
ホームページ >テクノロジー周辺機器 >AI >6一般的なLLMカスタマイズ戦略は簡単に説明しました
6一般的なLLMカスタマイズ戦略は簡単に説明しました

- 王林オリジナル
- 2025-02-25 16:01:08625ブラウズ
この記事では、単純なテクニックからよりリソース集約的な方法に至るまで、大規模な言語モデル(LLM)をカスタマイズするための6つの重要な戦略を調査します。 適切なアプローチを選択することは、特定のニーズ、リソース、および技術的な専門知識に依存します。
なぜLLMSをカスタマイズするのか?事前に訓練されたLLMSは、強力ですが、特定のビジネスまたはドメインの要件に欠けていることがよくあります。 LLMをカスタマイズすることで、モデルをゼロからトレーニングすることの禁止コストなしに、その機能を正確なニーズに合わせて調整できます。 これは、大規模なリソースを欠いている小規模なチームにとって特に重要です。
右のLLMを選択:
カスタマイズする前に、適切なベースモデルを選択することが重要です。考慮すべき要因は次のとおりです
オープンソース対独自:オープンソースモデルは柔軟性と制御を提供しますが、技術的なスキルを需要がありますが、独自のモデルはアクセスを容易にし、しばしばコストで優れたパフォーマンスを提供します。
- タスクとメトリック:
- さまざまなモデルがさまざまなタスクに優れています(質問回答、要約、コード生成)。 ベンチマークメトリックとドメイン固有のテストが不可欠です アーキテクチャ: デコーダーのみのモデル(GPTなど)はテキスト生成で強力ですが、エンコーダーデコーダーモデル(T5など)は翻訳に適しています。 専門家の混合物(MOE)のような新しいアーキテクチャは、約束を示しています
