


ビッグ データの世界に足を踏み入れようとしている人なら、強力な分散コンピューティング システムである Apache Spark について聞いたことがあるでしょう。 Apache Spark の Python ライブラリである PySpark は、速度、拡張性、使いやすさの組み合わせにより、データ愛好家の間で人気があります。ただし、ローカル マシンにセットアップするのは、最初は少し怖く感じるかもしれません。
心配する必要はありません。この記事ではプロセス全体を説明し、一般的な質問に対処し、可能な限り簡単に進められるようにします。
PySpark とは何ですか? なぜ気にする必要があるのですか?
インストールに入る前に、PySpark とは何かを理解しましょう。 PySpark を使用すると、Python を使用して Apache Spark の膨大な計算能力を活用できます。テラバイト規模のデータを分析する場合でも、機械学習モデルを構築する場合でも、ETL (Extract、Transform、Load) パイプラインを実行する場合でも、PySpark を使用すると、これまで以上に効率的にデータを取得できます。
PySpark について理解できたので、インストール プロセスを見てみましょう。
ステップ 1: システムが要件を満たしていることを確認する
PySpark は、Windows、macOS、Linux などのさまざまなマシン上で実行されます。正常にインストールするには次のものが必要です:
- Java 開発キット (JDK): PySpark には Java が必要です (バージョン 8 または 11 が推奨されます)。
- Python: Python 3.6 以降であることを確認してください。
- Apache Spark バイナリ: これはインストール プロセス中にダウンロードします。
システムの準備状況を確認するには:
- ターミナル または コマンド プロンプト を開きます。
- java -version および python —version と入力して、Java と Python のインストールを確認します。
Java または Python がインストールされていない場合は、次の手順に従います。
- Javaの場合: Oracle の公式 Web サイトからダウンロードします。
- Python の場合: Python のダウンロード ページにアクセスしてください。
ステップ 2: Java をインストールする
Java は Apache Spark のバックボーンです。インストールするには:
1.Java をダウンロード: Java SE Development Kit のダウンロード ページにアクセスします。オペレーティング システムに適切なバージョンを選択してください。
2.Java のインストール: インストーラーを実行し、プロンプトに従います。 Windows では、JAVA_HOME 環境変数を設定する必要があります。これを行うには:
- パス変数をコピーし、マシン上の ローカル ディスク に移動し、プログラム ファイル を選択して、Java フォルダーを探します開くと jdk-17 が表示されます(ご自身のバージョンは 17 ではない可能性があります)。それを開くと、パスが表示され、以下のようにコピーできます
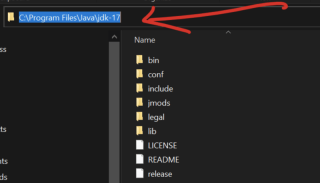
Windows の検索バーで 環境変数 を検索します。
システム変数 で、新規 をクリックし、変数名を JAVA_HOME に設定し、値を上でコピーした Java インストール パス (例: C:プログラムファイルJavajdk-17).
3.インストールの確認: ターミナル または コマンド プロンプト を開き、「java-version.
」と入力します。ステップ 3: Apache Spark をインストールする
1.Spark をダウンロード: Apache Spark の Web サイトにアクセスし、ニーズに合ったバージョンを選択します。 Hadoop 用の事前構築済みパッケージを使用します (Spark との一般的な組み合わせ)。
2.ファイルを抽出します:
- Windows では、WinRAR や 7-Zip などのツールを使用してファイルを抽出します。
- macOS/Linux では、コマンド tar -xvf smile-.tgz を使用します。
3.環境変数を設定します:
- Windowsの場合: Spark の bin ディレクトリをシステムの PATH 変数に追加します。
- macOS/Linux の場合: 次の行を .bashrc または .zshrc ファイルに追加します。 :
export SPARK_HOME=/path/to/spark export PATH=$SPARK_HOME/bin:$PATH
4.インストールの確認: ターミナルを開き、spark-shell と入力します。 Spark の対話型シェルが開始されるはずです。
ステップ 4: Hadoop をインストールする (オプションですが推奨)
Spark は厳密には Hadoop を必要としませんが、多くのユーザーは HDFS (Hadoop 分散ファイル システム) のサポートのためにそれをインストールします。 Hadoop をインストールするには:
- Apache Hadoop の Web サイトから Hadoop バイナリをダウンロードします。
- ファイルを抽出し、HADOOP_HOME 環境変数を設定します。
ステップ 5: pip 経由で PySpark をインストールする
PySpark のインストールは、Python の pip ツールを使用すると簡単です。次を実行するだけです:
pip install pyspark
確認するには、Python シェルを開いて次のように入力します。
pip install pysparkark.__version__)
バージョン番号が表示されたら、おめでとうございます! PySpark はインストールされていますか?
