



AI言語モデルの進化は、特にコーディングおよびプログラミングの状況で新しい標準を設定しています。充電をリードするのは、deepseek-v3、gpt-4o、およびllama 3.3 70bです。それぞれが独自の利点を提供します。このブログでは、AI言語モデルの比較を行い、GPT-4oのアーキテクチャ、パラメーター、コーディング機能、およびその2つの選択肢の実用的なケースに焦点を当てます。 DeepSeek-V3対GPT-4O対LlAMA 3.3 70Bの詳細な分析により、どのモデルがプログラミングタスクに最適か、これらの進歩が2025年にAIの未来をどのように形成しているかを明らかにします。 目次
- モデルのアーキテクチャと設計
- deepseek-v3
- gpt-4o
- llama 3.3評価
2。価格の比較- 3。ベンチマークの比較
- 比較洞察
- deepseek-v3対gpt-4o vs llama 3.3 70b:コーディング機能
タスク1:多数の要因- 結論
deepseek-v3
deepseek-V3は、6710億パラメーターを備えたオープンソースの混合物(MOE)モデルであり、トークンあたり370億パラメーターをアクティブにします。最先端の負荷分散とマルチトークン予測方法を活用し、14.8兆トークンで訓練されています。複数のベンチマークにわたる最高層のパフォーマンスを実現するモデルは、わずか2.788百万H800 GPU時間のコストでトレーニング効率を維持しています。
DeepSeek-V3には、DeepSeek-R1 Liteの推論能力が組み込まれており、128Kコンテキストウィンドウを提供しています。さらに、テキスト、構造化されたデータ、複雑なマルチモーダル入力など、さまざまな入力タイプを処理でき、多様なユースケースに汎用性が高くなります。 また読む:deepseek-v3を使用したAIアプリケーションの構築 gpt-4o
GPT-4Oは、OpenAIが開発した高度な言語モデルで、最先端の建築改善を特徴としています。入力トークンの膨大なデータセットでトレーニングされているため、さまざまなタスクで非常に有能になり、印象的な正確さがあります。
このモデルはマルチモーダル入力をサポートし、推論能力を高め、多数のアプリケーションに汎用性を提供します。コンテキストウィンドウの128Kトークンを使用すると、リクエストごとに最大16,384個のトークンを生成し、1秒あたり約77.4トークンを処理できます。 2024年8月にリリースされたその知識は2023年10月まで延長され、市場で最も強力で適応性のあるモデルの1つになりました。
llama 3.3 70bメタ
llama3.3 70 b多言語大手言語モデル(LLM)は、700億パラメーターを備えたオープンソース、事前に訓練された命令チューニングされた生成モデルです。効率とスケーラビリティのために最適化されるように設計されています。 15兆以上のトークンで訓練された、幅広いタスクを処理するために最先端のテクニックを採用しています。 llama 3.3 70bは、最適化された変圧器アーキテクチャを使用する自動再帰言語モデルです。このモデルは、いくつかのベンチマークで顕著なパフォーマンスを実現し、最適化されたリソース割り当てでトレーニングコストを最小限に抑えます。
llama 3.3 70bは、幅広いコンテキストウィンドウをサポートし、微妙で正確なタスク処理のための高度な推論機能を組み込みます。テキストベースの入力を処理するように設計されていますが、構造化されたデータを処理することもでき、さまざまなアプリケーションで柔軟性を提供します。deepseek-v3 vs gpt-4o vs llama 3.3 70b:モデル評価
1。モデルの概要
2。価格の比較
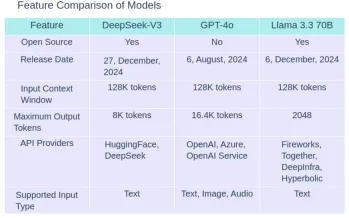
3。ベンチマーク比較
| Benchmark | Description | DeepSeek-V3 | GPT-4o | Llama 3.3 70B |
| MMLU | Massive Multitask Language Understanding- Test knowledge across 57 subjects including maths, history, law and more | 88.5% | 88.7% | 88.5% |
| MMLU-Pro | A more robust MMLU benchmark with more complex reasoning focused questions and reduced prompt sensitivity | 75.9% | 74.68% | 75.9% |
| MMMU | Massive Multitask Multimodal Understanding: Text understanding across text, audio,images and videos | Not available | 69.1% | Not available |
| HellaSwag | A challenging sentence completion benchmark | 88.9% | Not available | Not available |
| HumanEval | Evaluates code generation and problem solving capabilities | 82.6% | 90.2% | 88.4% |
