
ホームページ >バックエンド開発 >Python チュートリアル >Azure Cosmos DBのベクトル検索を始めましょう
Azure Cosmos DBのベクトル検索を始めましょう

- Susan Sarandonオリジナル
- 2025-01-26 20:15:09366ブラウズ
このチュートリアルでは、シンプルなムービー データセットを使用して、Azure Cosmos DB for NoSQL にベクトル検索を迅速に実装する方法を示します。 このアプリケーションは Python、TypeScript、.NET、Java で利用でき、セットアップ、データの読み込み、類似性検索クエリの手順を段階的に説明しています。
ベクター データベースは、データの高次元の数学的表現であるベクター エンベディングの保存と管理に優れています。各ディメンションはデータの特徴を反映しており、その数は数万に及ぶ可能性があります。この空間内のベクトルの位置は、その特性を示します。 この技術は、単語、フレーズ、ドキュメント、画像、音声などのさまざまなデータ タイプをベクトル化し、類似性検索、マルチモーダル検索、推奨エンジン、大規模言語モデル (LLM) などのアプリケーションを可能にします。
前提条件:
- Azure サブスクリプション (または無料の Azure アカウント、または Azure Cosmos DB for NoSQL の無料枠)。
- NoSQL 用 Azure Cosmos DB アカウント。
-
text-embedding-ada-002埋め込みモデルがデプロイされた Azure OpenAI Service リソース (Azure AI Foundry ポータルからアクセス可能)。 このモデルはテキストの埋め込みを提供します。 - 必要なプログラミング言語環境 (Maven for Java)。
Azure Cosmos DB for NoSQL の Vector Database の構成:
-
機能を有効にします: これは 1 回限りのステップです。 Azure Cosmos DB 内でのベクター インデックス作成と検索を明示的に有効にします。

-
データベースとコンテナの作成:
movies_dbのパーティション キーを使用してデータベース (例:movies) とコンテナ (例:/id) を作成します。 -
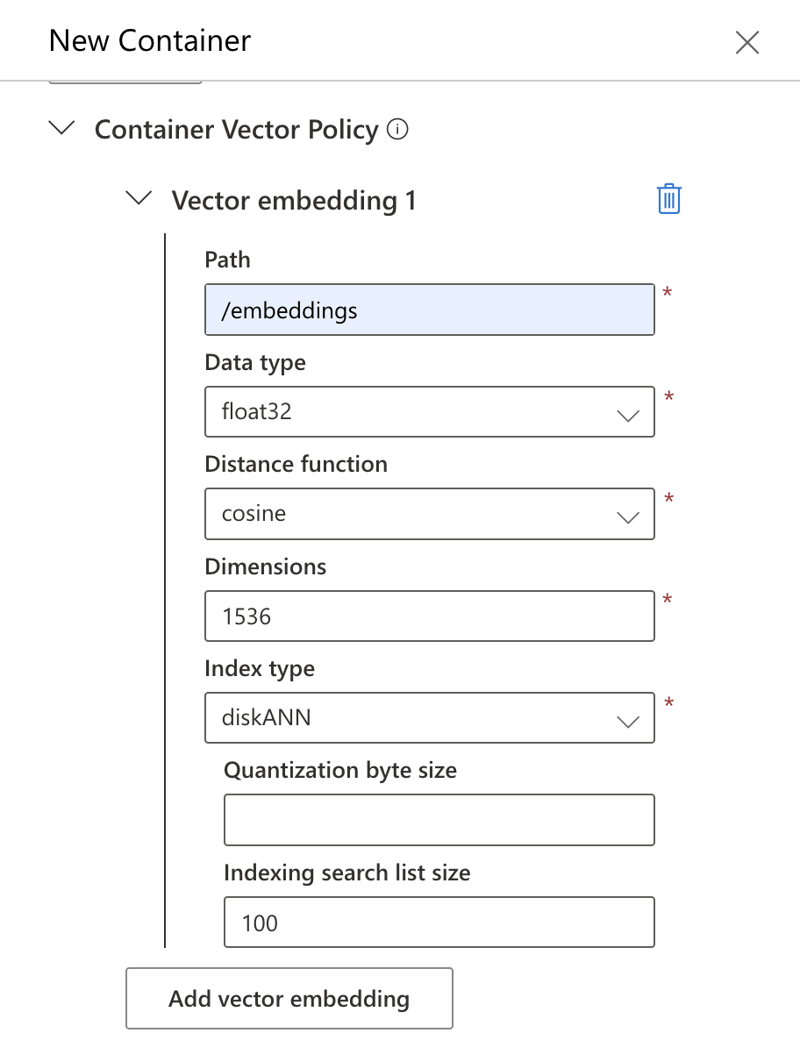
ポリシーの作成: コンテナーのベクター埋め込みポリシーとインデックス作成ポリシーを構成します。 この例では、以下に示す設定を使用します (ここでは Azure portal を介した手動構成が使用されていますが、プログラムによる方法も使用できます)。
インデックス タイプ 注: この例では、
diskANNモデルと一致する 1536 の次元のtext-embedding-ada-002インデックス タイプを使用します。 適応性はありますが、インデックス タイプを変更すると、新しい次元に一致するように埋め込みモデルを調整する必要があります。