ステップ 6: PySpark インストールをテストする
ここからが楽しい始まりです。すべてがスムーズに機能していることを確認しましょう:
簡単なスクリプトを作成する:
テキスト エディターを開き、次のコードを貼り付けます:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("PySparkTest").getOrCreate()
data = [("Alice", 25), ("Bob", 30), ("Cathy", 29)]
columns = ["Name", "Age"]
df = spark.createDataFrame(data, columns)
df.show()
test_pyspark.py として保存します
スクリプトを実行します:
ターミナルで、スクリプトのディレクトリに移動し、次のように入力します:
export SPARK_HOME=/path/to/spark export PATH=$SPARK_HOME/bin:$PATH
名前と年齢を表示する、きちんとフォーマットされた表が表示されます。
一般的な問題のトラブルシューティング
最善の指示があっても、しゃっくりは起こります。よくある問題と解決策をいくつか示します:
問題: java.lang.NoClassDefFoundError
解決策: JAVA_HOME 変数と PATH 変数を再確認します。問題: PySpark のインストールは成功しましたが、テスト スクリプトは失敗しました。
解決策: 正しい Python バージョンを使用していることを確認してください。場合によっては、仮想環境によって競合が発生することがあります。問題:spark-shell コマンドが機能しません。
解決策: Spark ディレクトリが PATH に正しく追加されていることを確認します。
PySpark をローカルで使用する理由
多くのユーザーは、PySpark が主に分散システムで使用されているのに、なぜわざわざローカル マシンにインストールする必要があるのか疑問に思っています。その理由は次のとおりです:
- 学習: クラスターを必要とせずに、Spark の概念を実験して学習します。
- プロトタイピング: 小規模なデータ ジョブを大規模な環境に展開する前に、ローカルでテストします。
- 利便性: 問題をデバッグし、アプリケーションを簡単に開発できます。
PySpark の生産性を向上させる
PySpark を最大限に活用するには、次のヒントを考慮してください:
仮想環境のセットアップ: venv や conda などのツールを使用して、PySpark インストールを分離します。
IDE との統合: PyCharm や Jupyter Notebook などのツールにより、PySpark 開発がよりインタラクティブになります。
PySpark ドキュメントの活用: 詳細なガイダンスについては、Apache Spark のドキュメントにアクセスしてください。
PySpark コミュニティに参加する
特に PySpark のような強力なツールを使用する場合、行き詰まるのは普通のことです。活気に満ちた PySpark コミュニティに協力して支援を求めてください:
フォーラムに参加する: Stack Overflow のような Web サイトには専用の Spark タグがあります。
ミートアップに参加する: Spark および Python コミュニティは、学習やネットワークづくりができるイベントを主催することがよくあります。
ブログをフォローする: 多くのデータ専門家がオンラインで経験やチュートリアルを共有しています。
結論
ローカル マシンに PySpark をインストールするのは、最初は難しそうに思えるかもしれませんが、次の手順に従うと管理しやすく、やりがいのあるものになります。データの取り組みを始めたばかりの場合でも、スキルを磨いている場合でも、PySpark は現実世界のデータの問題に取り組むためのツールを提供します。
Apache Spark の Python API である PySpark は、データ分析と処理の革新をもたらします。その可能性は計り知れませんが、ローカル マシンにセットアップするのは難しく感じるかもしれません。この記事では、Java のインストールと Spark のダウンロードから、簡単なスクリプトによるセットアップのテストまで、プロセスを段階的に説明します。
PySpark をローカルにインストールすると、完全なクラスターを必要とせずに、データ ワークフローのプロトタイプを作成し、Spark の機能を学習し、小規模プロジェクトをテストできます。
以上がローカルマシンに PySpark をインストールする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Pythonリストをどのようにスライスしますか?May 02, 2025 am 12:14 AM
Pythonリストをどのようにスライスしますか?May 02, 2025 am 12:14 AMslicingapythonlistisdoneusingtheyntaxlist [start:stop:step] .hore'showitworks:1)startisthe indexofthefirstelementtoinclude.2)spotisthe indexofthefirmenttoeexclude.3)staptistheincrementbetbetinelements
