


後の Advent of Code の課題のいくつかに取り組んだので、興味深い解析問題が発生した 3 日目を再訪したいと思いました。このタスクには、ノイズの多い入力から有効なコードを抽出することが含まれており、パーサーとレクサーの開発における優れた演習となります。この課題に対する私のアプローチを一緒に探っていきましょう。

Microsoft Copilot によるパズル (?) への私の愛情を示す生成された画像
私が最初にルーラー DSL について書いたとき、解析には Hy を使用しました。しかし、私の最近の生成 AI の探求では、funcparserlib ライブラリを使用して生成されたコードという新しい解析方法を導入しました。この Advent of Code のチャレンジにより、funcparserlib の複雑さを掘り下げ、生成されたコードの機能をより深く理解することができました。
レクサーの実装 (字句解析)
破損した入力を処理する最初のステップは、字句解析 (または トークン化) です。 レクサー (または トークナイザー) は入力文字列をスキャンし、それをさらなる処理のための基本的な構成要素である個々の トークン に分割します。 トークンは、そのタイプによって分類された、入力内の意味のある単位を表します。このパズルでは、次のトークン タイプに興味があります:
- 演算子 (OP): これらは、mul、do、don't などの関数名を表します。たとえば、入力 mul(2, 3) には演算子トークン mul. が含まれています。
- 数値: これらは数値です。たとえば、入力 mul(2, 3) では、2 と 3 が数値トークンとして認識されます。
- カンマ: カンマ文字 (,) は引数間の区切り文字として機能します。
- 括弧: 開き括弧 (および閉じ括弧) は、関数呼び出しの構造を定義します。
- 意味不明: このカテゴリには、他のトークン タイプと一致しない文字または文字のシーケンスが含まれます。ここで、入力の「破損した」部分が問題になります。たとえば、%$#@ または任意のランダムな文字は意味不明とみなされます。
funcparserlib はチュートリアルでマジック文字列をよく使用しますが、私はより構造化されたアプローチを好みます。マジック文字列はタイプミスを引き起こし、コードのリファクタリングを困難にする可能性があります。 Enum を使用してトークン タイプを定義すると、可読性の向上、保守性の向上、型安全性の強化など、いくつかの利点が得られます。 Enum を使用してトークン タイプを定義する方法は次のとおりです。
from enum import Enum, auto
class Spec(Enum):
OP = auto()
NUMBER = auto()
COMMA = auto()
LPAREN = auto()
RPAREN = auto()
GIBBERISH = auto()
Spec.OP、Spec.NUMBER などを使用することで、プレーンな文字列の使用に伴う曖昧さや潜在的なエラーを回避します。
Enum を funcparserlib とシームレスに統合するために、TokenSpec_ という名前のカスタム デコレーターを作成しました。このデコレーターは、funcparserlib の元の TokenSpec 関数のラッパーとして機能します。 Spec Enum の値を spec 引数として受け入れることにより、トークンの定義が簡素化されます。内部的には、列挙型 (spec.name) の文字列表現を抽出し、それを他の引数とともに元の TokenSpec 関数に渡します。
from enum import Enum, auto
class Spec(Enum):
OP = auto()
NUMBER = auto()
COMMA = auto()
LPAREN = auto()
RPAREN = auto()
GIBBERISH = auto()
装飾された TokenSpec_ 関数を使用すると、トークナイザーを定義できます。 funcparserlib の make_tokenizer を使用して、TokenSpec_ 定義のリストを取得するトークナイザーを作成します。各定義では、(仕様 ENUM からの) トークン タイプと、それに一致する正規表現を指定します。
from funcparserlib.lexer import TokenSpec
def TokenSpec_(spec: Spec, *args: Any, **kwargs: Any) -> TokenSpec:
return TokenSpec(spec.name, *args, **kwargs)
OP 正規表現は、さまざまな関数形式に一致させるために代替 (|) を使用します。具体的には:
- mul(?=(d{1,3},d{1,3})): mul の後にカンマで区切られた 2 つの数値を含む括弧が続く場合にのみ、mul と一致します。肯定的な先読みアサーション (?=...) は、括弧と数字が存在するが、一致によって消費されないことを保証します。
- do(?=()): 空の括弧が続く場合にのみ一致します。
- don't(?=()): 空の括弧が続いた場合のみ一致しません。