- モデルサイズ:大型モデルは一般的にパフォーマンスが向上しますが、より多くの計算リソースが必要です。
- 6つのLLMカスタマイズ戦略(リソース強度でランク付け):
- 次の戦略は、リソース消費の昇順で提示されます: 1。プロンプトエンジニアリング
プロンプトエンジニアリングには、入力テキスト(プロンプト)を慎重に作成して、LLMの応答を導きます。 これには、命令、コンテキスト、入力データ、および出力インジケーターが含まれます。 ゼロショット、ワンショット、少数のショットプロンプトなどのテクニック、および思考のチェーン(COT)、ツリー、自動推論、ツールの使用(ART)、反応などのより高度な方法は、パフォーマンスを大幅に改善できます。 。 迅速なエンジニアリングは効率的で容易に実装されています
2。デコードとサンプリング戦略推論時間でのデコード戦略(貪欲な検索、ビーム検索、サンプリング)およびサンプリングパラメーター(温度、TOP-K、P)の制御を制御すると、LLMの出力のランダム性と多様性を調整できます。 これは、モデルの動作に影響を与えるための低コストの方法です
3。検索拡張生成(RAG)

RAGは、外部の知識を組み込むことによりLLM応答を強化します。 これには、知識ベースから関連情報を取得し、ユーザーのクエリとともにLLMに供給することが含まれます。 これにより、特にドメイン固有のタスクの幻覚が軽減され、精度が向上します。 ragは、LLMを再訓練する必要がないため、比較的リソース効率が高い。
4。エージェントベースのシステム
