
ホームページ >テクノロジー周辺機器 >AI >LLM RAG:AI搭載ファイルリーダーアシスタントの作成
LLM RAG:AI搭載ファイルリーダーアシスタントの作成

- Linda Hamiltonオリジナル
- 2025-03-04 10:40:11510ブラウズ
はじめに
aiはどこにでもあります。
少なくとも1日に1回、大きな言語モデル(LLM)とやり取りしないことは困難です。チャットボットはここにとどまります。彼らはあなたのアプリにいます、彼らはあなたがより良く書くのを助け、彼らは電子メールを作成し、彼らは電子メールを読みます...まあ、彼らはたくさんします。
そして、それは悪いとは思わない。実際、私の意見は逆です - 少なくともこれまでのところ。私は日常生活でAIを使用することを擁護し、擁護しています。なぜなら、同意して、それがすべてをより簡単にするからです。句読点やタイプを見つけるためにドキュメントを二重読みにするのに時間を費やす必要はありません。 aiは私のためにそれをします。毎週月曜日にそのフォローアップメールを書くのに時間を無駄にしません。 aiは私のためにそれをします。主なポイントとアクションポイントを要約するためにAIを持っているとき、私は巨大で退屈な契約を読む必要はありません!
これらは、AIの素晴らしい用途のほんの一部にすぎません。 LLMSのより多くのユースケースを知りたい場合は、私たちの生活を楽にしたい場合は、それらについての本全体を書きました。今、データサイエンティストとして考え、技術的な側面を見て、すべてがそれほど明るく光沢があるわけではありません。
llmsは、誰またはあらゆる会社に適用されるいくつかの一般的なユースケースに最適です。たとえば、トレーニングのカットオフ日まで作成された一般的なコンテンツに関する質問、要約、または回答。ただし、特定のビジネスアプリケーションに関しては、単一の目的、またはカットオフ日を作成しなかった新しいもの、つまり、of-of-box
- つまり、回答を知りません。したがって、調整が必要になります。LLMモデルのトレーニングには数ヶ月と数百万ドルかかることがあります。さらに悪いことに、モデルを調整して目的に合わせない場合、不十分な結果や幻覚があります(クエリを考慮してモデルの応答が意味をなさない場合)。 では、解決策は何ですか?私たちのデータを含めるためにモデルを再訓練する多数のお金を費やしますか?
そうではありません。それは、検索された高等世代(RAG)が有用になるときです。
RAGは、外部の知識ベースから情報を大規模な言語モデル(LLM)と組み合わせたフレームワークです。 AIモデルがより正確で関連性のある応答を生成するのに役立ちます。
次のRagの詳細をご覧くださいrag?
とは何ですか概念を説明するための物語を教えてください。
私は映画が大好きです。しばらくの間、私はどの映画がオスカーや最高の俳優や女優で最高の映画カテゴリーを競っているかを知っていました。そして、私は確かにその年の像を手に入れたものを確かに知っているでしょう。しかし今、私はその主題についてすべてさびています。誰が競争しているのかと尋ねたら、私は知りません。そして、私があなたに答えようとしたとしても、私はあなたに弱い反応を与えるでしょう。 では、質の高い対応を提供するために、私は他の誰もがしていることをします:オンラインで情報を検索し、それを取得してから、それをあなたに与えます。私がちょうどしたことは、ぼろと同じアイデアです。外部データベースからデータを取得して答えを出しました。
コンテンツストアでLLMを強化した場合、データを取得し、ラグは、モデルが知識を強化し、より正確に対応できるコンテンツストアを作成するようなものです。
検索アルゴリズムを使用して、データベース、知識ベース、Webページなどの外部データソースを照会します。
処理された情報をLLMに組み込みます。 RAGは、LLMSが内部組織データなどの追加の知識ベースにアクセスするのに役立ちます ragは、LLMがより正確なドメイン固有のコンテンツを作成するのに役立ちます より良い理解のために手順を分解しましょう: LLMのために、ちょうど見たように、いくつかのステップを踏みます。それでは、ファイルをロードしてテキストチャンクに分割できる関数を作成して、効率的な検索を行うことから始めましょう。
