



Web スクレイピングは、検索拡張生成 (RAG) アプリケーションのコンテンツを収集するための一般的な方法です。ただし、Web ページのコンテンツを解析するのは困難な場合があります。
Mozilla のオープンソース Readability.js ライブラリは、Web ページの重要な部分のみを抽出するための便利なソリューションを提供します。 RAG アプリケーションのデータ取り込みパイプラインへの統合を見てみましょう。
Web ページからの非構造化データの抽出
Web ページは非構造化データの豊富なソースであり、RAG アプリケーションに最適です。 ただし、Web ページにはヘッダー、サイドバー、フッターなどの無関係な情報が含まれることがよくあります。ブラウジングには便利ですが、この余分なコンテンツはページの本題から逸れてしまいます。
最適な RAG データを得るには、無関係なコンテンツを削除する必要があります。 Cheerio のようなツールはサイトの既知の構造に基づいて HTML を解析できますが、このアプローチは多様な Web サイトのレイアウトをスクレイピングするには非効率的です。関連するコンテンツのみを抽出するには、堅牢な方法が必要です。
リーダービュー機能の活用
ほとんどのブラウザには、記事のタイトルとコンテンツ以外のすべてを削除するリーダー ビューが含まれています。次の画像は、DataStax ブログ投稿に適用される標準のブラウジング モードとリーダー モードの違いを示しています。