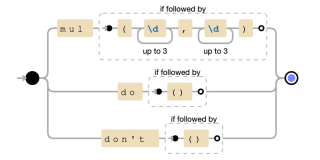
正規表現のグラフ表現
最後に、トークン化関数はトークン化中に意味不明なトークンを除外し、入力の関連部分に焦点を当ててさらなる処理を行います。
コードを解釈するプロセスには、通常、字句解析 (字句解析) と解析という 2 つの主要な段階が含まれます。私たちはすでに第 1 段階を実装しています。トークン化関数はレクサーとして機能し、入力文字列を取得してトークンのシーケンスに変換します。これらのトークンは、パーサーがコードの構造と意味を理解するために使用する基本的な構成要素です。ここで、パーサーがこれらのトークンをどのように使用するかを見てみましょう。
パーサーの実装
tokenize 関数によって返された解析されたトークンは、さらに処理するためにパーサーに送信されます。 Spec Enum と tok 関数の間のギャップを埋めるために、tok_ という名前のデコレーターを導入します。
from funcparserlib.lexer import make_tokenizer
def tokenize(input: str) -> tuple[Token, ...]:
tokenizer = make_tokenizer(
[
TokenSpec_(
Spec.OP, r"mul(?=\(\d{1,3},\d{1,3}\))|do(?=\(\))|don\'t(?=\(\))"
),
TokenSpec_(Spec.NUMBER, r"\d{1,3}"),
TokenSpec_(Spec.LPAREN, r"\("),
TokenSpec_(Spec.RPAREN, r"\)"),
TokenSpec_(Spec.COMMA, r","),
TokenSpec_(Spec.GIBBERISH, r"[\s\S]"),
]
)
return tuple(
token for token in tokenizer(input) if token.type != Spec.GIBBERISH.name
)
たとえば、Spec.NUMBER トークンがある場合、返されたパーサーはそのトークンを受け入れ、次のように値を返します。
from funcparserlib.parser import tok
def tok_(spec: Spec, *args: Any, **kwargs: Any) -> Parser[Token, str]:
return tok(spec.name, *args, **kwargs)
返された値は、>> を使用して目的のデータ型に変換できます。以下に示す演算子:
from enum import Enum, auto
class Spec(Enum):
OP = auto()
NUMBER = auto()
COMMA = auto()
LPAREN = auto()
RPAREN = auto()
GIBBERISH = auto()
通常、未知の入力を解析する場合は、潜在的なセキュリティ脆弱性を回避するために ast.literal_eval を使用することがベスト プラクティスです。ただし、この特定の Advent of Code パズルの制約 (特に、すべての数値が有効な整数である) により、文字列表現を整数に変換するために、より直接的かつ効率的な int 関数を使用できるようになります。
from funcparserlib.lexer import TokenSpec
def TokenSpec_(spec: Spec, *args: Any, **kwargs: Any) -> TokenSpec:
return TokenSpec(spec.name, *args, **kwargs)
解析ルールを定義して、特定のトークン シーケンスを強制し、意味のあるオブジェクトに変換できます。たとえば、mul 関数呼び出しを解析するには、左かっこ、数値、カンマ、別の数値、右かっこの順序が必要です。次に、このシーケンスを Mul オブジェクトに変換します。
from funcparserlib.lexer import make_tokenizer
def tokenize(input: str) -> tuple[Token, ...]:
tokenizer = make_tokenizer(
[
TokenSpec_(
Spec.OP, r"mul(?=\(\d{1,3},\d{1,3}\))|do(?=\(\))|don\'t(?=\(\))"
),
TokenSpec_(Spec.NUMBER, r"\d{1,3}"),
TokenSpec_(Spec.LPAREN, r"\("),
TokenSpec_(Spec.RPAREN, r"\)"),
TokenSpec_(Spec.COMMA, r","),
TokenSpec_(Spec.GIBBERISH, r"[\s\S]"),
]
)
return tuple(
token for token in tokenizer(input) if token.type != Spec.GIBBERISH.name
)
このルールは、必要なトークン (OP、LPAREN、COMMA、RPAREN) の tok_ パーサーと数値パーサーを組み合わせます。 >>次に、演算子は、一致したシーケンスを Mul オブジェクトに変換し、インデックス 2 と 4 のタプル要素から 2 つの数値を抽出します。