| MATH | Tests Mathematical problem solving abilities across various difficulty levels | 61.6% | 75.9% | 77% |
| GPQA | Test PhD-level knowledge in physics, chemistry and biology that require domain expertise | 59.1% | 53.6% | 50.5% |
| IFEval | Test model’s ability to accurately follow explicit formatting instructions, generate appropriate outputs and maintain consistent instructions | 86.1% | Not available | 92.1% |
ここで個々のベンチマークテストの結果を見つけることができます:
- gpt-4o:https://github.com/openai/simple-evals?tab = readme-ov-file#benchmark-result
- llama 3.3 70b:https://build.nvidia.com/meta/llama-3_3-70b-instruct/modelcard
- deepseek-v3:https://github.com/deepseek-ai/deepseek-v3
比較洞察
価格について言えば、GPT-4Oは、入力トークンと出力トークンのDeepSeek-V3に比べて約30倍高価です。一方、Llama 3.3 70bの指示は、入力トークンと出力トークンのDeepSeek-V3に比べて約1.5倍高価です。
DeepSeek-V3は、MMLU(大規模なマルチタスク言語の理解)やHumanval(コード生成)など、構造化されたタスク完了を必要とするベンチマークで優れています。ただし、数学(数学的な問題解決)などのベンチマークの課題に直面しており、そのパフォーマンスは競争力がありません。また、GPQA(一般化されたパッセージ質問応答)でリードし、このドメインの他のモデルを上回る。 gpt-4oは、HumanevalとMMLUで特にうまく機能し、さまざまなトピックで高品質の応答を生成する能力で際立っています。推論に基づいたタスクに輝いていますが、他のモデルのパフォーマンスが向上した数学やGPQAなどの専門分野で苦労しています。 llama 3.3 70bは、数学やイベールなどのベンチマークの強みを示しています(評価後の命令)。それは優れた問題解決能力を示し、他のモデルよりも複雑な指示をより効果的に追跡します。 HumanvalやGPQAなどの他のベンチマークでのパフォーマンスは、DeepSeek-V3やGPT-4Oよりも印象的ではありません。 deepseek-v3 vs gpt-4o vs llama 3.3 70b:コーディング機能
ここで、DeepSeek-V3、GPT-4O、およびLlama 3.3 70bのコード作成機能を比較します。そのために、3つのモデルすべてに同じプロンプトを提供し、以下のメトリックでの回答を評価します。
効率
読みやすさ
- コメントとドキュメント
- エラー処理
- タスク1:多数の要因を見つける
- プロンプト:
「こんにちは、あなたは優れたコードインストラクターなので、この質問を手伝ってください。多数の要因を見つけるためのPythonコードを書いてください。 GPT-4O
による応答
アレイを使用して多数の因子を計算する(手動で乗算を処理し、運用をキャリーするため)、Pythonの実装を次に示します。
生成されたコードの出力
による応答
これは、アレイを使用して数字を保存するために多数の要因を計算するPythonコードスニペットです。def multiply(arr, x):
"""
Multiplies an array representation of a number with an integer x.
: param arr: List of integers representing the digits of the number.
: param x: Integer to multiply with.
:return: Updated array with the result.
"""
carry = 0 # Initialize carry
for i in range(len(arr)):
prod = arr[i] * x + carry
arr[i] = prod % 10 # Store last digit of the product in the array
carry = prod // 10 # Update the carry
# Process carry, add digits to the array
while carry > 0:
arr.append(carry % 10)
carry //= 10
return arr
def factorial_large_number_array(n):
"""
Calculate the factorial of a large number using array representation.
: param n: Integer for which the factorial is to be computed.
:return: Factorial of n as a string.
