


導入
私は現在、強力なオープンソースのクリエイティブな描画ボードを保守しています。この描画ボードには、興味深いブラシと描画補助機能が多数統合されており、ユーザーは新しい描画効果を体験できます。モバイルでも PC でも、より優れたインタラクティブなエクスペリエンスとエフェクト表示をお楽しみいただけます。
この記事では、Transformers.js を組み合わせて背景の削除と画像マーキングのセグメンテーションを実現する方法を詳しく説明します。結果は以下の通りです

リンク: https://songlh.top/paint-board/
Github: https://github.com/LHRUN/paint-board Star ⭐️へようこそ
トランスフォーマー.js
Transformers.js は、Hugging Face の Transformers をベースにした強力な JavaScript ライブラリで、サーバー側の計算に依存せずにブラウザーで直接実行できます。つまり、モデルをローカルで実行できるため、効率が向上し、導入とメンテナンスのコストが削減されます。
現在、Transformers.js は Hugging Face で 1000 のモデルを提供しており、さまざまな領域をカバーしており、画像処理、テキスト生成、翻訳、感情分析、その他のタスク処理などのほとんどのニーズを満たすことができ、Transformers を通じて簡単に実現できます。 .js。以下のようにモデルを検索します。
Transformers.js の現在のメジャー バージョンは V3 に更新され、多くの優れた機能が追加されました。詳細: Transformers.js v3: WebGPU サポート、新しいモデルとタスクなど…
この記事に追加した両方の機能は、V3 でのみ利用できる WebGpu サポートを使用しており、処理速度が大幅に向上し、ミリ秒単位で解析できるようになりました。ただし、WebGPU をサポートするブラウザは多くないため、最新バージョンの Google を使用してアクセスすることをお勧めします。
機能 1: 背景を削除する
背景を削除するには、次のような Xenova/modnet モデルを使用します
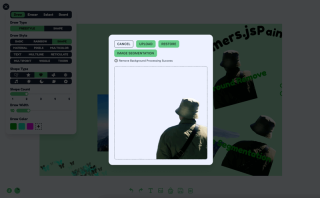
処理ロジックは 3 つのステップに分けることができます
- 状態を初期化し、モデルとプロセッサをロードします。
- インターフェースの表示。これは私のデザインではなく、あなた自身のデザインに基づいています。
- エフェクトを表示します。これは私のデザインではなく、あなた自身のデザインに基づいています。現在では、境界線を使用して、背景を削除する前後のコントラスト効果を動的に表示することが一般的です。
コードロジックは次のとおりです。 React TS 、詳細についてはプロジェクトのソースコードを参照してください。ソースコードは src/components/boardOperation/uploadImage/index.tsx にあります
import { useState, FC, useRef, useEffect, useMemo } from 'react'
import {
env,
AutoModel,
AutoProcessor,
RawImage,
PreTrainedModel,
Processor
} from '@huggingface/transformers'
const REMOVE_BACKGROUND_STATUS = {
LOADING: 0,
NO_SUPPORT_WEBGPU: 1,
LOAD_ERROR: 2,
LOAD_SUCCESS: 3,
PROCESSING: 4,
PROCESSING_SUCCESS: 5
}
type RemoveBackgroundStatusType =
(typeof REMOVE_BACKGROUND_STATUS)[keyof typeof REMOVE_BACKGROUND_STATUS]
const UploadImage: FC = ({ url }) => {
const [removeBackgroundStatus, setRemoveBackgroundStatus] =
useState<removebackgroundstatustype>()
const [processedImage, setProcessedImage] = useState('')
const modelRef = useRef<pretrainedmodel>()
const processorRef = useRef<processor>()
const removeBackgroundBtnTip = useMemo(() => {
switch (removeBackgroundStatus) {
case REMOVE_BACKGROUND_STATUS.LOADING:
return 'Remove background function loading'
case REMOVE_BACKGROUND_STATUS.NO_SUPPORT_WEBGPU:
return 'WebGPU is not supported in this browser, to use the remove background function, please use the latest version of Google Chrome'
case REMOVE_BACKGROUND_STATUS.LOAD_ERROR:
return 'Remove background function failed to load'
case REMOVE_BACKGROUND_STATUS.LOAD_SUCCESS:
return 'Remove background function loaded successfully'
case REMOVE_BACKGROUND_STATUS.PROCESSING:
return 'Remove Background Processing'
case REMOVE_BACKGROUND_STATUS.PROCESSING_SUCCESS:
return 'Remove Background Processing Success'
default:
return ''
}
}, [removeBackgroundStatus])
useEffect(() => {
;(async () => {
try {
if (removeBackgroundStatus === REMOVE_BACKGROUND_STATUS.LOADING) {
return
}