同じ原則を適用して、実行する操作としない操作の解析ルールを定義できます。これらの操作は引数を取らず (空の括弧で表されます)、Condition オブジェクトに変換されます:
from funcparserlib.parser import tok
def tok_(spec: Spec, *args: Any, **kwargs: Any) -> Parser[Token, str]:
return tok(spec.name, *args, **kwargs)
do ルールは can_proceed = True で Condition オブジェクトを作成し、don't ルールは can_proceed = False で Condition オブジェクトを作成します。
最後に、 | を使用して、これらの個々の解析ルール (do、don't、および mul) を単一の expr パーサーに結合します。 (または) 演算子:
>>> from funcparserlib.lexer import Token >>> number_parser = tok_(Spec.NUMBER) >>> number_parser.parse([Token(Spec.NUMBER.name, '123']) '123'
この expr パーサーは、入力を各ルールと順番に照合しようとし、最初に成功した照合の結果を返します。
私たちの expr パーサーは、mul(2,3)、do()、don't() などの完全な式を処理します。ただし、入力には、これらの構造化式の一部ではない個々のトークンが含まれる場合もあります。これらを処理するために、Everything という名前のキャッチオール パーサーを定義します。
>>> from funcparserlib.lexer import Token >>> from ast import literal_eval >>> number_parser = tok_(Spec.NUMBER) >> literal_eval >>> number_parser.parse([Token(Spec.NUMBER.name, '123']) 123
このパーサーは | を使用します。 (または) タイプ NUMBER、LPAREN、RPAREN、または COMMA の単一のトークンと一致する演算子。これは本質的に、より大きな式の一部ではない浮遊トークンをキャプチャする方法です。
すべてのコンポーネントを定義したら、完全なプログラムを構成するものを定義できるようになります。プログラムは 1 つ以上の「呼び出し」で構成されます。「呼び出し」は、潜在的に浮遊トークンで囲まれた式です。
呼び出しパーサーはこの構造を処理します。これは、任意の数の浮遊トークン (many(everything))、その後に単一の式 (expr)、その後に任意の数の追加の浮遊トークンと一致します。次に、operator.itemgetter(1) 関数は、結果のシーケンスから一致した式を抽出します。
number = tok_(Spec.NUMBER) >> int
プログラム パーサーによって表される完全なプログラムは、0 個以上の呼び出しで構成され、完成したパーサーを使用して入力全体が確実に消費されます。解析された結果は式のタプルに変換されます。
from enum import Enum, auto
class Spec(Enum):
OP = auto()
NUMBER = auto()
COMMA = auto()
LPAREN = auto()
RPAREN = auto()
GIBBERISH = auto()
最後に、これらすべての定義を解析関数にグループ化します。この関数は、トークンのタプルを入力として受け取り、解析された式のタプルを返します。グローバル名前空間の汚染を防ぐため、また数値パーサーは tok_ 関数に依存するため、すべてのパーサーは関数本体内で定義されます。
from funcparserlib.lexer import TokenSpec
def TokenSpec_(spec: Spec, *args: Any, **kwargs: Any) -> TokenSpec:
return TokenSpec(spec.name, *args, **kwargs)
パズルを解く
パーサーを適切に配置すれば、パート 1 を解決するのは簡単です。すべての mul 演算を見つけて乗算を実行し、結果を合計する必要があります。まず、Mul 式を処理する評価関数を定義します
from funcparserlib.lexer import make_tokenizer
def tokenize(input: str) -> tuple[Token, ...]:
tokenizer = make_tokenizer(
[
TokenSpec_(
Spec.OP, r"mul(?=\(\d{1,3},\d{1,3}\))|do(?=\(\))|don\'t(?=\(\))"
),
TokenSpec_(Spec.NUMBER, r"\d{1,3}"),
TokenSpec_(Spec.LPAREN, r"\("),
TokenSpec_(Spec.RPAREN, r"\)"),
