
ホームページ >バックエンド開発 >Python チュートリアル >Python で Google 検索結果をスクレイピングする方法
Python で Google 検索結果をスクレイピングする方法

- Susan Sarandonオリジナル
- 2024-12-05 12:31:10616ブラウズ
Google 検索のスクレイピングは、重要な SERP 分析、SEO 最適化、データ収集機能を提供します。最新のスクレイピング ツールにより、このプロセスがより高速になり、信頼性が高まります。
私たちのコミュニティ メンバーの 1 人が、Crawlee Blog への寄稿としてこのブログを書きました。このようなブログを Crawlee Blog に投稿したい場合は、Discord チャンネルまでご連絡ください。
このガイドでは、Crawlee for Python を使用して、結果のランキングとページネーションを処理できる Google 検索スクレイパーを作成します。
次のようなスクレーパーを作成します。
- 検索結果からタイトル、URL、説明を抽出します
- 複数の検索クエリを処理します
- ランキング順位を追跡
- 複数の結果ページを処理します
- データを構造化形式で保存します
前提条件
- Python 3.7 以降
- HTML および CSS セレクターの基本的な理解
- Web スクレイピングの概念についての知識
- Crawlee for Python v0.4.2 以降
プロジェクトのセットアップ
-
必要な依存関係を含む Crawlee をインストールします:
pipx install crawlee[beautifulsoup,curl-impersonate]
-
Crawlee CLI を使用して新しいプロジェクトを作成します:
pipx run crawlee create crawlee-google-search
プロンプトが表示されたら、テンプレートの種類として Beautifulsoup を選択します。
-
プロジェクト ディレクトリに移動し、インストールを完了します。
cd crawlee-google-search poetry install
Python での Google 検索スクレイパーの開発
1. 抽出するデータの定義
まず、抽出範囲を定義しましょう。 Google の検索結果には、地図、著名人、企業詳細、ビデオ、よくある質問、その他多くの要素が含まれるようになりました。ランキングを使用した標準的な検索結果の分析に焦点を当てます。
抽出する内容は次のとおりです:

ページの HTML コードから必要なデータを抽出できるかどうか、またはより詳細な分析や JS レンダリングが必要かどうかを確認してみましょう。この検証は HTML タグに依存することに注意してください:

ページから取得したデータに基づいて、必要な情報はすべて HTML コード内に存在します。したがって、 beautifulsoup_crawler を使用できます。
抽出するフィールド:
- 検索結果のタイトル
- URL
- 説明テキスト
- ランキング順位
2. クローラーを設定する
まず、クローラ設定を作成しましょう。
プリセットヘッダーを持つ http_client として CurlImpersonateHttpClient を使用し、Chrome ブラウザーに関連する偽装を行います。
スクレイピングの積極性を制御するために ConcurrencySettings も構成します。これは、Google によるブロックを避けるために非常に重要です。
より集中的にデータを抽出する必要がある場合は、ProxyConfiguration のセットアップを検討してください。
pipx install crawlee[beautifulsoup,curl-impersonate]
3. データ抽出の実装
まず、抽出する必要がある要素の HTML コードを分析しましょう。

