



データ エンジニアリング ETL パイプラインを構築するための実践的なガイド。このガイドでは、ストレージ、処理、自動化、監視をカバーする、データ エンジニアリングの基礎を理解して実装するための実践的なアプローチを提供します。
データ エンジニアリングとは何ですか?
データ エンジニアリングは、生データを分析と意思決定のための貴重な洞察に変換するためのデータ ワークフローの整理、処理、自動化に焦点を当てています。 このガイドの内容は次のとおりです:
- データ ストレージ: データの保存場所と方法を定義します。
- データ処理: 生データをクリーニングおよび変換するための技術。
- ワークフローの自動化: シームレスで効率的なワークフローの実行を実装します。
- システム監視: データ パイプライン全体の信頼性とスムーズな動作を確保します。
各ステージを探索しましょう!
開発環境のセットアップ
始める前に、以下のものがあることを確認してください:
-
環境セットアップ:
- Unix ベースのシステム (macOS) または Linux 用 Windows サブシステム (WSL)。
- Python 3.11 (またはそれ以降) がインストールされています。
- PostgreSQL データベースがローカルにインストールされ、実行されています。
-
前提条件:
- 基本的なコマンドラインの熟練度。
- Python プログラミングの基本的な知識。
- ソフトウェアのインストールと構成のための管理者権限。
-
アーキテクチャの概要:


この図は、パイプライン コンポーネント間の相互作用を示しています。このモジュラー設計は、ワークフロー オーケストレーション用の Airflow、分散データ処理用の Spark、構造化データ ストレージ用の PostgreSQL など、各ツールの長所を活用しています。
-
必要なツールのインストール:
- PostgreSQL:
brew update brew install postgresql
- PySpark:
brew install apache-spark
- エアフロー:
python -m venv airflow_env source airflow_env/bin/activate # macOS/Linux pip install "apache-airflow[postgres]==" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.10.4/constraints-3.11.txt" airflow db migrate
- PostgreSQL:
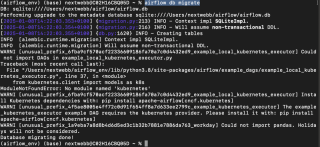
環境が準備できたら、各コンポーネントを詳しく見てみましょう。
1.データストレージ: データベースとファイルシステム
データ ストレージは、あらゆるデータ エンジニアリング パイプラインの基盤です。 2 つの主なカテゴリを検討します:
-
データベース: 検索、レプリケーション、インデックス作成などの機能を備えた効率的に編成されたデータ ストレージ。例:
- SQL データベース: 構造化データ (PostgreSQL、MySQL など) 用。
- NoSQL データベース: スキーマのないデータ用 (MongoDB、Redis など)。
- ファイル システム: データベースより機能が少なく、非構造化データに適しています。
PostgreSQL のセットアップ
- PostgreSQL サービスを開始します:
brew update brew install postgresql

- データベースの作成、接続、テーブルの作成:
brew install apache-spark
- サンプルデータの挿入:
python -m venv airflow_env source airflow_env/bin/activate # macOS/Linux pip install "apache-airflow[postgres]==" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.10.4/constraints-3.11.txt" airflow db migrate
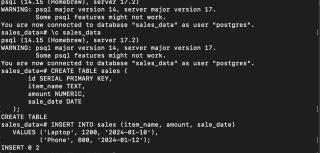
データは PostgreSQL に安全に保存されました。
2.データ処理: PySpark と分散コンピューティング
データ処理フレームワークは、生データを実用的な洞察に変換します。分散コンピューティング機能を備えた Apache Spark は、人気のある選択肢です。
-
処理モード:
- バッチ処理: 固定サイズのバッチでデータを処理します。
- ストリーム処理: データをリアルタイムで処理します。
- 共通ツール: Apache Spark、Flink、Kafka、Hive。
PySpark によるデータの処理
- Java と PySpark をインストールします:
brew services start postgresql
- CSV ファイルからデータをロード:
次のデータを含む sales.csv ファイルを作成します:
CREATE DATABASE sales_data;
\c sales_data
CREATE TABLE sales (
id SERIAL PRIMARY KEY,
item_name TEXT,
amount NUMERIC,
sale_date DATE
);
次の Python スクリプトを使用して、データをロードして処理します:
INSERT INTO sales (item_name, amount, sale_date)
VALUES ('Laptop', 1200, '2024-01-10'),
('Phone', 800, '2024-01-12');

- 高価値販売のフィルター:
brew install openjdk@11 && brew install apache-spark


-
Postgres DB ドライバーのセットアップ: 必要に応じて PostgreSQL JDBC ドライバーをダウンロードし、以下のスクリプト内のパスを更新します。
-
処理されたデータを PostgreSQL に保存:
brew update brew install postgresql


Spark によるデータ処理が完了しました。
3.ワークフローの自動化: Airflow
自動化は、スケジュールと依存関係の定義を使用してワークフロー管理を合理化します。 Airflow、Oozie、Luigi などのツールを使用すると、これが容易になります。
Airflow による ETL の自動化
- エアフローの初期化:
brew install apache-spark