TokenSpec_(Spec.COMMA, r","),
TokenSpec_(Spec.GIBBERISH, r"[\s\S]"),
]
)
return tuple(
token for token in tokenizer(input) if token.type != Spec.GIBBERISH.name
)
パート 1 を解決するには、入力をトークン化して解析し、定義したばかりの関数 Evaluate_skip_condition を使用して最終結果を取得します。
from funcparserlib.parser import tok
def tok_(spec: Spec, *args: Any, **kwargs: Any) -> Parser[Token, str]:
return tok(spec.name, *args, **kwargs)
パート 2 では、don't 条件が発生した場合は mul 演算の評価をスキップする必要があります。これを処理するために、新しい評価関数、evaluate_with_condition を定義します。
>>> from funcparserlib.lexer import Token >>> number_parser = tok_(Spec.NUMBER) >>> number_parser.parse([Token(Spec.NUMBER.name, '123']) '123'
この関数は、カスタム リデューサー関数でリデュースを使用して、累計とブール フラグ (条件) を維持します。条件フラグは、条件式 (do または don't) が見つかったときに更新されます。 Mul 式は、条件が True の場合にのみ評価され、合計に追加されます。
前のイテレーション
当初、私の解析アプローチには 2 つの異なるパスが含まれていました。まず、入力文字列全体をトークン化し、タイプに関係なくすべてのトークンを収集します。次に、別のステップで、特に mul 操作を識別して処理するために 2 回目のトークン化と解析を実行します。
>>> from funcparserlib.lexer import Token >>> from ast import literal_eval >>> number_parser = tok_(Spec.NUMBER) >> literal_eval >>> number_parser.parse([Token(Spec.NUMBER.name, '123']) 123
改善されたアプローチでは、トークン化と解析を 1 回のパスで実行することで、この冗長性を排除します。これで、mul、do、don't、およびその他の個々のトークンに関連するものを含む、すべてのトークン タイプを処理する単一のパーサーが完成しました。
number = tok_(Spec.NUMBER) >> int
入力を再トークン化して mul 演算を見つけるのではなく、最初のトークン化で識別されたトークン タイプを利用します。解析関数は、これらのトークン タイプを使用して、適切な式オブジェクト (Mul、Condition など) を直接構築するようになりました。これにより、入力の冗長なスキャンが回避され、効率が大幅に向上します。
これで、今週の Advent of Code の解析冒険は終わりです。この投稿にはかなりの時間を要しましたが、字句解析と解析に関する知識を再検討して固めるプロセスにより、価値のある取り組みとなりました。これは楽しく洞察力に富んだパズルでした。今後数週間でさらに複雑な課題に取り組み、学んだことを共有したいと思っています。
いつも読んでいただきありがとうございます。また来週も書きます。
以上がコンピューター コードを解析する方法、Advent of Code ay 3の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Pythonで工場モードを実装する方法は?May 16, 2025 pm 12:39 PM
Pythonで工場モードを実装する方法は?May 16, 2025 pm 12:39 PMPythonに工場パターンを実装すると、統一されたインターフェイスを作成することにより、さまざまな種類のオブジェクトを作成できます。特定の手順は次のとおりです。1。車両、車、飛行機、列車などの基本クラスと複数の継承クラスを定義します。 2。Factory Class CheerFactoryを作成し、Create_Vehicleメソッドを使用して、型パラメーターに従って対応するオブジェクトインスタンスを返します。 3。my_car = factory.create_vehicle( "car"、 "tesla"など、工場クラスを介してオブジェクトをインスタンス化します。このパターンは、コードのスケーラビリティと保守性を向上させますが、その複雑さに注意を払う必要があります
 Python Original Stringプレフィックスではrの意味がありますMay 16, 2025 pm 12:36 PM