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOADING)
// Checking WebGPU Support
if (!navigator?.gpu) {
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.NO_SUPPORT_WEBGPU)
return
}
const model_id = 'Xenova/modnet'
if (env.backends.onnx.wasm) {
env.backends.onnx.wasm.proxy = false
}
// Load model and processor
modelRef.current ??= await AutoModel.from_pretrained(model_id, {
device: 'webgpu'
})
processorRef.current ??= await AutoProcessor.from_pretrained(model_id)
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOAD_SUCCESS)
} catch (err) {
console.log('err', err)
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOAD_ERROR)
}
})()
}, [])
const processImages = async () => {
const model = modelRef.current
const processor = processorRef.current
if (!model || !processor) {
return
}
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.PROCESSING)
// load image
const img = await RawImage.fromURL(url)
// Pre-processed image
const { pixel_values } = await processor(img)
// Generate image mask
const { output } = await model({ input: pixel_values })
const maskData = (
await RawImage.fromTensor(output[0].mul(255).to('uint8')).resize(
img.width,
img.height
)
).data
// Create a new canvas
const canvas = document.createElement('canvas')
canvas.width = img.width
canvas.height = img.height
const ctx = canvas.getContext('2d') as CanvasRenderingContext2D
// Draw the original image
ctx.drawImage(img.toCanvas(), 0, 0)
// Updating the mask area
const pixelData = ctx.getImageData(0, 0, img.width, img.height)
for (let i = 0; i
<button classname="{`btn" btn-primary btn-sm remove_background_status.load_success remove_background_status.processing_success undefined : onclick="{processImages}">
Remove background
</button>
<div classname="text-xs text-base-content mt-2 flex">
{removeBackgroundBtnTip}
</div>
<div classname="relative mt-4 border border-base-content border-dashed rounded-lg overflow-hidden">
<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/000/173262759935552.jpg?x-oss-process=image/resize,p_40" class="lazy" classname="{`w-[50vw]" max-w- h- max-h- object-contain alt="Canvas シリーズの探索: Transformers.js と組み合わせてインテリジェントな画像処理を実現" >
{processedImage && (
<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/000/173262759935552.jpg?x-oss-process=image/resize,p_40" class="lazy" classname="{`w-full" h-full absolute top-0 left-0 z- object-contain alt="Canvas シリーズの探索: Transformers.js と組み合わせてインテリジェントな画像処理を実現" >
)}
</div>
)
}
export default UploadImage
</processor></pretrainedmodel></removebackgroundstatustype>
機能 2: 画像マーカーのセグメント化
画像マーカーのセグメンテーションは、Xenova/slimsam-77-uniform モデルを使用して実装されています。効果は次のとおりです。画像が読み込まれた後に画像をクリックすると、クリックした座標に応じてセグメンテーションが生成されます。
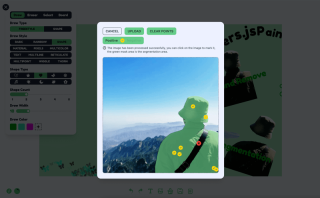
処理ロジックは 5 つのステップに分けることができます
- 状態を初期化し、モデルとプロセッサをロードします
- 画像を取得して読み込み、画像の読み込みデータと埋め込みデータを保存します。
- 画像のクリック イベントをリッスンし、クリック データを記録し、ポジティブ マーカーとネガティブ マーカーに分けます。各クリック後、デコードされたクリック データに従ってマスク データを生成し、マスク データに従ってセグメンテーション効果を描画します。 .