次に、retrienlidアプリの構築を開始し、次のスクリプトでその機能を使用します。
Pythonで必要なモジュールのインポートを開始します。それらのほとんどは、Langchainパッケージから来ています
この最初のコードスニペットは、アプリタイトルを作成し、ファイルアップロード用のボックスを作成し、load_document()関数に追加するファイルを準備します。
マシンはテキストよりも数字をよく理解しているため、最終的には、クエリを実行するときに比較して類似性を確認できる数字のデータベースをモデルに提供する必要があります。この次のコードでは、埋め込みがvector_dbを作成するのに役立ちます。
次に、vector_dbでナビゲートするレトリーバーオブジェクトを作成します。
先に進むと、RAGフレームワークのコアを作成し、Retriverオブジェクトとプロンプトを一緒に貼り付けます。このオブジェクトは、データソース(ベクトルデータベースなど)から関連するドキュメントを追加し、LLMを使用して処理して応答を生成する準備ができています。
あなたが行く前に 拡張されています。
1なりユーザークエリ 2️⃣ →知識ベース(データベース、ベクターストアなど)を検索します。
3かコンテキストの増強
4法応答を生成 githubリポジトリ
https://github.com/gurezende/basic-rag 私について
このコンテンツが気に入っていて、私の仕事についてもっと知りたい場合は、ここに私のウェブサイトがあります。ここでは、すべての連絡先も見つけることができます。
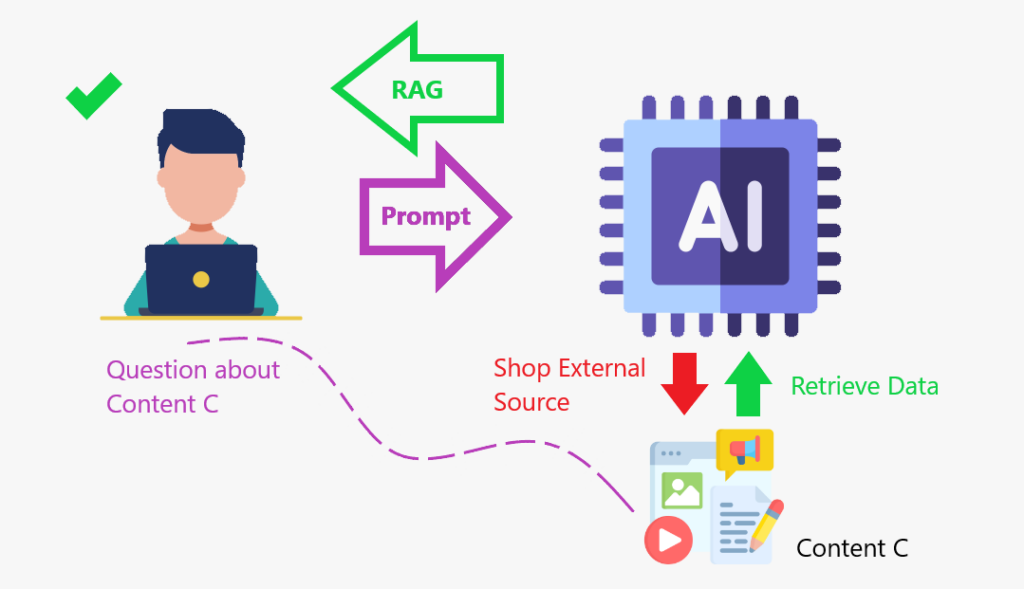
実際のデータを参照することにより、事実上の正確さを強化します
ragは、LLMSのプロセスを支援し、知識を統合して、より関連性の高い回答を作成する
ラグは、知識のギャップとAIの幻覚を減らすのに役立ちます
a
コンテンツストアの準備# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunks
# Imports
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.chains import create_retrieval_chain
from langchain_openai import ChatOpenAI
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from scripts.secret import OPENAI_KEY
from scripts.document_loader import load_document
import streamlit as st
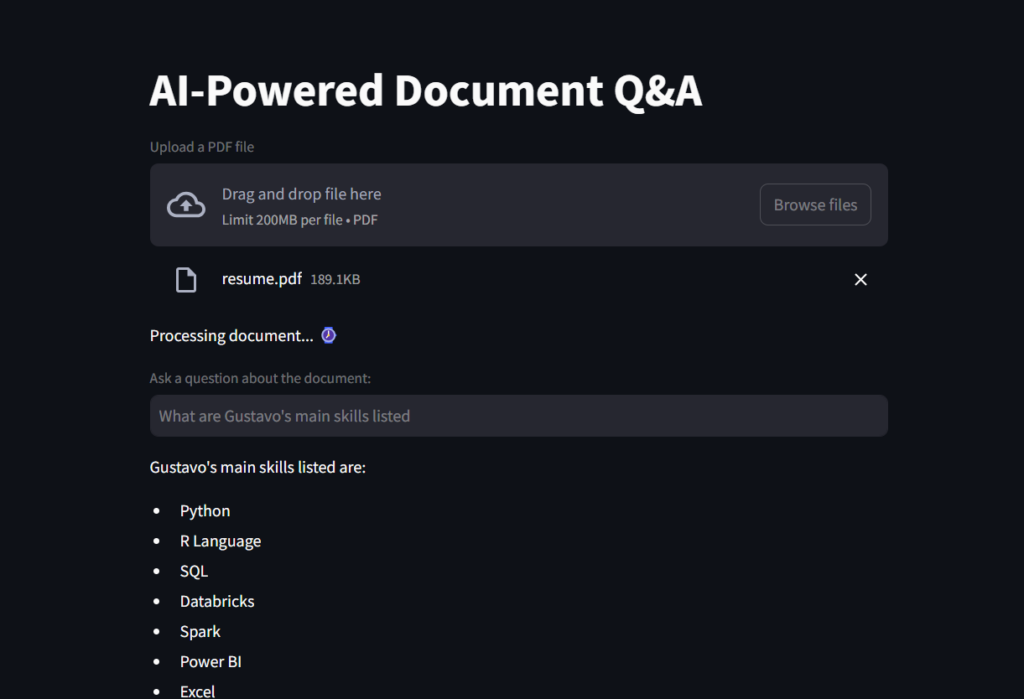
最後に、ユーザー入力の変数質問を作成します。この質問ボックスがクエリで満たされている場合、それをチェーンに渡します。チェーンは、LLMを呼び出してアプリの画面に印刷される応答を処理して返すように呼びます。
# Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:")
 このプロジェクトでは、RAGフレームワークとは何か、LLMのパフォーマンスが向上し、特定の知識でうまく機能するのに役立つ方法を学びました。
このプロジェクトでは、RAGフレームワークとは何か、LLMのパフォーマンスが向上し、特定の知識でうまく機能するのに役立つ方法を学びました。
AIは、取扱説明書、企業のデータベース、一部のファイナンスファイル、または契約の知識を供給し、ドメイン固有のコンテンツクエリに正確に対応するために微調整できます。ナレッジベースは、コンテンツストアで
参照
https://www.ibm.com/think/topics/retrieval-augmented-generation
https://www.geeksforgeeks.org/how-to-get-your-openai-apii-key
以上がLLM RAG:AI搭載ファイルリーダーアシスタントの作成の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。