


コーヒー買ってきて☕
*私の投稿では EMNIST について説明しています。
EMNIST() は、以下に示すように EMNIST データセットを使用できます。
*メモ:
- 最初の引数は root(Required-Type:str または pathlib.Path) です。 *絶対パスまたは相対パスが可能です。
- 2番目の引数はsplit(Required-Type:str)です。 ※「byclass」、「bymerge」、「balances」、「letters」、「digital」、「mnist」が設定可能です。
- train 引数があります (Optional-Default:False-Type:float):
*メモ:
- split="byclass"とsplit="byclass"の場合、Trueの場合はトレーニングデータ(697,932枚)が使用され、Falseの場合はテストデータ(116,323枚)が使用されます。
- split="framed" の場合、True の場合はトレーニング データ (112,800 画像) が使用され、False の場合はテスト データ (188,00 画像) が使用されます。
- split="letters" の場合、True の場合はトレーニング データ (124,800 画像) が使用され、False の場合はテスト データ (20,800 画像) が使用されます。
- split="digits" の場合、True の場合はトレーニングデータ (240,000 画像) が使用され、False の場合はテストデータ (40,000 画像) が使用されます。
- split="mnist" の場合、True の場合はトレーニング データ (60,000 画像) が使用され、False の場合はテスト データ (10,000 画像) が使用されます。
- 変換引数(Optional-Default:None-Type:callable)があります。
- target_transform引数(Optional-Default:None-Type:callable)があります。
- ダウンロード引数があります(Optional-Default:False-Type:bool):
*メモ:
- True の場合、データセットはインターネットからダウンロードされ、ルートに抽出 (解凍) されます。
- これが True で、データセットが既にダウンロードされている場合、データセットは抽出されます。
- これが True で、データセットがすでにダウンロードされ抽出されている場合は、何も起こりません。
- データセットがすでにダウンロードされ抽出されている場合は、その方が高速であるため、False にする必要があります。
- ここからデータセットを手動でダウンロードして抽出できます。データ/EMNIST/生/.
- デフォルトでは画像が反転して反時計回りに90度回転してしまうバグがあるため、変換する必要があります。
from torchvision.datasets import EMNIST
train_data = EMNIST(
root="data",
split="byclass"
)
train_data = EMNIST(
root="data",
split="byclass",
train=True,
transform=None,
target_transform=None,
download=False
)
test_data = EMNIST(
root="data",
split="byclass",
train=False
)
len(train_data), len(test_data)
# 697932 116323
train_data
# Dataset EMNIST
# Number of datapoints: 697932
# Root location: data
# Split: Train
train_data.root
# 'data'
train_data.split
# 'byclass'
train_data.train
# True
print(train_data.transform)
# None
print(train_data.target_transform)
# None
train_data.download
# <bound method emnist.download of dataset emnist number datapoints: root location: data split: train>
train_data[0]
# (<pil.image.image image mode="L" size="28x28">, 35)
train_data[1]
# (<pil.image.image image mode="L" size="28x28">, 36)
train_data[2]
# (<pil.image.image image mode="L" size="28x28">, 6)
train_data[3]
# (<pil.image.image image mode="L" size="28x28">, 3)
train_data[4]
# (<pil.image.image image mode="L" size="28x28">, 22)
train_data.classes
# ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
# 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M',
# 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z',
# 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm',
# 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
</pil.image.image></pil.image.image></pil.image.image></pil.image.image></pil.image.image></bound>
from torchvision.datasets import EMNIST
train_data = EMNIST(
root="data",
split="byclass",
train=True
)
test_data = EMNIST(
root="data",
split="byclass",
train=False
)
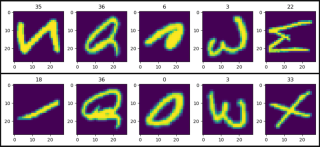
import matplotlib.pyplot as plt
def show_images(data):
plt.figure(figsize=(12, 2))
col = 5
for i, (image, label) in enumerate(data, 1):
plt.subplot(1, col, i)
plt.title(label)
plt.imshow(image)
if i == col:
break
plt.show()
show_images(data=train_data)
show_images(data=test_data)
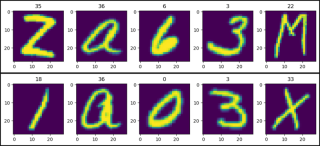