- ワークフロー (DAG) の作成:
python -m venv airflow_env source airflow_env/bin/activate # macOS/Linux pip install "apache-airflow[postgres]==" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.10.4/constraints-3.11.txt" airflow db migrate
この DAG は毎日実行され、PySpark スクリプトを実行し、検証ステップが含まれます。 失敗すると電子メールアラートが送信されます。
-
ワークフローを監視します: DAG ファイルを Airflow の
dags/ディレクトリに配置し、Airflow サービスを再起動し、http://localhost:8080で Airflow UI を介して監視します。
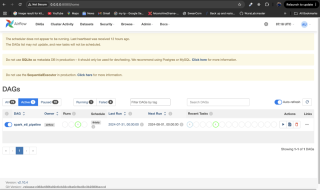
4.システム監視
モニタリングによりパイプラインの信頼性が保証されます。 Airflow のアラート、または Grafana や Prometheus などのツールとの統合は、効果的な監視戦略です。 Airflow UI を使用して、タスクのステータスとログを確認します。
結論
データ ストレージのセットアップ、PySpark を使用したデータの処理、Airflow によるワークフローの自動化、システムの監視について学びました。 データ エンジニアリングは重要な分野であり、このガイドはさらなる探求のための強力な基盤を提供します。 さらに詳しい情報については、提供されている参考資料を必ず参照してください。
以上がデータ エンジニアリングの基礎: 実践ガイドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Pythonの融合リスト:適切な方法を選択しますMay 14, 2025 am 12:11 AM
Pythonの融合リスト:適切な方法を選択しますMay 14, 2025 am 12:11 AMTomergelistsinpython、あなたはオペレーター、extendmethod、listcomfulting、olitertools.chain、それぞれの特異的advantages:1)operatorissimplebutlessforlargelist;
 Python 3の2つのリストを連結する方法は?May 14, 2025 am 12:09 AM
Python 3の2つのリストを連結する方法は?May 14, 2025 am 12:09 AMPython 3では、2つのリストをさまざまな方法で接続できます。1)小さなリストに適したオペレーターを使用しますが、大きなリストには非効率的です。 2)メモリ効率が高い大規模なリストに適した拡張方法を使用しますが、元のリストは変更されます。 3)元のリストを変更せずに、複数のリストをマージするのに適した *オペレーターを使用します。 4)Itertools.chainを使用します。これは、メモリ効率が高い大きなデータセットに適しています。
 Python Concatenateリスト文字列May 14, 2025 am 12:08 AM
Python Concatenateリスト文字列May 14, 2025 am 12:08 AMJoin()メソッドを使用することは、Pythonのリストから文字列を接続する最も効率的な方法です。 1)join()メソッドを使用して、効率的で読みやすくなります。 2)サイクルは、大きなリストに演算子を非効率的に使用します。 3)リスト理解とJoin()の組み合わせは、変換が必要なシナリオに適しています。 4)redoce()メソッドは、他のタイプの削減に適していますが、文字列の連結には非効率的です。完全な文は終了します。
 Pythonの実行、それは何ですか?May 14, 2025 am 12:06 AM
Pythonの実行、それは何ですか?May 14, 2025 am 12:06 AMpythonexexecutionistheprocessoftransforningpythoncodeintoexecutabletructions.1)interpreterreadSthecode、変換intobytecode、thepythonvirtualmachine(pvm)executes.2)theglobalinterpreeterlock(gil)管理委員会、
 Python:重要な機能は何ですかMay 14, 2025 am 12:02 AM
Python:重要な機能は何ですかMay 14, 2025 am 12:02 AMPythonの主な機能には次のものがあります。1。構文は簡潔で理解しやすく、初心者に適しています。 2。動的タイプシステム、開発速度の向上。 3。複数のタスクをサポートするリッチ標準ライブラリ。 4.強力なコミュニティとエコシステム、広範なサポートを提供する。 5。スクリプトと迅速なプロトタイピングに適した解釈。 6.さまざまなプログラミングスタイルに適したマルチパラダイムサポート。
 Python:コンパイラまたはインタープリター?May 13, 2025 am 12:10 AM
Python:コンパイラまたはインタープリター?May 13, 2025 am 12:10 AMPythonは解釈された言語ですが、コンパイルプロセスも含まれています。 1)Pythonコードは最初にBytecodeにコンパイルされます。 2)ByteCodeは、Python Virtual Machineによって解釈および実行されます。 3)このハイブリッドメカニズムにより、Pythonは柔軟で効率的になりますが、完全にコンパイルされた言語ほど高速ではありません。
 ループvs whileループ用のpython:いつ使用するか?May 13, 2025 am 12:07 AM
ループvs whileループ用のpython:いつ使用するか?May 13, 2025 am 12:07 AMuseaforloopwhenteratingoverasequenceor foraspificnumberoftimes; useawhileloopwhentinuninguntinuntilaConditionismet.forloopsareidealforknownownownownownownoptinuptinuptinuptinuptinutionsituations whileoopsuitsituations withinterminedationations。
 Pythonループ:最も一般的なエラーMay 13, 2025 am 12:07 AM
Pythonループ:最も一般的なエラーMay 13, 2025 am 12:07 AMpythonloopscanleadtoErrorslikeinfiniteloops、ModifiningListsDuringiteration、Off-Oneerrors、Zero-dexingissues、およびNestededLoopinefficiencies.toavoidhese:1)use'i


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

SublimeText3 中国語版
中国語版、とても使いやすい

Dreamweaver Mac版
ビジュアル Web 開発ツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

