


画像分類のための抱きしめの顔を利用する:包括的なガイド
AIと機械学習の礎石である画像分類は、顔の認識から医療イメージングまで、多様な分野全体のアプリケーションを見つけます。 抱きしめる顔は、特に自然言語処理(NLP)やますますコンピュータービジョンに精通している人にとって、このタスクの強力なプラットフォームとして浮上しています。このガイドの詳細は、イメージ分類のためのハグ顔を使用して、初心者と経験豊富な開業医の両方に対応しています。
画像の分類を理解し、顔の利点を抱き締める画像分類には、視覚コンテンツを分析し、学習パターンに基づいてカテゴリを予測するアルゴリズムを使用して、画像を事前定義されたクラスに分類することが含まれます。 畳み込みニューラルネットワーク(CNNS)は、パターン認識能力のために標準的なアプローチです。 CNNSへのより深い潜水については、記事「畳み込みニューラルネットワーク(CNNS)の紹介」を参照してください。 「機械学習の分類:はじめに」記事は、分類アルゴリズムのより広い理解を提供します。
hugging顔がいくつかの利点を提供します:
画像分類に顔を抱き締めることの重要な利点
アクセシビリティ:
直感的なAPIと包括的なドキュメントは、すべてのスキルレベルに対応しています。- 事前に訓練されたモデル:事前に訓練されたモデルの膨大なリポジトリにより、カスタムデータセットで効率的な微調整を可能にし、トレーニング時間と計算リソースを最小限に抑えます。 ユーザーは、独自のモデルをトレーニングおよび展開できます コミュニティ&サポート:
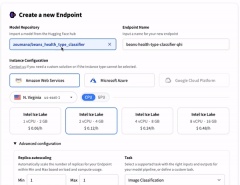
- 活気のあるコミュニティは、貴重なサポートとトラブルシューティング支援を提供します。 フェイスのハグは、さまざまな推論オプションを使用して、主要なクラウドプラットフォーム(AWS、Azure、Googleクラウドプラットフォーム)全体でモデルの展開を簡素化します。
- クラウドプラットフォーム全体のモデルデプロイメントオプション データの準備と前処理
このガイドでは、デモンストレーションのために抱きしめる顔の「豆」データセットを使用しています。 読み込み後、前処理前にデータを視覚化します。 付随するGoogle Colabノートブックは、コードを提供します。 このコードは、Faceの公式ドキュメントを抱き締めることに触発されています
 ライブラリの要件:
ライブラリの要件:
PIPを使用して必要なライブラリをインストールします:
インストール後にカーネルを再起動します。 必要なライブラリをインポート:データの読み込みと編成:
データセットをロードします:
pip -q install datasets pip -q install transformers=='4.29.0' pip -q install tensorflow=='2.15' pip -q install evaluate pip -q install --upgrade accelerate
データセットには1034の画像が含まれており、それぞれに「Image_file_path」、「Image」(PIL Object)、および「ラベル」(0:Angular_Leaf_spot、1:Bean_rust、2:Healthy)が含まれています。
ヘルパー関数はランダムイメージを視覚化します:
import torch import torchvision import numpy as np import evaluate from datasets import load_dataset from huggingface_hub import notebook_login from torchvision import datasets, transforms from torch.utils.data import DataLoader from transformers import DefaultDataCollator from transformers import AutoImageProcessor from torchvision.transforms import RandomResizedCrop, Compose, Normalize, ToTensor from transformers import AutoModelForImageClassification, TrainingArguments, Trainer import matplotlib.pyplot as plt6つのランダムイメージを視覚化します:
beans_train = load_dataset("beans", split="train") 
豆のデータセットからのサンプル画像
データ前処理:
データセットを分割します(80%列車、20%の検証):
labels_names = {0: "angular_leaf_spot", 1: "bean_rust", 2: "healthy"}
def display_random_images(dataset, num_images=4):
# ... (function code as in original input) ...作成ラベルマッピングの作成:
display_random_images(beans_train, num_images=6)モデルの読み込みと微調整
事前に訓練されたVITモデルをロードします:
beans_train = beans_train.train_test_split(test_size=0.2)コードは、事前に訓練されたモデルをロードし、変換(サイズ変更、正規化)を定義し、トレーニング用のデータセットを準備します。 精度メトリックは、評価のために定義されています
顔を抱き締めるためにログイン:
(画面上の指示に従ってください)
labels = beans_train["train"].features["labels"].names label2id, id2label = dict(), dict() for i, label in enumerate(labels): label2id[label] = str(i) id2label[str(i)] = label
トレーニングを設定して開始する:
(元の入力に示されているトレーニング結果)
checkpoint = "google/vit-base-patch16-224-in21k" image_processor = AutoImageProcessor.from_pretrained(checkpoint) # ... (rest of the preprocessing code as in original input) ...