 Numpyアレイで実行できる一般的な操作は何ですか?May 02, 2025 am 12:09 AM
Numpyアレイで実行できる一般的な操作は何ですか?May 02, 2025 am 12:09 AMnumpyallows forvariousoperationsonarrays:1)basicarithmeticlikeaddition、減算、乗算、および分割; 2)AdvancedperationssuchasmatrixMultiplication;
 Pythonを使用したデータ分析では、配列はどのように使用されていますか?May 02, 2025 am 12:09 AM
Pythonを使用したデータ分析では、配列はどのように使用されていますか?May 02, 2025 am 12:09 AMArraysinpython、特にnumpyandpandas、aresentialfordataanalysis、offeringspeedandeficiency.1)numpyarraysenable numpyarraysenable handling forlaredatasents andcomplexoperationslikemoverages.2)Pandasextendsnumpy'scapabivitieswithdataframesfortruc
 リストのメモリフットプリントは、Pythonの配列のメモリフットプリントとどのように比較されますか?May 02, 2025 am 12:08 AM
リストのメモリフットプリントは、Pythonの配列のメモリフットプリントとどのように比較されますか?May 02, 2025 am 12:08 AMlistsandnumpyarraysinpythonhavedifferentmemoryfootprints:listsaremoreflexiblellessmemory-efficient、whileenumpyarraysaraysareoptimizedfornumericaldata.1)listsstorereferencesto objects、with whowedaround64byteson64-bitedatigu
 実行可能なPythonスクリプトを展開するとき、環境固有の構成をどのように処理しますか?May 02, 2025 am 12:07 AM
実行可能なPythonスクリプトを展開するとき、環境固有の構成をどのように処理しますか?May 02, 2025 am 12:07 AMtoensurepythonscriptsbehaveCorrectlyAcrossDevelosment、staging、and Production、usetheseStrategies:1)環境variablesforsimplestetings、2)configurationfilesforcomplexsetups、and3)dynamicloadingforadaptability.eachtododododododofersuniquebentandrequiresca
 Pythonアレイをどのようにスライスしますか?May 01, 2025 am 12:18 AM
Pythonアレイをどのようにスライスしますか?May 01, 2025 am 12:18 AMPythonリストスライスの基本的な構文はリストです[start:stop:step]。 1.STARTは最初の要素インデックス、2。ストップは除外された最初の要素インデックスであり、3.ステップは要素間のステップサイズを決定します。スライスは、データを抽出するためだけでなく、リストを変更および反転させるためにも使用されます。
 どのような状況で、リストは配列よりもパフォーマンスが向上しますか?May 01, 2025 am 12:06 AM
どのような状況で、リストは配列よりもパフォーマンスが向上しますか?May 01, 2025 am 12:06 AMListSoutPerformArraysIn:1)ダイナミシジョンアンドフレーケンティオン/削除、2)ストーリングヘテロゼンダタ、および3)メモリ効率の装飾、ButmayhaveslightPerformancostsinceNASOPERATIONS。
 PythonアレイをPythonリストに変換するにはどうすればよいですか?May 01, 2025 am 12:05 AM
PythonアレイをPythonリストに変換するにはどうすればよいですか?May 01, 2025 am 12:05 AMtoconvertapythonarraytoalist、usetheList()constructororageneratorexpression.1)importhearraymoduleandcreateanarray.2)useList(arr)または[xforxinarr] toconvertoalistは、largedatatessを変えることを伴うものです。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境
ホットトピック
 7913
7913 15165214141152130325124829
15165214141152130325124829