Python Original Stringプレフィックスではrの意味がありますMay 16, 2025 pm 12:36 PMPythonでは、RまたはRプレフィックスを使用して元の文字列を定義し、逃げたすべての文字を無視し、文字列を文字通り解釈します。 1)脱出キャラクターの誤解を避けるために、正規表現とファイルパスに対処するために適用されます。 2)ラインブレークなど、逃げたキャラクターを保存する必要がある場合には適用されません。予期しない出力を防ぐために使用する場合は、慎重なチェックが必要です。
 Pythonの__del__メソッドを使用してリソースをクリーンアップする方法は?May 16, 2025 pm 12:33 PM
Pythonの__del__メソッドを使用してリソースをクリーンアップする方法は?May 16, 2025 pm 12:33 PMPythonでは、__del__メソッドはオブジェクトの破壊者であり、リソースのクリーンアップに使用されます。 1)不確実な実行時間:ごみ収集メカニズムに依存します。 2)循環参照:それにより、コールを迅速にできなくなり、weakRefモジュールを使用して処理することがあります。 3)例外処理:__del__でスローされた例外は、Try-Exectブロックを使用して無視され、キャプチャされる場合があります。 4)リソース管理のためのベストプラクティス:リソースを管理するためにステートメントとコンテキストマネージャーで使用することをお勧めします。
 PythonリストのPOP()関数の使用POP要素削除方法詳細な説明May 16, 2025 pm 12:30 PM
PythonリストのPOP()関数の使用POP要素削除方法詳細な説明May 16, 2025 pm 12:30 PMPOP()関数は、Pythonで使用され、リストから要素を削除し、指定された位置を返します。 1)インデックスが指定されていない場合、POP()はデフォルトでリストの最後の要素を削除および返します。 2)インデックスを指定するとき、POP()はインデックス位置で要素を削除および返します。 3)インデックスエラー、パフォーマンスの問題、代替方法、および使用時のリストの変動に注意してください。
 画像処理にPythonを使用する方法は?May 16, 2025 pm 12:27 PM
画像処理にPythonを使用する方法は?May 16, 2025 pm 12:27 PMPythonは、主に2つの主要なライブラリピローとOpenCVを使用して画像処理に使用しています。枕は、透かしの追加などの単純な画像処理に適しており、コードはシンプルで使いやすいです。 OpenCVは、優れたパフォーマンスを備えたエッジ検出などの複雑な画像処理とコンピュータービジョンに適していますが、メモリ管理に注意が必要です。
 Pythonで主成分分析を実装する方法は?May 16, 2025 pm 12:24 PM
Pythonで主成分分析を実装する方法は?May 16, 2025 pm 12:24 PMPythonでPCAの実装は、手動でコードを書くか、Scikit-Learnライブラリを使用して実行できます。 PCAの手動での実装には、次の手順が含まれます。1)データの集中、2)共分散行列の計算、3)固有値と固有ベクトルを計算し、4)主成分をソートして選択し、5)データを新しいスペースに投影します。手動の実装は、アルゴリズムを深く理解するのに役立ちますが、Scikit-Learnはより便利な機能を提供します。
 Pythonで対数を計算する方法は?May 16, 2025 pm 12:21 PM
Pythonで対数を計算する方法は?May 16, 2025 pm 12:21 PMPythonでの対数計算は非常にシンプルですが興味深いことです。最も基本的な質問から始めましょう:Pythonで対数を計算する方法は? Pythonで対数を計算する基本的な方法PythonのMath Moduleは、計算するための関数を提供します。簡単な例を見てみましょう:Importmath#自然対数(base is e)x = 10natural_log = math.log(x)print(f "natural log({x})= {natural_log}")#を計算します。
 Pythonで線形回帰を実装する方法は?May 16, 2025 pm 12:18 PM
Pythonで線形回帰を実装する方法は?May 16, 2025 pm 12:18 PMPythonで線形回帰を実装するには、複数の視点から開始できます。これは単なる機能呼び出しであるだけでなく、統計、数学的最適化、機械学習の包括的なアプリケーションを伴います。このプロセスに深く飛び込みましょう。 Pythonで線形回帰を実装する最も一般的な方法は、簡単で効率的なツールを提供するScikit-Learnライブラリを使用することです。ただし、線形回帰の原則と実装の詳細をより深く理解したい場合は、独自の線形回帰アルゴリズムをゼロから書くこともできます。 Scikit-Learnの線形回帰実装により、Scikit-Learnを使用して線形回帰の実装をカプセル化し、簡単にモデル化および予測できるようになります。これがSCの使用です


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

メモ帳++7.3.1
使いやすく無料のコードエディター

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