モデルの展開と統合
訓練されたモデルを抱きしめている顔のハブに押します:
モデルにアクセスして使用できます
notebook_login()フェイスポータルの抱きしめ:
- 予測のために画像を直接アップロードします。
- トランスフォーマーライブラリ: Pythonコード内のモデルを使用します
- REST API:予測に提供されたAPIエンドポイントを利用します。 APIを使用した例:
- 結論とさらなるリソース
training_args = TrainingArguments(
# ... (training arguments as in original input) ...
)
trainer = Trainer(
# ... (trainer configuration as in original input) ...
)
trainer.train()
「トランスフォーマーの使用と顔を抱き締めるための紹介」
「Pythonによる画像処理」スキルトラック
- 「画像認識とは何ですか?」記事
- このガイドは、すべてのレベルのユーザーが、画像分類プロジェクトのハグの顔を活用できるようにします。
以上が顔の画像分類を抱き締める:例を備えた包括的なガイドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 カリフォルニアは、AIをタップして、速い追跡の山火事回復許可を促進しますMay 04, 2025 am 11:10 AM
カリフォルニアは、AIをタップして、速い追跡の山火事回復許可を促進しますMay 04, 2025 am 11:10 AMAIは、野火の回復許可を合理化します オーストラリアのハイテク企業ArchistarのAIソフトウェアは、機械学習とコンピュータービジョンを利用して、地域の規制に準拠するための建築計画の評価を自動化します。この前検証は重要です
 米国がエストニアのAI駆動型デジタル政府から学ぶことができることMay 04, 2025 am 11:09 AM
米国がエストニアのAI駆動型デジタル政府から学ぶことができることMay 04, 2025 am 11:09 AMエストニアのデジタル政府:米国のモデル? 米国は官僚的な非効率性と闘っていますが、エストニアは説得力のある代替品を提供しています。 この小さな国は、AIを搭載した、ほぼ100%デジタル化された市民中心の政府を誇っています。 これはそうではありません
 生成AIによる結婚式の計画May 04, 2025 am 11:08 AM
生成AIによる結婚式の計画May 04, 2025 am 11:08 AM結婚式を計画することは記念碑的な仕事であり、しばしば最も組織化されたカップルでさえ圧倒されます。 この記事は、AIの影響に関する進行中のフォーブスシリーズの一部(こちらのリンクを参照)で、生成AIが結婚式の計画にどのように革命をもたらすことができるかを調べます。 結婚式のpl
 デジタル防衛AIエージェントとは何ですか?May 04, 2025 am 11:07 AM
デジタル防衛AIエージェントとは何ですか?May 04, 2025 am 11:07 AM政府は、さまざまな確立されたタスクにそれらを利用している一方で、企業はAIエージェントを販売のためにますます活用しています。 ただし、消費者の支持者は、個人がターゲットのターゲットに対する防御として自分のAIエージェントを所有する必要性を強調しています
 生成エンジン最適化に関するビジネスリーダーのガイド(GEO)May 03, 2025 am 11:14 AM
生成エンジン最適化に関するビジネスリーダーのガイド(GEO)May 03, 2025 am 11:14 AMGoogleはこのシフトをリードしています。その「AIの概要」機能はすでに10億人以上のユーザーにサービスを提供しており、誰もがリンクをクリックする前に完全な回答を提供しています。[^2] 他のプレイヤーも速く地位を獲得しています。 ChatGpt、Microsoft Copilot、およびPE
 このスタートアップは、AIエージェントを使用して悪意のある広告となりすましアカウントと戦っていますMay 03, 2025 am 11:13 AM
このスタートアップは、AIエージェントを使用して悪意のある広告となりすましアカウントと戦っていますMay 03, 2025 am 11:13 AM2022年、彼はソーシャルエンジニアリング防衛のスタートアップDoppelを設立してまさにそれを行いました。そして、サイバー犯罪者が攻撃をターボチャージするためのより高度なAIモデルをハーネスするにつれて、DoppelのAIシステムは、企業が大規模に戦うのに役立ちました。
 世界モデルがどのように生成AIとLLMの未来を根本的に再形成しているかMay 03, 2025 am 11:12 AM
世界モデルがどのように生成AIとLLMの未来を根本的に再形成しているかMay 03, 2025 am 11:12 AM出来上がりは、適切な世界モデルとの対話を介して、生成AIとLLMを実質的に後押しすることができます。 それについて話しましょう。 革新的なAIブレークスルーのこの分析は、最新のAIで進行中のForbes列のカバレッジの一部であり、
 2050年5月:私たちは祝うために何を残しましたか?May 03, 2025 am 11:11 AM
2050年5月:私たちは祝うために何を残しましたか?May 03, 2025 am 11:11 AM労働者2050年。全国の公園は、ノスタルジックなパレードが街の通りを通り抜ける一方で、伝統的なバーベキューを楽しんでいる家族でいっぱいです。しかし、お祝いは現在、博物館のような品質を持っています。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

ドリームウィーバー CS6
ビジュアル Web 開発ツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