"""
if n
生成されたコードの出力<h4></h4>
<p> <img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/000/174148243891998.jpg?x-oss-process=image/resize,p_40" class="lazy" alt="deepseek-v3 vs gpt-4o vs llama 3.3 70b:最高のAIモデルを見つける" ></p>
Deepseek-V3 <h4 id="による">による</h4>応答
<p><em>Pythonの配列を使用して多数の因子係数を計算するには、結果を標準データ型の制限を超える非常に多数を処理するアレイ(またはリスト)に保存できます。実装する方法は次のとおりです
</em>
生成されたコードの出力</p><pre class="brush:php;toolbar:false">def multiply(x, res, res_size):
"""Multiplies x with the number represented by res[]"""
carry = 0
for i in range(res_size):
prod = res[i] * x + carry
res[i] = prod % 10
carry = prod // 10
while carry:
res.append(carry % 10)
carry = carry // 10
def factorial(n):
""" Calculates the factorial of a number n"""
res = [1]
res_size = 1
for i in range(2, n + 1):
multiply(i, res, res_size)
res_size = len(res)
return res
def print_factorial(n):
""" Prints the factorial of a number n"""
res = factorial(n)
print("Factorial of", n, "is:")
for digit in reversed(res):
print(digit, end="")
# Example usage:
n = 55
print_factorial(n)
 比較結果
比較結果
GPT-4Oの応答は、最も完全でバランスの取れた効率、読みやすさ、堅牢なエラー処理です。詳細なコメントと明確な変数名が含まれており、無効な入力を優雅に処理し、実用的または共同開発に適しています。
llama 3.3 70bの応答は機能的ですが、適切なエラー処理と詳細なドキュメントがありません。その構造は直感的ではなく、冗長変数を使用すると効率に影響します。これにより、3つの中で最も弱くなりますDeepSeek-V3の応答は効率的できれいに構造化されていますが、堅牢なエラー処理と十分なドキュメントがありません。それは強い候補ですが、人々が簡単に従うか適応するのが明確に不足しています。
推奨事項:
実際の使用の場合:
gpt-4oは、その堅牢なエラー処理、明確なドキュメント、および強力な読みやすさのために最良の選択です。- 教育目的:gpt-4oは、その応答の詳細な文書とコメントのために再び好ましいオプションになります。 タスク2:文字列がpalindrome
- であるかどうかを確認します プロンプト:
による
応答この問題を解決するために、2ポインターアプローチを使用して、最大1文字で削除した後、文字列がパリンドロームになることができるかどうかを確認できます。これがPythonの実装
生成されたコードの出力
Llama 3.3 70b
による応答 ここに、文字列が最大1文字で削除された後、文字列がパリンドロームになることができるかどうかをチェックするPythonソリューションです。
生成されたコードの出力def factorial(n):
# Initialize the result as a list with 1
result = [1]
# Multiply the result list with numbers from 2 to n
for x in range(2, n + 1):
carry = 0
# Multiply each digit in the result list with x
for i in range(len(result)):
product = result[i] * x + carry
result[i] = product % 10 # Store the last digit
carry = product // 10 # Carry over the remaining digits
# Add the remaining carry to the result list
while carry > 0:
result.append(carry % 10)
carry = carry // 10
# Reverse the result list to get the correct order
result.reverse()
return result
# Input: Number to find factorial of
n = int(input("Enter a number: "))
# Compute factorial
factorial_result = factorial(n)
# Convert the list of digits to a string for display
factorial_str = ''.join(map(str, factorial_result))
# Output the result
print(f"Factorial of {n} is: {factorial_str}")
 Deepseek-V3
Deepseek-V3
による
応答この問題を解決するには、最大1文字で削除することで文字列がパリンドロームになることができるかどうかを確認する必要があります。パリンドロームは、同じ前方と後方を読み取ります。これにアプローチする方法は次のとおりです 生成されたコードの出力
def multiply(arr, x):
"""
Multiplies an array representation of a number with an integer x.
: param arr: List of integers representing the digits of the number.
: param x: Integer to multiply with.
:return: Updated array with the result.
"""
carry = 0 # Initialize carry
for i in range(len(arr)):
prod = arr[i] * x + carry
arr[i] = prod % 10 # Store last digit of the product in the array
carry = prod // 10 # Update the carry
# Process carry, add digits to the array
while carry > 0:
arr.append(carry % 10)
carry //= 10
return arr
def factorial_large_number_array(n):
"""
Calculate the factorial of a large number using array representation.
: param n: Integer for which the factorial is to be computed.
:return: Factorial of n as a string.