読み取り可能な ID 属性と、生成された クラス名およびその他の属性の間には明らかな違いがあります。データ抽出用のセレクターを作成する場合は、生成された属性を無視する必要があります。 Google が特定の生成されたタグを N 年間使用していると読んだとしても、それに依存すべきではありません。これは、堅牢なコードを作成する際のあなたの経験を反映しています。
HTML 構造を理解したので、抽出を実装しましょう。クローラーは 1 種類のページのみを処理するため、処理には router.default_handler を使用できます。ハンドラー内で BeautifulSoup を使用して各検索結果を反復処理し、結果を保存しながらタイトル、URL、text_widget などのデータを抽出します。
pipx run crawlee create crawlee-google-search
4. ページネーションの処理
Google の結果は検索リクエストの IP 地理位置情報に依存するため、ページネーションのリンク テキストに依存することはできません。地理位置情報や言語設定に関係なく機能する、より洗練された CSS セレクターを作成する必要があります。
max_crawl_ Depth パラメータは、クローラがスキャンするページ数を制御します。堅牢なセレクターを作成したら、次のページのリンクを取得してクローラーのキューに追加するだけです。
より効率的なセレクターを作成するには、CSS と XPath 構文の基本を学習してください。
cd crawlee-google-search poetry install
5. CSV形式でデータをエクスポートする
すべての検索結果データを CSV などの便利な表形式で保存したいため、クローラーを実行した直後に、export_data メソッド呼び出しを追加するだけです。
from crawlee.beautifulsoup_crawler import BeautifulSoupCrawler
from crawlee.http_clients.curl_impersonate import CurlImpersonateHttpClient
from crawlee import ConcurrencySettings, HttpHeaders
async def main() -> None:
concurrency_settings = ConcurrencySettings(max_concurrency=5, max_tasks_per_minute=200)
http_client = CurlImpersonateHttpClient(impersonate="chrome124",
headers=HttpHeaders({"referer": "https://www.google.com/",
"accept-language": "en",
"accept-encoding": "gzip, deflate, br, zstd",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}))
crawler = BeautifulSoupCrawler(
max_request_retries=1,
concurrency_settings=concurrency_settings,
http_client=http_client,
max_requests_per_crawl=10,
max_crawl_depth=5
)
await crawler.run(['https://www.google.com/search?q=Apify'])
6. Google 検索スクレイパーの完成
コア クローラー ロジックは機能していますが、現在の結果にはランキング順位の情報が欠けていることにお気付きかもしれません。スクレイパーを完成させるには、Request の user_data を使用してリクエスト間でデータを渡し、適切なランキング位置追跡を実装する必要があります。
複数のクエリを処理し、検索結果分析のためにランキングの位置を追跡するようにスクリプトを変更しましょう。また、クロールの深さをトップレベルの変数として設定します。プロジェクト構造と一致するように、router.default_handler を Routes.py に移動しましょう:
@crawler.router.default_handler
async def default_handler(context: BeautifulSoupCrawlingContext) -> None:
"""Default request handler."""
context.log.info(f'Processing {context.request} ...')
for item in context.soup.select("div#search div#rso div[data-hveid][lang]"):
data = {
'title': item.select_one("h3").get_text(),
"url": item.select_one("a").get("href"),
"text_widget": item.select_one("div[style*='line']").get_text(),
}
await context.push_data(data)
ハンドラーを変更して、query フィールドと order_no フィールド、および基本的なエラー処理を追加しましょう。
await context.enqueue_links(selector="div[role='navigation'] td[role='heading']:last-of-type > a")
これで完了です!
Google 検索クローラーの準備が整いました。 google_ranked.csv ファイルの結果を見てみましょう:
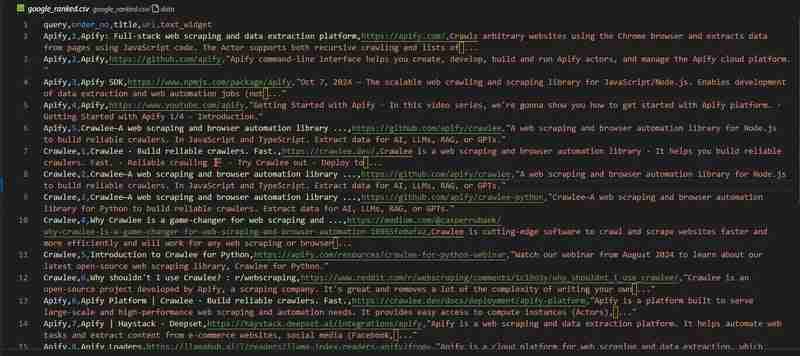
コード リポジトリは GitHub で入手できます
Apify で Google 検索結果をスクレイピング
Google ランキング分析に関するこの記事で紹介されているプロジェクトのように、数百万のデータ ポイントを必要とする大規模なプロジェクトに取り組んでいる場合は、既製のソリューションが必要になる可能性があります。
Apify チームによる Google 検索結果スクレイパーの使用を検討してください。
次のような重要な機能を提供します。
- プロキシのサポート
- 大規模なデータ抽出のためのスケーラビリティ
- 地理位置情報制御
- Zapier、Make、Airbyte、LangChain などの外部サービスとの統合
Apify ブログで詳細をご覧いただけます
何を削りますか?
このブログでは、ランキング データを収集する Google 検索クローラーの作成方法を段階的に説明してきました。このデータセットをどのように分析するかはあなた次第です!
念のため、完全なプロジェクト コードは GitHub で見つけることができます。
5 年後には「LLM に最適な検索エンジンからデータを抽出する方法」に関する記事を書く必要があると考えていますが、この記事は 5 年後もまだ意味があると思います。
以上がPython で Google 検索結果をスクレイピングする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。