- インターフェース表示、これはあなた自身のデザインの恣意的な遊びであり、私の優先ではありません
- クリックして画像を保存し、マスクピクセルデータに従って元の画像データと一致させ、キャンバス描画を通じてエクスポートします
コードロジックは次のとおりです。 React TS 、詳細についてはプロジェクトのソースコードを参照してください。ソースコードは src/components/boardOperation/uploadImage/imageSegmentation.tsx にあります
import { useState, useRef, useEffect, useMemo, MouseEvent, FC } from 'react'
輸入 {
サムモデル、
オートプロセッサー、
生画像、
事前トレーニング済みモデル、
プロセッサー、
テンソル、
SamImageProcessor結果
} '@huggingface/transformers' より
'@/components/icons/loading.svg?react' から LoadingIcon をインポートします
「@/components/icons/boardOperation/image-segmentation-positive.svg?react」から PositiveIcon をインポートします
「@/components/icons/boardOperation/image-segmentation-negative.svg?react」から NegativeIcon をインポートします
インターフェースMarkPoint {
位置: 番号[]
ラベル: 番号
}
const SEGMENTATION_STATUS = {
読み込み中: 0、
NO_SUPPORT_WEBGPU: 1、
ロードエラー: 2、
LOAD_SUCCESS: 3、
処理: 4、
処理_成功: 5
}
type SegmentationStatusType =
(SEGMENTATION_STATUS のタイプ)[SEGMENTATION_STATUS のタイプのキー]
const ImageSegmentation: FC = ({ url }) => {
const [markPoints, setMarkPoints] = useState<markpoint>([])
const [segmentationStatus, setSegmentationStatus] =
useState<segmentationstatustype>()
const [pointStatus, setPointStatus] = useState<boolean>(true)
const MaskCanvasRef = useRef<htmlcanvaselement>(null) // セグメンテーション マスク
const modelRef = useRef<pretrainedmodel>() // モデル
constprocessorRef = useRef<processor>() // プロセッサ
const imageInputRef = useRef<rawimage>() // 元の画像
const imageProcessed = useRef<samimageprocessorresult>() // 処理された画像
const imageEmbeddings = useRef<tensor>() // データの埋め込み
constセグメンテーションヒント = useMemo(() => {
switch (segmentationStatus) {
SEGMENTATION_STATUS.LOADING の場合:
return '画像分割機能読み込み中'
SEGMENTATION_STATUS.NO_SUPPORT_WEBGPU の場合:
return 'このブラウザでは WebGPU がサポートされていません。画像分割機能を使用するには、最新バージョンの Google Chrome を使用してください。'
SEGMENTATION_STATUS.LOAD_ERROR の場合:
return '画像セグメンテーション関数のロードに失敗しました'
SEGMENTATION_STATUS.LOAD_SUCCESS の場合:
return '画像分割機能が正常にロードされました'
ケース SEGMENTATION_STATUS.PROCESSING:
return '画像処理中...'