"""
if n
<h4> </h4><p>
<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/000/174148245021735.jpg?x-oss-process=image/resize,p_40" class="lazy" alt="deepseek-v3 vs gpt-4o vs llama 3.3 70b:最高のAIモデルを見つける" >比較洞察</p>
<h4>GPT-4Oの応答は、最も完全で十分に文書化されています。それは明確にコア機能を処理するため、将来の開発者がコードを変更または拡張できるようにすることができます。効率と明確なドキュメントの組み合わせにより、生産環境に最適です。
</h4>llama 3.3 70bの応答は機能的なソリューションですが、GPT-4oで見つかった明確な変数の命名と詳細なドキュメントがありません。メインロジック内にコメントがないため、従うのが難しくなり、読みやすさの点で改善の余地があります。ただし、迅速な実装が優先事項である小さなタスクには十分に効率的です。<p>
</p>Deepseek-V3の応答は、効率とシンプルさのバランスが整っていますが、ドキュメントでは不足しています。それは簡潔で迅速ですが、他の人がコードを簡単にフォローするのに十分な詳細がありません。そのアプローチは、時間とリソースが制限されているシナリオで有益ですが、コードの制作を可能にするために、より徹底的な説明とエラー処理が必要です。
<p>推奨事項:</p>
<p>
</p><h4 id="実際の使用の場合">実際の使用の場合:</h4>GPT-4O応答は、その徹底的なドキュメント、明確な構造、および読みやすさのために最適です。
- 教育目的で:GPT-4Oは最も適切であり、プロセスの各ステップについて包括的な洞察を提供します。 結論
- GPT-4oは、効率、明確さ、エラー管理、および包括的なドキュメントの観点から、Llama 3.3 70bとDeepseek-V3の両方を上回ります。これにより、実用的なアプリケーションと教育目的の両方に最大の選択肢になります。 llama 3.3 70bとdeepseek-v3は機能的ですが、堅牢なエラー処理と明確なドキュメントがないため、不足しています。適切なエラー管理を追加し、可変命名を改善し、詳細なコメントを含めることで、GPT-4oの標準に合わせて使いやすさが向上します。
読み取り:
- deepseek r1 vs openai o1:どちらが良いですか?
- deepseek r1 vs openai o1 vs sonnet 3.5
- 中国の巨人の対決:deepseek-v3 vs qwen2.5
- deepseek v3 vs claude sonnet 3.5
- deepseek v3 vs gpt-4o
よくある質問
q1。どのモデルが実際のアプリケーションに最高のコード品質を提供しますか? GPT-4Oは、効率的なエラー処理、明確なドキュメント、およびよく組織化されたコード構造により、実際のコーディングに優れており、実用的な使用に最適です。これらのモデルは、コードの読みやすさと理解の容易さの観点からどのように比較されますか? GPT-4oは読みやすさで際立っており、明確な変数名と徹底的なコメントを提供します。それに比べて、llama 3.3 70bとdeepseek-v3は機能的ですが、同じレベルの明確さとドキュメントが欠けているため、従うのが難しくなります。どのモデルが教育目的に最も適していますか? GPT-4Oは教育に理想的な選択肢であり、詳細な文書と、学習者がコードの根底にあるロジックを把握するのに役立つ詳細な説明を提供します。 GPT-4Oの品質に合わせてDeepSeek-V3およびLlama 3.3 70bを強化するために、どのような手順を実行できますか?パフォーマンスを向上させるには、両方のモデルが堅牢なエラー処理の実装、より記述的な変数名を使用し、読みやすさと全体的なユーザビリティを改善するための詳細なコメントとドキュメントを追加することに焦点を当てる必要があります。以上がdeepseek-v3 vs gpt-4o vs llama 3.3 70b:最高のAIモデルを見つけるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 摩擦から流れへ:AIがどのように法的作業を変えているかMay 09, 2025 am 11:29 AM
摩擦から流れへ:AIがどのように法的作業を変えているかMay 09, 2025 am 11:29 AM法的技術革命は勢いを増し、法律専門家にAIソリューションを積極的に受け入れるように促しています。 受動的抵抗は、競争力を維持することを目指している人にとってはもはや実行可能な選択肢ではありません。 なぜテクノロジーの採用が重要なのですか? 法律専門家
 これはAIがあなたのことを考えており、あなたについて知っていることですMay 09, 2025 am 11:24 AM
これはAIがあなたのことを考えており、あなたについて知っていることですMay 09, 2025 am 11:24 AM多くの人は、AIとの相互作用が匿名であると仮定しており、人間のコミュニケーションとはまったく対照的です。 ただし、AIはすべてのチャット中にユーザーを積極的にプロファイルします。 すべてのプロンプト、すべての単語が分析および分類されます。 AI Revoのこの重要な側面を探りましょう
