
ホームページ >バックエンド開発 >Python チュートリアル >Python チュートリアル - ata 構造
Python チュートリアル - ata 構造

- DDDオリジナル
- 2024-12-23 19:36:15339ブラウズ
導入
データ構造はデータを整理するためのツールです。保管だけでなく、いくつかの問題の解決にも役立ちます。 Python にはリスト、辞書、タプル、セットなどのデータ構造がいくつかあります。
リスト
リストは、インデックスを使用して項目を順番に格納するデータ構造です。これはリストのデータ構造を示す図です。

Python でリストを作成する方法はたくさんあります。
- リスト内の値を直接初期化します。
items = [1,2,3,4]
- 空のリストを初期化します。
items = []
リスト内の項目には、インデックスを介して直接アクセスできます。
items = [1,2,3,4,5] # access item at index 2 result = items[2] print(result) # returns 3
リスト内のすべての項目は、for ループを使用して取得できます。これは一例です。
# create a new list
items = [1,2,3,4,5]
# retrieve each item inside a list
for item in items:
print(item)
出力
1 2 3 4 5
上記のコードに基づいて、項目が割り当てられた items というリストが作成されます。各項目は for ループを使用して取得されます。
リストの基本操作
append() 関数は、リストに新しい項目を追加します。これは append() の使用例です。
# create empty list
shopping_list = []
# add some items
shopping_list.append("apple")
shopping_list.append("milk")
shopping_list.append("cereal")
# retrieve all items
for item in shopping_list:
print(item)
出力
apple milk cereal
append() を下の図に示します。

append() 関数のほかに、insert() 関数は特定のインデックスに新しい項目を追加します。これは一例です。
items = ["apple","banana","mango","coffee"]
# add new item at index 1
items.insert(1,"cereal")
# retrieve all items
for item in items:
print(item)
出力
apple cereal banana mango coffee
insert() を下の図に示します。

リスト内の項目を更新するのは簡単です。項目のインデックスを指定して、更新された項目に変更するだけです。
# create a list
drinks = ["milkshake","black tea","banana milk","mango juice"]
# update value at index 2
drinks[2] = "chocolate milk"
print(f"value at index 2: {drinks[2]}")
出力
value at index 2: chocolate milk
remove() 関数はリストから項目を削除します。これは一例です。
items = ["apple","banana","mango","coffee"]
# remove "mango"
items.remove("mango")
# remove item at index 1
items.remove(items[1])
print("after removed")
for item in items:
print(item)
出力
after removed apple coffee
リスト内の項目は、リストの開始インデックスと終了インデックスを指定することで選択できます。これは、リスト内の項目を選択するための基本的な構造です。
list_name[start:end]
項目は開始インデックスから終了インデックスまで選択されますが、終了インデックスは含まれません。これはリスト内の項目を選択する例です。
items = ["apple","mango","papaya","coconut","banana"]
# select items from index 1 up to but not including index 3
selected = items[1:3]
# show all items
print(f"all items: {items}")
# show the selected items
print(f"selected: {selected}")
出力
all items: ['apple', 'mango', 'papaya', 'coconut', 'banana'] selected: ['mango', 'papaya']
リストの内包表記
リスト内包表記は、リストを作成する「機能的な」方法です。リストの内包理解を理解するために、反復アプローチを使用して偶数の値を含むリストを作成する例を見てみましょう。
evens = []
for i in range(1,11):
evens.append(i*2)
print(evens)
出力
items = [1,2,3,4]
上記のコードに基づいて、for ループを使用した反復アプローチを使用して偶数が生成されます。上記の例は、リスト内包表記を使用しても実現できます。これはリスト内包表記を使用して偶数を生成する例です。
items = []
出力
items = [1,2,3,4,5] # access item at index 2 result = items[2] print(result) # returns 3
上記のコードに基づいて、リスト内包アプローチはより簡潔なコードと、前の反復アプローチと同じ結果を提供します。
リスト内包表記は if 分岐と併用できます。この例では、リスト内包表記を使用して、特定の条件に基づいて特定の値をフィルター処理します。
# create a new list
items = [1,2,3,4,5]
# retrieve each item inside a list
for item in items:
print(item)
出力
1 2 3 4 5
これは、前の例の反復バージョンです。
# create empty list
shopping_list = []
# add some items
shopping_list.append("apple")
shopping_list.append("milk")
shopping_list.append("cereal")
# retrieve all items
for item in shopping_list:
print(item)
多次元リスト
リストは行列のような多次元アプローチで保存できます。これは、数値行列を格納するための多次元リストを宣言する例です。
apple milk cereal
項目には、メイン リストのインデックスを表す x を指定し、入れ子になったリスト内の項目のインデックスを表す y を指定することにより、二重角括弧 ([x][y]) でアクセスできます。これは数値行列の図です。
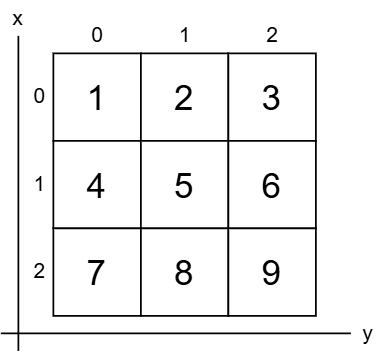
多次元リスト内の項目は、ネストされた for ループを利用して取得できます。
items = ["apple","banana","mango","coffee"]
# add new item at index 1
items.insert(1,"cereal")
# retrieve all items
for item in items:
print(item)
出力
apple cereal banana mango coffee
辞書
辞書は、レコードをキーと値のペアとして保存するデータ構造です。各キーは一意である必要がありますが、値の重複は許可されます。これは辞書のデータ構造を示しています:

辞書を作成するにはさまざまな方法があります:
- 初期化されたレコードを含む辞書を作成します。
# create a list
drinks = ["milkshake","black tea","banana milk","mango juice"]
# update value at index 2
drinks[2] = "chocolate milk"
print(f"value at index 2: {drinks[2]}")
- 空の辞書を作成します。
value at index 2: chocolate milk
辞書内のすべてのレコードは、for ループを使用して取得できます。これは一例です。
items = ["apple","banana","mango","coffee"]
# remove "mango"
items.remove("mango")
# remove item at index 1
items.remove(items[1])
print("after removed")
for item in items:
print(item)
出力
after removed apple coffee
辞書の基本操作
辞書内に新しい項目を挿入するには、項目のキーと値のペアを指定します。キーが一意であることを確認してください。
list_name[start:end]
これは、辞書内に新しい項目を挿入する例です。
items = ["apple","mango","papaya","coconut","banana"]
# select items from index 1 up to but not including index 3
selected = items[1:3]
# show all items
print(f"all items: {items}")
# show the selected items
print(f"selected: {selected}")
出力
all items: ['apple', 'mango', 'papaya', 'coconut', 'banana'] selected: ['mango', 'papaya']
辞書内の項目を更新するには、項目のキーを指定して、更新された値を挿入します。
evens = []
for i in range(1,11):
evens.append(i*2)
print(evens)
出力
[2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
辞書内のキーと値は、さまざまな方法を使用して個別にアクセスできます。
evens = [x*2 for x in range(1,11)] # using list comprehension print(evens)
出力
items = [1,2,3,4]
pop() メソッドは、指定されたキーに基づいて辞書から項目を削除します。
items = []
出力
items = [1,2,3,4,5] # access item at index 2 result = items[2] print(result) # returns 3
clear() メソッドは、辞書内のすべての項目を削除します。
# create a new list
items = [1,2,3,4,5]
# retrieve each item inside a list
for item in items:
print(item)
出力
1 2 3 4 5
タプル
タプルは、多くの値を格納するための不変のデータ構造です。タプルには変更可能な値が含まれる場合があります。新しいタプルを作成するには 2 つの方法があります。
- 値が割り当てられたタプルを作成します。
# create empty list
shopping_list = []
# add some items
shopping_list.append("apple")
shopping_list.append("milk")
shopping_list.append("cereal")
# retrieve all items
for item in shopping_list:
print(item)
出力
apple milk cereal
- 空のタプルを作成します。
items = ["apple","banana","mango","coffee"]
# add new item at index 1
items.insert(1,"cereal")
# retrieve all items
for item in items:
print(item)
タプルの基本操作
タプルは不変です。つまり、作成後に値を変更または更新することはできません。
apple cereal banana mango coffee
タプルの値は、「タプルのアンパック」を使用して取得できます (この概念は JavaScript のオブジェクトの構造化に似ています)。
アンパックするとき、アンパックされた値のサイズはタプルのサイズと等しくなければなりません。
# create a list
drinks = ["milkshake","black tea","banana milk","mango juice"]
# update value at index 2
drinks[2] = "chocolate milk"
print(f"value at index 2: {drinks[2]}")
出力
value at index 2: chocolate milk
セット
セットは、一意の項目のみを含む順序付けされていないデータ構造です。セットを作成するにはさまざまな方法があります。
items = ["apple","banana","mango","coffee"]
# remove "mango"
items.remove("mango")
# remove item at index 1
items.remove(items[1])
print("after removed")
for item in items:
print(item)
空のセットは set() 関数を使用して作成できます。
after removed apple coffee
設定されたデータ構造により、重複する値が自動的に削除されます。
list_name[start:end]
出力
items = ["apple","mango","papaya","coconut","banana"]
# select items from index 1 up to but not including index 3
selected = items[1:3]
# show all items
print(f"all items: {items}")
# show the selected items
print(f"selected: {selected}")
セット内の値には、for ループを使用してアクセスできます。
all items: ['apple', 'mango', 'papaya', 'coconut', 'banana'] selected: ['mango', 'papaya']
出力
evens = []
for i in range(1,11):
evens.append(i*2)
print(evens)
基本操作の設定
セットのデータ構造は、和集合、交差、差分、対称差分などの多くの演算を提供します。
結合演算は、両方のセット内のすべての項目を返します。