Azure Cosmos DB へのデータの読み込み:
サンプル movies.json ファイルは、動画データを提供します。このプロセスには以下が含まれます:
- JSONファイルから映画情報を読む。 Azure Openaiサービスを使用した映画の説明のためのベクトル埋め込みの生成。
- 完全なデータ(タイトル、説明、埋め込み)をAzure Cosmos DBコンテナに挿入します。
- 先に進む前に、次の環境変数を設定します:
リポジトリをクローンします:
<code class="language-bash">export COSMOS_DB_CONNECTION_STRING="" export DATABASE_NAME="" export CONTAINER_NAME="" export AZURE_OPENAI_ENDPOINT="" export AZURE_OPENAI_KEY="" export AZURE_OPENAI_VERSION="2024-10-21" export EMBEDDINGS_MODEL="text-embedding-ada-002"</code>データ読み込みに関する言語固有の指示を以下に示します。 各メソッドは、上記の環境変数を使用します。 実行の成功は、COSMOS DBへのデータ挿入を示すメッセージを出力します。 データの読み込み手順(省略):
<code class="language-bash">git clone https://github.com/abhirockzz/cosmosdb-vector-search-python-typescript-java-dotnet cd cosmosdb-vector-search-python-typescript-java-dotnet</code>
python:
-
タイプスクリプト:
cd python; python3 -m venv .venv; source .venv/bin/activate; pip install -r requirements.txt; python load.py -
java:
cd typescript; npm install; npm run build; npm run load -
.net:
cd java; mvn clean install; java -jar target/cosmosdb-java-vector-search-1.0-SNAPSHOT.jar load -
Azure Cosmos DBのデータの検証:
cd dotnet; dotnet restore; dotnet run load
vector/類似性検索:
 検索コンポーネントは、
検索コンポーネントは、
検索基準のベクトル埋め込みを生成します
を使用して、既存の埋め込みと比較します。
VectorDistance
- 言語固有の指示(環境変数が設定され、データがロードされると仮定):
-
VectorDistance検索手順(省略):
<code class="language-sql">SELECT TOP @num_results c.id, c.description, VectorDistance(c.embeddings, @embedding) AS similarityScore FROM c ORDER BY VectorDistance(c.embeddings, @embedding)</code>
python:
タイプスクリプト:
-
python search.py "inspiring" 3java: -
npm run search "inspiring" 3.net: -
java -jar target/cosmosdb-java-vector-search-1.0-SNAPSHOT.jar search "inspiring" 3クロージングメモ: -
さまざまなベクトルインデックスタイプ(、
dotnet run search "inspiring" 3)、距離メトリック(Cosine、Euclidean、Dot製品)、および埋め込みモデル( 、
以上がAzure Cosmos DBのベクトル検索を始めましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。