from torchvision.datasets import EMNIST
from torchvision.transforms import v2
train_data = EMNIST(
root="data",
split="byclass",
train=True,
transform=v2.Compose([
v2.RandomHorizontalFlip(p=1.0),
v2.RandomRotation(degrees=(90, 90))
])
)
test_data = EMNIST(
root="data",
split="byclass",
train=False,
transform=v2.Compose([
v2.RandomHorizontalFlip(p=1.0),
v2.RandomRotation(degrees=(90, 90))
])
)
import matplotlib.pyplot as plt
def show_images(data):
plt.figure(figsize=(12, 2))
col = 5
for i, (image, label) in enumerate(data, 1):
plt.subplot(1, col, i)
plt.title(label)
plt.imshow(image)
if i == col:
break
plt.show()
show_images(data=train_data)
show_images(data=test_data)
以上がPyTorch の EMNISTの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 HTMLを解析するために美しいスープを使用するにはどうすればよいですか?Mar 10, 2025 pm 06:54 PM
HTMLを解析するために美しいスープを使用するにはどうすればよいですか?Mar 10, 2025 pm 06:54 PMこの記事では、Pythonライブラリである美しいスープを使用してHTMLを解析する方法について説明します。 find()、find_all()、select()、およびget_text()などの一般的な方法は、データ抽出、多様なHTML構造とエラーの処理、および代替案(SEL
 LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?Apr 01, 2025 pm 05:09 PMLinuxターミナルでPythonバージョンを表示する際の許可の問題の解決策PythonターミナルでPythonバージョンを表示しようとするとき、Pythonを入力してください...
 Pythonの数学モジュール:統計Mar 09, 2025 am 11:40 AM
Pythonの数学モジュール:統計Mar 09, 2025 am 11:40 AMPythonの統計モジュールは、強力なデータ統計分析機能を提供して、生物統計やビジネス分析などのデータの全体的な特性を迅速に理解できるようにします。データポイントを1つずつ見る代わりに、平均や分散などの統計を見て、無視される可能性のある元のデータの傾向と機能を発見し、大きなデータセットをより簡単かつ効果的に比較してください。 このチュートリアルでは、平均を計算し、データセットの分散の程度を測定する方法を説明します。特に明記しない限り、このモジュールのすべての関数は、単に平均を合計するのではなく、平均()関数の計算をサポートします。 浮動小数点数も使用できます。 ランダムをインポートします インポート統計 fractiから
 Pythonオブジェクトのシリアル化と脱介入:パート1Mar 08, 2025 am 09:39 AM
Pythonオブジェクトのシリアル化と脱介入:パート1Mar 08, 2025 am 09:39 AMPythonオブジェクトのシリアル化と脱介入は、非自明のプログラムの重要な側面です。 Pythonファイルに何かを保存すると、構成ファイルを読み取る場合、またはHTTPリクエストに応答する場合、オブジェクトシリアル化と脱滑り化を行います。 ある意味では、シリアル化と脱派化は、世界で最も退屈なものです。これらすべての形式とプロトコルを気にするのは誰ですか? Pythonオブジェクトを維持またはストリーミングし、後で完全に取得したいと考えています。 これは、概念レベルで世界を見るのに最適な方法です。ただし、実用的なレベルでは、選択したシリアル化スキーム、形式、またはプロトコルは、プログラムの速度、セキュリティ、メンテナンスの自由、およびその他の側面を決定する場合があります。
 TensorflowまたはPytorchで深い学習を実行する方法は?Mar 10, 2025 pm 06:52 PM
TensorflowまたはPytorchで深い学習を実行する方法は?Mar 10, 2025 pm 06:52 PMこの記事では、深い学習のためにTensorflowとPytorchを比較しています。 関連する手順、データの準備、モデルの構築、トレーニング、評価、展開について詳しく説明しています。 特に計算グラップに関して、フレームワーク間の重要な違い
 美しいスープでPythonでWebページを削る:検索とDOMの変更Mar 08, 2025 am 10:36 AM
美しいスープでPythonでWebページを削る:検索とDOMの変更Mar 08, 2025 am 10:36 AMこのチュートリアルは、単純なツリーナビゲーションを超えたDOM操作に焦点を当てた、美しいスープの以前の紹介に基づいています。 HTML構造を変更するための効率的な検索方法と技術を探ります。 1つの一般的なDOM検索方法はExです
 人気のあるPythonライブラリとその用途は何ですか?Mar 21, 2025 pm 06:46 PM
人気のあるPythonライブラリとその用途は何ですか?Mar 21, 2025 pm 06:46 PMこの記事では、numpy、pandas、matplotlib、scikit-learn、tensorflow、django、flask、and requestsなどの人気のあるPythonライブラリについて説明し、科学的コンピューティング、データ分析、視覚化、機械学習、Web開発、Hの使用について説明します。
 Pythonでコマンドラインインターフェイス(CLI)を作成する方法は?Mar 10, 2025 pm 06:48 PM
Pythonでコマンドラインインターフェイス(CLI)を作成する方法は?Mar 10, 2025 pm 06:48 PMこの記事では、コマンドラインインターフェイス(CLI)の構築に関するPython開発者をガイドします。 Typer、Click、Argparseなどのライブラリを使用して、入力/出力の処理を強調し、CLIの使いやすさを改善するためのユーザーフレンドリーな設計パターンを促進することを詳述しています。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 中国語版
中国語版、とても使いやすい

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

ドリームウィーバー CS6
ビジュアル Web 開発ツール

WebStorm Mac版
便利なJavaScript開発ツール
ホットトピック
 7413
7413 15135952
15135952