Mozilla は、Firefox のリーダー モードの背後にあるライブラリである Readability.js をスタンドアロンのオープンソース モジュールとして提供しています。これにより、Readability.js をデータ パイプラインに統合して、無関係なコンテンツを削除し、スクレイピングの結果を向上させることができます。
Node.js と Readability.js を使用したデータのスクレイピング
Node.js でのベクター埋め込みの作成に関する以前のブログ投稿から記事コンテンツをスクレイピングする方法を説明します。 次の JavaScript コードは、ページの HTML を取得します:
const html = await fetch( "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js" ).then((res) => res.text()); console.log(html);
これには、ナビゲーション、フッター、Web サイトで一般的なその他の要素を含む、すべての HTML が含まれます。
また、Cheerio を使用して特定の要素を選択することもできます。
npm install cheerio
import * as cheerio from "cheerio";
const html = await fetch(
"https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js"
).then((res) => res.text());
const $ = cheerio.load(html);
console.log($("h1").text(), "\n");
console.log($("section#blog-content > div:first-child").text());
これにより、タイトルと記事のテキストが生成されます。 ただし、このアプローチは HTML 構造の知識に依存しており、常に実現可能であるとは限りません。
より良いアプローチには、Readability.js と jsdom をインストールすることが含まれます。
npm install @mozilla/readability jsdom
Readability.js はブラウザ環境内で動作するため、Node.js でこれをシミュレートするには jsdom が必要です。 ロードされた HTML をドキュメントに変換し、Readability.js を使用してコンテンツを解析できます。
import { Readability } from "@mozilla/readability";
import { JSDOM } from "jsdom";
const url = "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js";
const html = await fetch(url).then((res) => res.text());
const doc = new JSDOM(html, { url });
const reader = new Readability(doc.window.document);
const article = reader.parse();
console.log(article);
article オブジェクトには、解析されたさまざまな要素が含まれています:
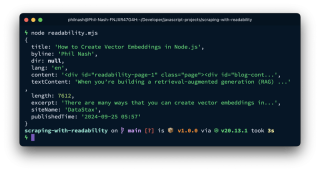
これには、タイトル、著者、抜粋、発行時刻、HTML (content) とプレーン テキスト (textContent) の両方が含まれます。 textContent はチャンク化、埋め込み、および保存の準備ができていますが、content はさらなる処理のためにリンクと画像を保持します。
isProbablyReaderable 関数は、ドキュメントが Readability.js に適しているかどうかを判断するのに役立ちます:
const html = await fetch( "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js" ).then((res) => res.text()); console.log(html);
不適切なページにはレビューのためにフラグを立てる必要があります。
可読性を LangChain.js と統合する
Readability.js は LangChain.js とシームレスに統合されます。次の例では、LangChain.js を使用してページを読み込み、MozillaReadabilityTransformer でコンテンツを抽出し、RecursiveCharacterTextSplitter でテキストを分割し、OpenAI で埋め込みを作成し、Astra DB にデータを保存します。
必要な依存関係:
npm install cheerio
環境変数として、Astra DB 認証情報 (ASTRA_DB_APPLICATION_TOKEN、ASTRA_DB_API_ENDPOINT) と OpenAI API キー (OPENAI_API_KEY) が必要です。
必要なモジュールをインポートします:
import * as cheerio from "cheerio";
const html = await fetch(
"https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js"
).then((res) => res.text());
const $ = cheerio.load(html);
console.log($("h1").text(), "\n");
console.log($("section#blog-content > div:first-child").text());
コンポーネントの初期化:
npm install @mozilla/readability jsdom
ドキュメントのロード、変換、分割、埋め込み、保存:
import { Readability } from "@mozilla/readability";
import { JSDOM } from "jsdom";
const url = "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js";
const html = await fetch(url).then((res) => res.text());
const doc = new JSDOM(html, { url });
const reader = new Readability(doc.window.document);
const article = reader.parse();
console.log(article);
Readability.js による Web スクレイピングの精度の向上
Readability.js は、Firefox のリーダー モードを強化する堅牢なライブラリであり、Web ページから関連データを効率的に抽出し、RAG データの品質を向上させます。 直接使用することも、LangChain.js の MozillaReadabilityTransformer 経由で使用することもできます。
これは取り込みパイプラインの初期段階にすぎません。 チャンク化、埋め込み、Astra DB ストレージは、RAG アプリケーションを構築する後続のステップです。
RAG アプリケーションで Web コンテンツをクリーニングするために他の方法を採用していますか? あなたのテクニックをシェアしてください!
以上がReadability.js を使用して HTML コンテンツをクリーンアップして検索拡張生成を行うの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 JavaScriptの文字列文字を交換しますMar 11, 2025 am 12:07 AM
JavaScriptの文字列文字を交換しますMar 11, 2025 am 12:07 AMJavaScript文字列置換法とFAQの詳細な説明 この記事では、javaScriptの文字列文字を置き換える2つの方法について説明します:内部JavaScriptコードとWebページの内部HTML。 JavaScriptコード内の文字列を交換します 最も直接的な方法は、置換()メソッドを使用することです。 str = str.replace( "find"、 "置換"); この方法は、最初の一致のみを置き換えます。すべての一致を置き換えるには、正規表現を使用して、グローバルフラグGを追加します。 str = str.replace(/fi
 カスタムGoogle検索APIセットアップチュートリアルMar 04, 2025 am 01:06 AM
カスタムGoogle検索APIセットアップチュートリアルMar 04, 2025 am 01:06 AMこのチュートリアルでは、カスタムGoogle検索APIをブログまたはWebサイトに統合する方法を示し、標準のWordPressテーマ検索関数よりも洗練された検索エクスペリエンスを提供します。 驚くほど簡単です!検索をyに制限することができます
 例JSONファイルの例Mar 03, 2025 am 12:35 AM
例JSONファイルの例Mar 03, 2025 am 12:35 AMこの記事シリーズは、2017年半ばに最新の情報と新鮮な例で書き直されました。 このJSONの例では、JSON形式を使用してファイルに単純な値を保存する方法について説明します。 キー価値ペア表記を使用して、あらゆる種類を保存できます
 独自のAjax Webアプリケーションを構築しますMar 09, 2025 am 12:11 AM
独自のAjax Webアプリケーションを構築しますMar 09, 2025 am 12:11 AMそれで、あなたはここで、Ajaxと呼ばれるこのことについてすべてを学ぶ準備ができています。しかし、それは正確には何ですか? Ajaxという用語は、動的でインタラクティブなWebコンテンツを作成するために使用されるテクノロジーのゆるいグループ化を指します。 Ajaxという用語は、もともとJesse Jによって造られました
 8見事なjQueryページレイアウトプラグインMar 06, 2025 am 12:48 AM
8見事なjQueryページレイアウトプラグインMar 06, 2025 am 12:48 AM楽なWebページレイアウトのためにjQueryを活用する:8本質的なプラグイン jQueryは、Webページのレイアウトを大幅に簡素化します。 この記事では、プロセスを合理化する8つの強力なjQueryプラグイン、特に手動のウェブサイトの作成に役立ちます
 ' this' JavaScriptで?Mar 04, 2025 am 01:15 AM
' this' JavaScriptで?Mar 04, 2025 am 01:15 AMコアポイント これは通常、メソッドを「所有」するオブジェクトを指しますが、関数がどのように呼び出されるかに依存します。 現在のオブジェクトがない場合、これはグローバルオブジェクトを指します。 Webブラウザでは、ウィンドウで表されます。 関数を呼び出すと、これはグローバルオブジェクトを維持しますが、オブジェクトコンストラクターまたはそのメソッドを呼び出すとき、これはオブジェクトのインスタンスを指します。 call()、apply()、bind()などのメソッドを使用して、このコンテキストを変更できます。これらのメソッドは、与えられたこの値とパラメーターを使用して関数を呼び出します。 JavaScriptは優れたプログラミング言語です。数年前、この文はそうでした
 ソースビューアーでjQueryの知識を向上させますMar 05, 2025 am 12:54 AM
ソースビューアーでjQueryの知識を向上させますMar 05, 2025 am 12:54 AMjQueryは素晴らしいJavaScriptフレームワークです。ただし、他のライブラリと同様に、何が起こっているのかを発見するためにフードの下に入る必要がある場合があります。おそらく、バグをトレースしているか、jQueryが特定のUIをどのように達成するかに興味があるからです
 モバイル開発用のモバイルチートシート10個Mar 05, 2025 am 12:43 AM
モバイル開発用のモバイルチートシート10個Mar 05, 2025 am 12:43 AMこの投稿は、Android、BlackBerry、およびiPhoneアプリ開発用の有用なチートシート、リファレンスガイド、クイックレシピ、コードスニペットをコンパイルします。 開発者がいないべきではありません! タッチジェスチャーリファレンスガイド(PDF) Desigの貴重なリソース


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

SublimeText3 中国語版
中国語版、とても使いやすい
ホットトピック
 7348
7348 15162714135252126525121429
15162714135252126525121429