SEGMENTATION_STATUS.PROCESSING_SUCCESS の場合:
return '画像は正常に処理されました。画像をクリックしてマークを付けることができます。緑色のマスク領域がセグメンテーション領域です。'
デフォルト:
戻る ''
}
}, [セグメンテーションステータス])
// 1. モデルとプロセッサをロードします
useEffect(() => {
;(async () => {
試す {
if (segmentationStatus === SEGMENTATION_STATUS.LOADING) {
戻る
}
setSegmentationStatus(SEGMENTATION_STATUS.LOADING)
if (!navigator?.gpu) {
setSegmentationStatus(SEGMENTATION_STATUS.NO_SUPPORT_WEBGPU)
戻る
}const model_id = 'Xenova/slimsam-77-uniform'
modelRef.current ??= await SamModel.from_pretrained(model_id, {
dtype: 'fp16'、// または "fp32"
デバイス: 「webgpu」
})
processorRef.current ??= await AutoProcessor.from_pretrained(model_id)
setSegmentationStatus(SEGMENTATION_STATUS.LOAD_SUCCESS)
} キャッチ (エラー) {
console.log('エラー', エラー)
setSegmentationStatus(SEGMENTATION_STATUS.LOAD_ERROR)
}
})()
}、[])
// 2.画像処理
useEffect(() => {
;(async () => {
試す {
もし (
!modelRef.current ||
!processorRef.current ||
!url ||
セグメンテーションステータス === SEGMENTATION_STATUS.PROCESSING
) {
戻る
}
setSegmentationStatus(SEGMENTATION_STATUS.PROCESSING)
クリアポイント()
imageInputRef.current = RawImage.fromURL(url) を待ちます
imageProcessed.current = awaitprocessorRef.current(
imageInputRef.current
)
imageEmbeddings.current = await (
任意のmodelRef.current
).get_image_embeddings(imageProcessed.current)
setSegmentationStatus(SEGMENTATION_STATUS.PROCESSING_SUCCESS)
} キャッチ (エラー) {
console.log('エラー', エラー)
}
})()
}, [url,modelRef.current,processorRef.current])
// マスク効果を更新します
関数 updateMaskOverlay(マスク: RawImage、スコア: Float32Array) {
const MaskCanvas = MaskCanvasRef.current
if (!maskCanvas) {
戻る
}
const MaskContext = MaskCanvas.getContext('2d') as CanvasRenderingContext2D
// キャンバスの寸法を更新します (異なる場合)
if (maskCanvas.width !== マスク.幅 || マスクキャンバス.高さ !== マスク.高さ) {
マスクキャンバス.幅 = マスク.幅
マスクキャンバスの高さ = マスク.高さ
}
// ピクセルデータ用のバッファを確保
const imageData = MaskContext.createImageData(
マスクキャンバスの幅、
マスクキャンバスの高さ
)
// 最適なマスクを選択
const numMasks = スコア.length // 3
bestIndex = 0 にします
for (let i = 1; i スコア[bestIndex]) {
bestIndex = i
}
}
// マスクを色で塗りつぶします
const ピクセルデータ = imageData.data
for (let i = 0; i <pixeldata.length i if bestindex r g b a maskcontext.putimagedata const decode="async" markpoint> {
もし (
!modelRef.current ||
!imageEmbeddings.current ||
!processorRef.current ||
!imageProcessed.current
) {
戻る
}// データをクリックしないとセグメンテーション効果が直接クリアされません
if (!markPoints.length && MaskCanvasRef.current) {
const マスクコンテキスト = マスクCanvasRef.current.getContext(
「2D」
) CanvasRenderingContext2D として
マスクコンテキスト.clearRect(
0、
0、
マスクCanvasRef.current.width、