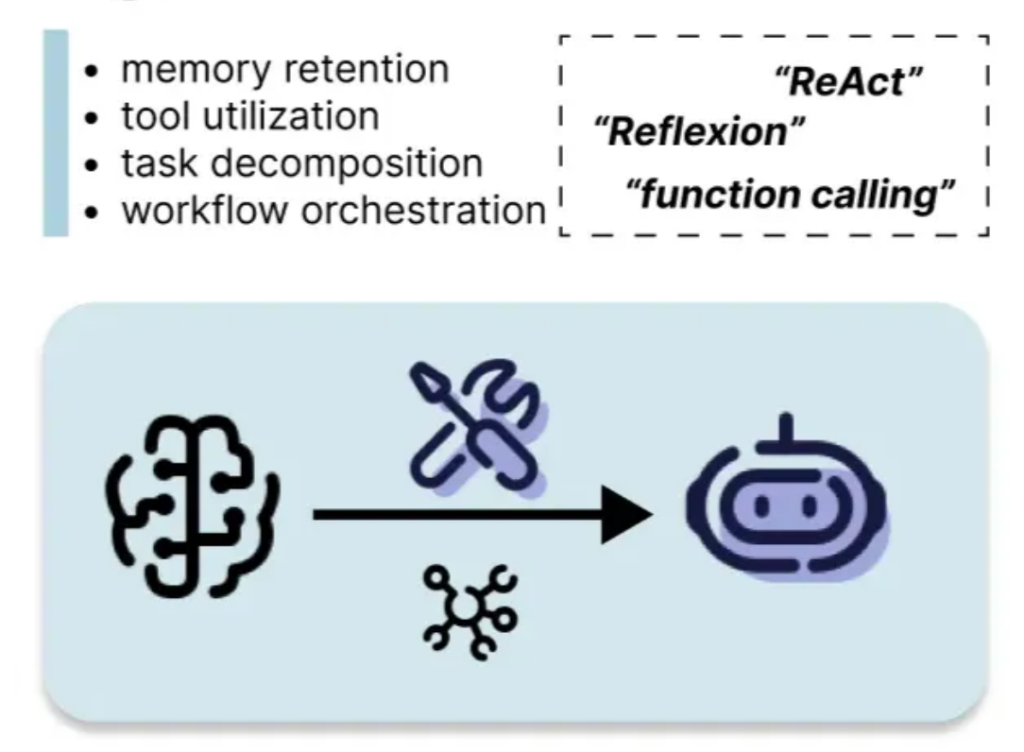
エージェントベースのシステムにより、LLMは環境と対話し、ツールを使用し、メモリを維持できます。 React(相乗効果と演技)のようなフレームワークは、推論とアクションと観察を組み合わせて、複雑なタスクのパフォーマンスを向上させます。 エージェントは、複雑なワークフローとツールの利用を管理する上で大きな利点を提供します。 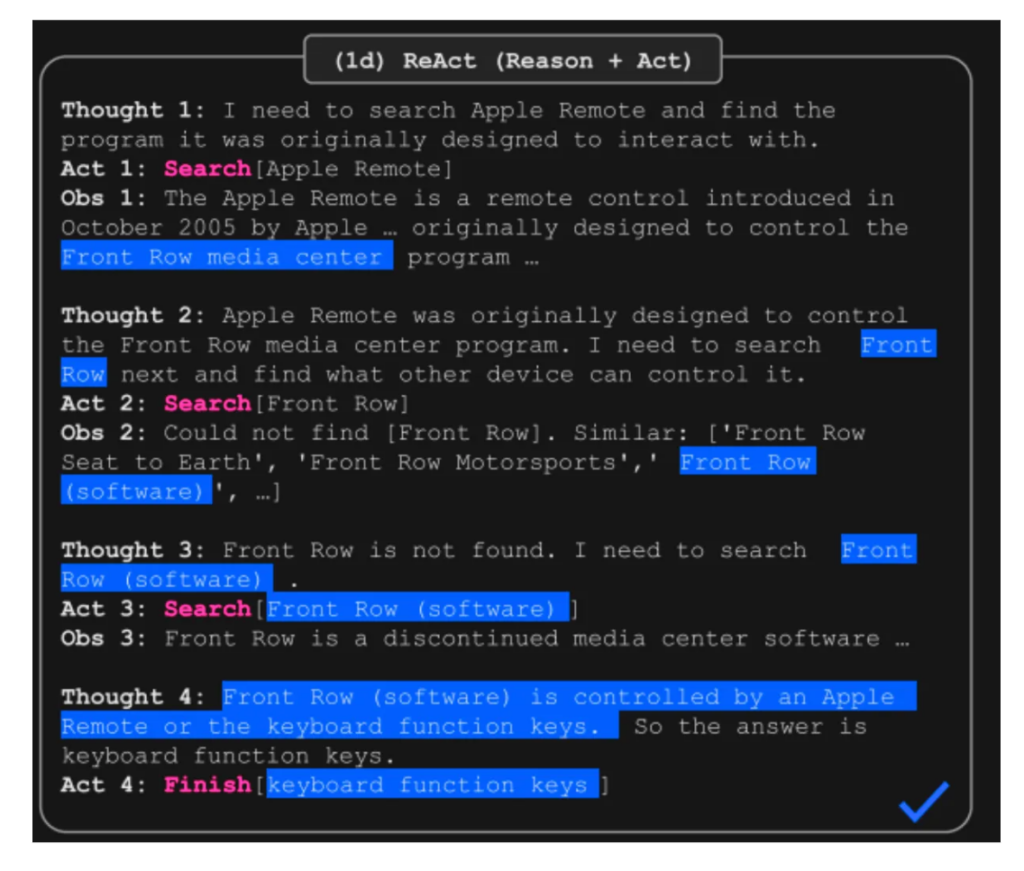
5。微調整
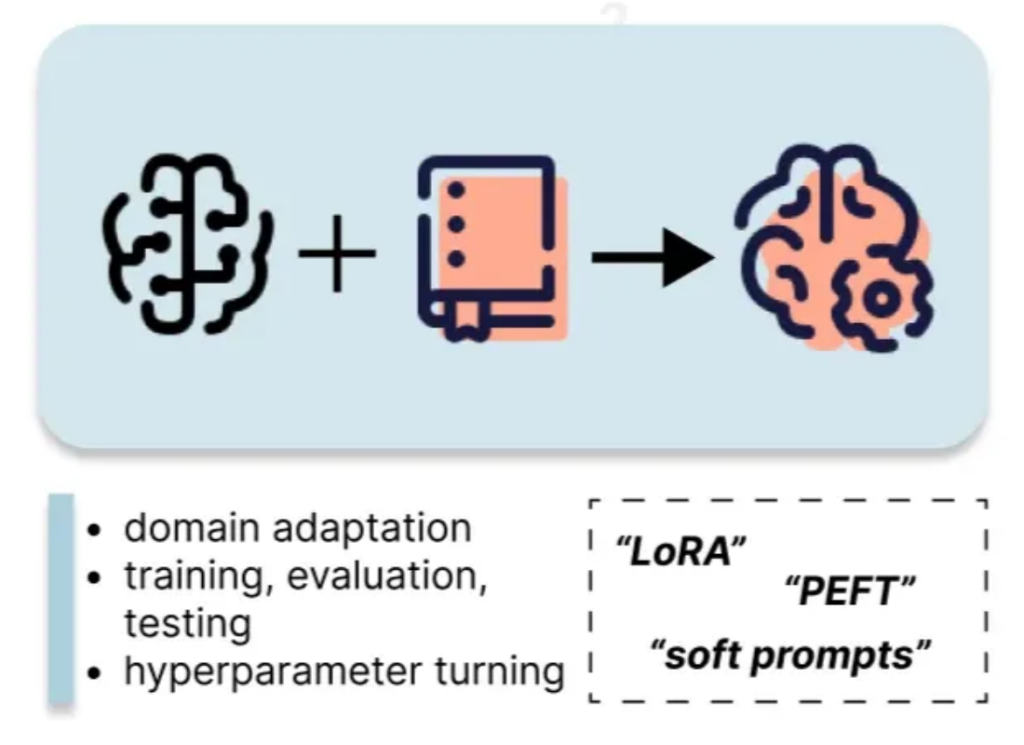
微調整には、カスタムデータセットを使用してLLMのパラメーターを更新することが含まれます。 LORAなどのパラメーター効率の高い微調整(PEFT)メソッドは、完全な微調整と比較して計算コストを大幅に削減します。 このアプローチには、以前の方法よりも多くのリソースが必要ですが、より実質的なパフォーマンスの向上を提供します。
6。人間のフィードバックからの強化学習(RLHF)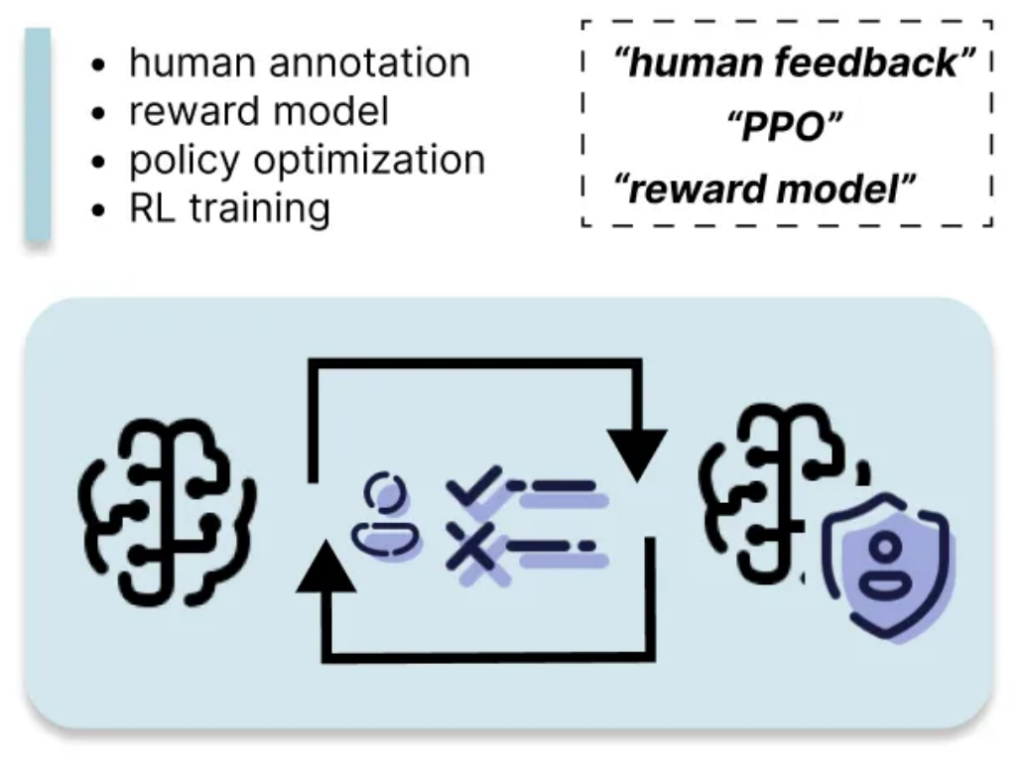
この概要は、さまざまなLLMカスタマイズ手法の包括的な理解を提供し、特定の要件とリソースに基づいて最も適切な戦略を選択できるようにします。 選択を行う際に、リソースの消費とパフォーマンスの向上のトレードオフを忘れないでください。
以上が6一般的なLLMカスタマイズ戦略は簡単に説明しましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。