBertの能力を高めます:
-
-
線形バイアス(Alibi)を使用した
- 注意:Alibiは、従来の位置埋め込みを注意スコアに適用される線形バイアスに置き換えます。これにより、モデルは、トレーニング中に遭遇したものよりもはるかに長いシーケンスにモデルを効果的に外挿することができます。 以前の単方向実装とは異なり、Jina Embeddings V2は双方向のバリアントを使用して、エンコードタスクとの互換性を確保します。
- ゲート線形ユニット(GLU):GLUは、変圧器の効率を改善することで知られていますが、フィードフォワードレイヤーで使用されています。 GegluやRegluなどのバリアントは、モデルサイズに基づいてパフォーマンスを最適化するために採用されています。 最適化されたトレーニング:
- Jina Embeddings v2は3段階のトレーニングプロセスを採用しています:
- 事前削除:
- マスクされた言語モデリング(MLM)を使用して、巨大なクリーンクロールコーパス(c4)で訓練されています。 テキストペアを使用した微調整:
- 意味的に類似したテキストペアの埋め込みを調整します。 ハードネガティブな微調整: 挑戦的なディストラクタの例を組み込むことでランキングと検索を改善します。
- メモリ効率の高いトレーニング:混合精度トレーニングやアクティベーションチェックポイントなどのテクニックは、より大きなバッチサイズのスケーラビリティを確保します。
m
 パフォーマンス評価
パフォーマンス評価Jina Embeddings v2は、大規模なテキスト埋め込みベンチマーク(MTEB)や新しいロングドキュメントデータセットなど、さまざまなベンチマークで最先端のパフォーマンスを実現します。 重要な結果は次のとおりです
分類:Amazonの極性や有毒な会話分類などのタスクの最大の精度。>
クラスタリング:関連するテキストのグループ化の競合他社(PatentClustering and WikicitiesClustering)を上回る。
- 検索:
- 完全なドキュメントコンテキストが重要な項目qaのようなタスクで優れています。 長いドキュメントの処理: 8192トークンシーケンスでもMLMの精度を維持します。
- このチャートは、シーケンスの長さがさまざまな検索タスクとクラスタリングタスク全体の埋め込みモデルのパフォーマンスを比較します。
- 法律および学術研究:法的文書や学術論文の検索と分析に最適です。
- コンテンツ管理システム:大規模なドキュメントリポジトリの効率的なタグ付け、クラスタリング、および取得。>
- 生成ai:AI生成された要約とプロンプトベースのモデルを強化します e-commerce:
- 製品検索および推奨システムを改善します モデルの比較
実世界のアプリケーション
Jina Embeddings v2は、長いシーケンスの処理だけでなく、OpenaiのText-dembedding-aad-002などの独自モデルとの競合にも優れています。 そのオープンソースの性質により、アクセシビリティが保証されます
hugging hugging faceでジナ埋め込みv2を使用してくださいステップ1:インストール
ステップ2:変圧器でジナ埋め込みを使用
!pip install transformers !pip install -U sentence-transformers
output:
import torch from transformers import AutoModel from numpy.linalg import norm cos_sim = lambda a, b: (a @ b.T) / (norm(a) * norm(b)) model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True) embeddings = model.encode(['How is the weather today?', 'What is the current weather like today?']) print(cos_sim(embeddings, embeddings))長いシーケンスの取り扱い:
ステップ3:Jina Embeddingsを使用して文を変換する(
embeddings = model.encode(['Very long ... document'], max_length=2048)
ライブラリを使用した同様のコードが提供されており、設定の指示。)。)
sentence_transformersmax_seq_length結論Jina Embeddings v2は、NLPの大幅な進歩であり、長いドキュメントの処理の制限に効果的に対処しています。 その機能は、既存のワークフローを改善し、長い形式のテキストを操作するための新しい可能性のロックを解除します。
キーテイクアウェイ(元の結論からキーポイントを要約)
よくある質問
(FAQへの要約された回答)
注:画像は元の形式と場所で保持されています。
 パフォーマンス評価
パフォーマンス評価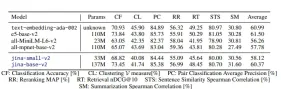
 Jina Embeddings v2は、NLPの大幅な進歩であり、長いドキュメントの処理の制限に効果的に対処しています。 その機能は、既存のワークフローを改善し、長い形式のテキストを操作するための新しい可能性のロックを解除します。