マスクCanvasRef.current.height
)
戻る
}
// デコード用の入力を準備します
const reshape = imageProcessed.current.reshape_input_sizes[0]
定数ポイント = マークポイント
.map((x) => [x.position[0] * reshape[1], x.position[1] * reshape[0]])
.フラット(無限大)
const label = markPoints.map((x) => BigInt(x.label)). flat(Infinity)
const num_points = markPoints.length
const input_points = new Tensor('float32', ポイント, [1, 1, num_points, 2])
const input_labels = new Tensor('int64', ラベル, [1, 1, num_points])
// マスクを生成する
const { pred_masks, iou_scores } = await modelRef.current({
...imageEmbeddings.current、
入力ポイント、
入力ラベル
})
// マスクの後処理
constマスク = await (processorRef.current as any).post_process_masks(
pred_マスク、
imageProcessed.current.original_sizes、
imageProcessed.current.reshape_input_sizes
)
updateMaskOverlay(RawImage.fromTensor(masks[0][0]), iou_scores.data)
}
const クランプ = (x: 数値、最小 = 0、最大 = 1) => {
return Math.max(Math.min(x, max), min)
}
const clickImage = (e: MouseEvent) => {
if (segmentationStatus !== SEGMENTATION_STATUS.PROCESSING_SUCCESS) {
戻る
}
const { clientX, clientY, currentTarget } = e
const { 左、上 } = currentTarget.getBoundingClientRect()
const x = クランプ(
(clientX - 左 currentTarget.scrollLeft) / currentTarget.scrollWidth
)
const y = クランプ(
(clientY - トップ currentTarget.scrollTop) / currentTarget.scrollHeight
)
const presentPointIndex = markPoints.findIndex(
(ポイント) =>
Math.abs(point.position[0] - x) {
setMarkPoints([])
デコード([])
}
戻る (
<div classname="カード シャドウ-xl オーバーフロー-オート">
<div classname="flex items-center gap-x-3">
<button classname="btn btn-primary btn-sm" onclick="{clearPoints}">
クリアポイント
ボタン>
setPointStatus(true)}
>
{ポイントステータス ? 'ポジティブ' : 'ネガティブ'}
ボタン>
</button>
</div>
<div classname="text-xs text-base-content mt-2">{segmentationTip}</div>
<div>
<h2>
結論
</h2>
<p>読んでいただきありがとうございます。これがこの記事の全内容です。この記事があなたのお役に立てば幸いです。「いいね」やお気に入り登録を歓迎します。ご質問がございましたら、コメント欄でお気軽にご相談ください!</p>
</div>
</div></pixeldata.length></tensor></samimageprocessorresult></rawimage></processor></pretrainedmodel></htmlcanvaselement></boolean></segmentationstatustype></markpoint>以上がCanvas シリーズの探索: Transformers.js と組み合わせてインテリジェントな画像処理を実現の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Python vs. JavaScript:コミュニティ、ライブラリ、リソースApr 15, 2025 am 12:16 AM
Python vs. JavaScript:コミュニティ、ライブラリ、リソースApr 15, 2025 am 12:16 AMPythonとJavaScriptには、コミュニティ、ライブラリ、リソースの観点から、独自の利点と短所があります。 1)Pythonコミュニティはフレンドリーで初心者に適していますが、フロントエンドの開発リソースはJavaScriptほど豊富ではありません。 2)Pythonはデータサイエンスおよび機械学習ライブラリで強力ですが、JavaScriptはフロントエンド開発ライブラリとフレームワークで優れています。 3)どちらも豊富な学習リソースを持っていますが、Pythonは公式文書から始めるのに適していますが、JavaScriptはMDNWebDocsにより優れています。選択は、プロジェクトのニーズと個人的な関心に基づいている必要があります。