 繁栄した、AIの準備ができている企業文化を構築するための7つのステップMay 09, 2025 am 11:23 AM
繁栄した、AIの準備ができている企業文化を構築するための7つのステップMay 09, 2025 am 11:23 AM成功した人工知能戦略は、強力な企業文化サポートから分離することはできません。 Peter Druckerが言ったように、事業運営は人々に依存しており、人工知能の成功も依存しています。 人工知能を積極的に受け入れる組織の場合、AIに適応する企業文化を構築することが重要であり、AI戦略の成功または失敗さえ決定します。 ウェストモンローは最近、繁栄するAIに優しい企業文化を構築するための実用的なガイドをリリースしました。ここにいくつかの重要なポイントがあります。 1. AIの成功モデルを明確にする:まず第一に、AIがどのようにビジネスに力を与えることができるかについての明確なビジョンが必要です。理想的なAI操作文化は、人間とAIシステム間の作業プロセスの自然統合を実現できます。 AIは特定のタスクが得意であり、人間は創造性と判断が得意です
 Netflix New Scroll、Meta AI&#x27;のゲームチェンジャー、Neuralinkは85億ドルで評価されていますMay 09, 2025 am 11:22 AM
Netflix New Scroll、Meta AI&#x27;のゲームチェンジャー、Neuralinkは85億ドルで評価されていますMay 09, 2025 am 11:22 AMメタはAIアシスタントアプリケーションをアップグレードし、ウェアラブルAIの時代が来ています! ChatGPTと競合するように設計されたこのアプリは、テキスト、音声インタラクション、画像生成、Web検索などの標準的なAI機能を提供しますが、初めてジオロケーション機能を追加しました。これは、メタAIがあなたがどこにいるのか、あなたがあなたの質問に答えるときにあなたが何を見ているのかを知っていることを意味します。興味、場所、プロファイル、アクティビティ情報を使用して、これまで不可能な最新の状況情報を提供します。このアプリはリアルタイム翻訳もサポートしており、レイバンメガネのAIエクスペリエンスを完全に変更し、その有用性を大幅に改善しました。 外国映画への関税の賦課は、メディアや文化に対する裸の力の行使です。実装された場合、これはAIと仮想生産に向かって加速します
 AIサイバー犯罪から身を守るために、今日これらの手順を踏んでくださいMay 09, 2025 am 11:19 AM
AIサイバー犯罪から身を守るために、今日これらの手順を踏んでくださいMay 09, 2025 am 11:19 AM人工知能は、サイバー犯罪の分野に革命をもたらし、新しい防御スキルを学ぶことを強いています。サイバー犯罪者は、ディープフォーファリーやインテリジェントなサイバー攻撃などの強力な人工知能技術を、前例のない規模で詐欺と破壊に使用しています。過去1年間、グローバルビジネスの87%がAIサイバー犯罪の標的を絞っていると報告されています。 それでは、どうすればこの賢い犯罪の波の犠牲者になることを避けることができますか?リスクを特定し、個人および組織レベルで保護対策を講じる方法を探りましょう。 サイバー犯罪者が人工知能をどのように使用するか 技術が進むにつれて、犯罪者は、個人、企業、政府を攻撃する新しい方法を常に探しています。人工知能の広範な使用は最新の側面かもしれませんが、その潜在的な害は前例のないものです。 特に、人工知能
 共生ダンス:人工的および自然な知覚のナビゲートループMay 09, 2025 am 11:13 AM
共生ダンス:人工的および自然な知覚のナビゲートループMay 09, 2025 am 11:13 AM人工知能(AI)と人間の知能(NI)の複雑な関係は、フィードバックループとして最もよく理解されています。 人間はAIを作成し、人間の活動によって生成されたデータでそれをトレーニングして、人間の能力を強化または複製します。 このai
 AIの最大の秘密 - クリエイターはそれを理解していません、専門家は分裂しますMay 09, 2025 am 11:09 AM
AIの最大の秘密 - クリエイターはそれを理解していません、専門家は分裂しますMay 09, 2025 am 11:09 AM人類の最近の声明は、最先端のAIモデルを取り巻く理解の欠如を強調しており、専門家の間で激しい議論を引き起こしました。 この不透明度は本物の技術的危機ですか、それとも単により多くのソフへの道の一時的なハードルですか
 Sarvam AIによるBulbul-V2:インドの最高のTTSモデルMay 09, 2025 am 10:52 AM
Sarvam AIによるBulbul-V2:インドの最高のTTSモデルMay 09, 2025 am 10:52 AMインドは、言語の豊かなタペストリーを備えた多様な国であり、地域間のシームレスなコミュニケーションを持続的な課題にしています。ただし、SarvamのBulbul-V2は、高度なテキストからスピーチ(TTS)Tでこのギャップを埋めるのに役立ちます。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