[2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
出力
evens = [x*2 for x in range(1,11)] # using list comprehension print(evens)
交差演算は、セットの交差に存在するすべての項目を返します。

[2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
出力
samples = [12,32,55,10,2,57,66] result = [s for s in samples if s % 4 == 0] # using list comprehension print(result)
差分演算は、特定のセットにのみ存在するすべての項目を返します。

[12, 32]
出力
samples = [12,32,55,10,2,57,66]
result = []
for s in samples:
if s % 4 == 0:
result.append(s)
print(result)
対称差分演算は、いずれかのセットに存在するが交差部分には存在しないすべての項目を返します。

matrix = [ [1,2,3], [4,5,6], [7,8,9], ]
出力
items = [1,2,3,4]
機能の紹介
この関数は、コードの重複を減らし、複雑なタスクを整理することを目的とした命令を含む呼び出し可能なユニットです。 void 関数 (戻り値なし) と値を返す関数の 2 種類があります。
これは Python の関数の基本構造です。
items = []
これは、Python の void 関数 (戻り値なし) の例です。
items = [1,2,3,4,5] # access item at index 2 result = items[2] print(result) # returns 3
出力
# create a new list
items = [1,2,3,4,5]
# retrieve each item inside a list
for item in items:
print(item)
上記のコードに基づいて、hello() という関数が作成されます。関数名に括弧 () を付けて指定することで関数を呼び出します。
これは戻り値のある関数の例です。
1 2 3 4 5
出力
# create empty list
shopping_list = []
# add some items
shopping_list.append("apple")
shopping_list.append("milk")
shopping_list.append("cereal")
# retrieve all items
for item in shopping_list:
print(item)
上記のコードに基づいて、2 つの数値を合計する add() という関数が作成されます。 add() 関数の戻り値は結果変数内に格納されます。
戻り値関数を使用する場合は、戻り値が使用されていることを確認してください。
Python の関数のトピックについては、別の章で詳しく説明します。
例 - シンプルな Todo リスト アプリケーション
簡単な ToDo リスト アプリケーションを作成してみましょう。このアプリケーションはリストを todo のストレージとして使用し、関数を利用してよりクリーンなコードを実現します。
最初のステップは、uuid パッケージをインポートし、todo レコードを保存するための todos というリストを作成することです。 uuid パッケージは、todo レコードの識別子 (ID) として使用されます。
apple milk cereal
その後、すべての todo レコードを取得する view_todos() 関数を作成します。すべての todo レコードは for ループを使用して取得されます。
items = ["apple","banana","mango","coffee"]
# add new item at index 1
items.insert(1,"cereal")
# retrieve all items
for item in items:
print(item)
指定された ID で todo レコードを取得する view_todo() 関数を作成します。各 todo レコードは for ループ内でチェックされ、現在の todo ID が指定された ID と等しいかどうかがチェックされます。一致する場合、ToDo レコードが表示されます。
apple cereal banana mango coffee
新しい todo を作成する create_todo() 関数を作成します。 todo レコードは、id と title フィールドを持つ辞書として表されます。
# create a list
drinks = ["milkshake","black tea","banana milk","mango juice"]
# update value at index 2
drinks[2] = "chocolate milk"
print(f"value at index 2: {drinks[2]}")
todo を更新する update_todo() 関数を作成します。この関数では、指定したIDでtodoレコードを更新します。
value at index 2: chocolate milk
todo を削除する delete_todo() 関数を作成します。この関数では、指定したIDでtodoレコードを削除します。
items = ["apple","banana","mango","coffee"]
# remove "mango"
items.remove("mango")
# remove item at index 1
items.remove(items[1])
print("after removed")
for item in items:
print(item)
最後に、アプリケーションのメイン メニューを表示するために、display_menu() という関数を作成します。
after removed apple coffee
これは完全なコードです。
list_name[start:end]
これはアプリケーションの出力です。

情報源
- Python のデータ構造。
この記事が Python の学習に役立つことを願っています。ご意見がございましたら、コメント欄にご記入ください。
以上がPython チュートリアル - ata 構造の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。