 C/CからJavaScriptへ:すべてがどのように機能するかApr 14, 2025 am 12:05 AM
C/CからJavaScriptへ:すべてがどのように機能するかApr 14, 2025 am 12:05 AMC/CからJavaScriptへのシフトには、動的なタイピング、ゴミ収集、非同期プログラミングへの適応が必要です。 1)C/Cは、手動メモリ管理を必要とする静的に型付けられた言語であり、JavaScriptは動的に型付けされ、ごみ収集が自動的に処理されます。 2)C/Cはマシンコードにコンパイルする必要がありますが、JavaScriptは解釈言語です。 3)JavaScriptは、閉鎖、プロトタイプチェーン、約束などの概念を導入します。これにより、柔軟性と非同期プログラミング機能が向上します。
 JavaScriptエンジン:実装の比較Apr 13, 2025 am 12:05 AM
JavaScriptエンジン:実装の比較Apr 13, 2025 am 12:05 AMさまざまなJavaScriptエンジンは、各エンジンの実装原則と最適化戦略が異なるため、JavaScriptコードを解析および実行するときに異なる効果をもたらします。 1。語彙分析:ソースコードを語彙ユニットに変換します。 2。文法分析:抽象的な構文ツリーを生成します。 3。最適化とコンパイル:JITコンパイラを介してマシンコードを生成します。 4。実行:マシンコードを実行します。 V8エンジンはインスタントコンピレーションと非表示クラスを通じて最適化され、Spidermonkeyはタイプ推論システムを使用して、同じコードで異なるパフォーマンスパフォーマンスをもたらします。
 ブラウザを超えて:現実世界のJavaScriptApr 12, 2025 am 12:06 AM
ブラウザを超えて:現実世界のJavaScriptApr 12, 2025 am 12:06 AM現実世界におけるJavaScriptのアプリケーションには、サーバー側のプログラミング、モバイルアプリケーション開発、モノのインターネット制御が含まれます。 2。モバイルアプリケーションの開発は、ReactNativeを通じて実行され、クロスプラットフォームの展開をサポートします。 3.ハードウェアの相互作用に適したJohnny-Fiveライブラリを介したIoTデバイス制御に使用されます。
 next.jsを使用してマルチテナントSaaSアプリケーションを構築する(バックエンド統合)Apr 11, 2025 am 08:23 AM
next.jsを使用してマルチテナントSaaSアプリケーションを構築する(バックエンド統合)Apr 11, 2025 am 08:23 AM私はあなたの日常的な技術ツールを使用して機能的なマルチテナントSaaSアプリケーション(EDTECHアプリ)を作成しましたが、あなたは同じことをすることができます。 まず、マルチテナントSaaSアプリケーションとは何ですか? マルチテナントSaaSアプリケーションを使用すると、Singの複数の顧客にサービスを提供できます
 next.jsを使用してマルチテナントSaaSアプリケーションを構築する方法(フロントエンド統合)Apr 11, 2025 am 08:22 AM
next.jsを使用してマルチテナントSaaSアプリケーションを構築する方法(フロントエンド統合)Apr 11, 2025 am 08:22 AMこの記事では、許可によって保護されたバックエンドとのフロントエンド統合を示し、next.jsを使用して機能的なedtech SaaSアプリケーションを構築します。 FrontEndはユーザーのアクセス許可を取得してUIの可視性を制御し、APIリクエストがロールベースに付着することを保証します
 JavaScript:Web言語の汎用性の調査Apr 11, 2025 am 12:01 AM
JavaScript:Web言語の汎用性の調査Apr 11, 2025 am 12:01 AMJavaScriptは、現代のWeb開発のコア言語であり、その多様性と柔軟性に広く使用されています。 1)フロントエンド開発:DOM操作と最新のフレームワーク(React、Vue.JS、Angularなど)を通じて、動的なWebページとシングルページアプリケーションを構築します。 2)サーバー側の開発:node.jsは、非ブロッキングI/Oモデルを使用して、高い並行性とリアルタイムアプリケーションを処理します。 3)モバイルおよびデスクトップアプリケーション開発:クロスプラットフォーム開発は、反応および電子を通じて実現され、開発効率を向上させます。
 JavaScriptの進化:現在の傾向と将来の見通しApr 10, 2025 am 09:33 AM
JavaScriptの進化:現在の傾向と将来の見通しApr 10, 2025 am 09:33 AMJavaScriptの最新トレンドには、TypeScriptの台頭、最新のフレームワークとライブラリの人気、WebAssemblyの適用が含まれます。将来の見通しは、より強力なタイプシステム、サーバー側のJavaScriptの開発、人工知能と機械学習の拡大、およびIoTおよびEDGEコンピューティングの可能性をカバーしています。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