Jina Embeddings v2は、NLPの大幅な進歩であり、長いドキュメントの処理の制限に効果的に対処しています。 その機能は、既存のワークフローを改善し、長い形式のテキストを操作するための新しい可能性のロックを解除します。
以上がJina Embeddings V2:長いドキュメントの処理が簡単になりましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 個人的なハッキングはかなり激しいクマになりますMay 11, 2025 am 11:09 AM
個人的なハッキングはかなり激しいクマになりますMay 11, 2025 am 11:09 AMサイバー攻撃が進化しています。 一般的なフィッシングメールの時代は終わりました。 サイバー犯罪の将来は超個人化されており、高度にターゲットを絞った攻撃を作成するために、容易に利用可能なオンラインデータとAIを活用しています。 あなたの仕事を知っている詐欺師を想像してください、あなたのf
 教皇レオXIVは、AIが彼の名前の選択にどのように影響したかを明らかにしますMay 11, 2025 am 11:07 AM
教皇レオXIVは、AIが彼の名前の選択にどのように影響したかを明らかにしますMay 11, 2025 am 11:07 AM枢機of大学への彼の就任演説では、シカゴ生まれのロバート・フランシス・プレボスト、新たに選出された教皇レオ14世は、彼の同名の教皇レオXIIIの影響について議論しました。
 初心者および専門家向けのFastapi -MCPチュートリアル-Analytics VidhyaMay 11, 2025 am 10:56 AM
初心者および専門家向けのFastapi -MCPチュートリアル-Analytics VidhyaMay 11, 2025 am 10:56 AMこのチュートリアルでは、モデルコンテキストプロトコル(MCP)とFastAPIを使用して、大規模な言語モデル(LLM)と外部ツールを統合する方法を示しています。 FastAPIを使用して簡単なWebアプリケーションを構築し、それをMCPサーバーに変換し、Lを有効にします
 DIA-1.6B TTS:最高のテキストからダイアログの生成モデル - 分析VidhyaMay 11, 2025 am 10:27 AM
DIA-1.6B TTS:最高のテキストからダイアログの生成モデル - 分析VidhyaMay 11, 2025 am 10:27 AMDIA-1.6Bを探索:資金がゼロの2人の学部生によって開発された画期的なテキストからスピーチモデル! この16億個のパラメーターモデルは、笑い声やくしゃみなどの非言語的手がかりを含む、非常に現実的なスピーチを生成します。この記事ガイド
 AIがメンターシップをこれまで以上に意味のあるものにする3つの方法May 10, 2025 am 11:17 AM
AIがメンターシップをこれまで以上に意味のあるものにする3つの方法May 10, 2025 am 11:17 AM私は心から同意します。 私の成功は、メンターの指導に密接に関連しています。 特にビジネス管理に関する彼らの洞察は、私の信念と実践の基盤を形成しました。 この経験は、メンターへの私のコミットメントを強調しています
 AIは、鉱業で新しい可能性を発掘しますMay 10, 2025 am 11:16 AM
AIは、鉱業で新しい可能性を発掘しますMay 10, 2025 am 11:16 AMAIはマイニング機器を強化しました 採掘操作環境は厳しく危険です。人工知能システムは、最も危険な環境から人間を排除し、人間の能力を高めることにより、全体的な効率とセキュリティを改善するのに役立ちます。人工知能は、マイニング操作で使用される自動運転トラック、ドリル、ローダーの電源にますます使用されています。 これらのAI搭載車両は、危険な環境で正確に動作し、それにより安全性と生産性が向上します。一部の企業は、大規模な鉱業作業のために自動鉱業車両を開発しています。 挑戦的な環境で動作する機器には、継続的なメンテナンスが必要です。ただし、メンテナンスは重要なデバイスをオフラインに保ち、リソースを消費する可能性があります。より正確なメンテナンスとは、高価で必要な機器の稼働時間が増加し、大幅なコスト削減を意味します。 AI駆動型
 AIエージェントが25年で最大の職場革命を引き起こす理由May 10, 2025 am 11:15 AM
AIエージェントが25年で最大の職場革命を引き起こす理由May 10, 2025 am 11:15 AMSalesforceのCEOであるMarc Benioffは、AIエージェントが推進する記念碑的な職場革命、Salesforceとその顧客ベース内ですでに進行中の変革を予測しています。 彼は、従来の市場から、に焦点を当てた非常に大きな市場への移行を想定しています
 ai hrは、aiの養子縁組が舞い上がるので私たちの世界を揺るがそうとしていますMay 10, 2025 am 11:14 AM
ai hrは、aiの養子縁組が舞い上がるので私たちの世界を揺るがそうとしていますMay 10, 2025 am 11:14 AMHRでのAIの台頭:ロボットの同僚との労働力をナビゲートする AIと人事(HR)への統合は、もはや未来の概念ではありません。急速に新しい現実になりつつあります。 このシフトは、人事の専門家と従業員の両方のDEMに影響を与えます


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

WebStorm Mac版
便利なJavaScript開発ツール

