


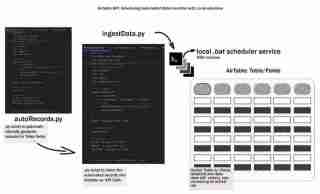
導入
データのライフサイクル全体は、データを生成し、それを何らかの方法でどこかに保存することから始まります。これを初期段階のデータ ライフサイクルと呼び、ローカル ワークフローを使用して Airtable へのデータの取り込みを自動化する方法を検討します。開発環境のセットアップ、取り込みプロセスの設計、バッチ スクリプトの作成、ワークフローのスケジュール設定について説明します。これにより、物事をシンプルに、ローカル/再現可能に、アクセスしやすく保ちます。
まずはAirtableについてお話しましょう。 Airtable は、スプレッドシートのシンプルさとデータベースの構造を融合した強力で柔軟なツールです。情報の整理、プロジェクトの管理、タスクの追跡に最適で、無料利用枠もあります!
環境を整える
開発環境のセットアップ
このプロジェクトは Python で開発するので、お気に入りの IDE を起動して仮想環境を作成します
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate </environment_name></environment_name>
Airtable を使い始めるには、Airtable の Web サイトにアクセスしてください。無料アカウントにサインアップしたら、新しいワークスペースを作成する必要があります。ワークスペースは、関連するすべてのテーブルとデータのコンテナーと考えてください。
次に、ワークスペース内に新しいテーブルを作成します。テーブルは基本的に、データを保存するスプレッドシートです。データの構造に一致するようにテーブルのフィールド (列) を定義します。
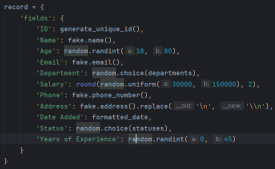
これはチュートリアルで使用されるフィールドの抜粋です。テキスト、日付、および 数値の組み合わせです:
スクリプトを Airtable に接続するには、API キーまたはパーソナル アクセス トークンを生成する必要があります。このキーはパスワードとして機能し、スクリプトが Airtable データと対話できるようにします。キーを生成するには、Airtable アカウント設定に移動し、API セクションを見つけて、指示に従って新しいキーを作成します。
*API キーを安全に保管してください。パブリックに共有したり、パブリック リポジトリにコミットしたりしないでください。 *
必要な依存関係 (Python、ライブラリなど) のインストール
次に、requirements.txt をタッチします。この .txt ファイル内に次のパッケージを配置します:
pyairtable schedule faker python-dotenv
ここで pip install -rrequirements.txt を実行して、必要なパッケージをインストールします。
プロジェクト構造の整理
このステップはスクリプトを作成する場所です。.env は認証情報を保存する場所です。autoRecords.py - 定義されたフィールドと ingestData.py : Airtable にレコードを挿入します。
取り込みプロセスの設計: 環境変数
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate </environment_name></environment_name>
取り込みプロセスの設計: 自動記録
それはいいですね。この従業員データ ジェネレーターのブログ投稿に焦点を当てたサブトピック コンテンツをまとめましょう。
プロジェクト用の現実的な従業員データの生成
従業員データが関係するプロジェクトに取り組む場合、現実的なサンプル データを生成する信頼できる方法があれば役立つことがよくあります。人事管理システム、従業員ディレクトリ、またはその間のものを構築している場合でも、堅牢なテスト データにアクセスできると、開発が合理化され、アプリケーションの復元力が高まります。
このセクションでは、さまざまな関連フィールドを持つランダムな従業員レコードを生成する Python スクリプトについて説明します。このツールは、現実的なデータをアプリケーションに迅速かつ簡単に入力する必要がある場合に貴重な資産となります。
一意の ID の生成
データ生成プロセスの最初のステップは、各従業員レコードの一意の識別子を作成することです。アプリケーションでは各従業員を一意に参照する方法が必要になる可能性が高いため、これは重要な考慮事項です。私たちのスクリプトには、次の ID を生成する簡単な関数が含まれています:
pyairtable schedule faker python-dotenv
この関数は、「N-#####」形式で一意の ID を生成します。数値はランダムな 5 桁の値です。この形式は、特定のニーズに合わせてカスタマイズできます。
ランダムな従業員レコードの生成
次に、従業員レコード自体を生成するコア関数を見てみましょう。 generate_random_records() 関数は、作成するレコードの数を入力として受け取り、辞書のリストを返します。各辞書は、さまざまなフィールドを持つ従業員を表します。
"https://airtable.com/app########/tbl######/viw####?blocks=show" BASE_ID = 'app########' TABLE_NAME = 'tbl######' API_KEY = '#######'
この関数は Faker ライブラリを使用して、名前、電子メール、電話番号、住所などのさまざまな従業員フィールドの現実的なデータを生成します。また、年齢範囲や給与範囲を妥当な値に制限するなど、いくつかの基本的な制約も含まれています。
この関数は辞書のリストを返します。各辞書は Airtable と互換性のある形式で従業員レコードを表します。
Airtable 用のデータを準備する
最後に、prepare_records_for_airtable() 関数を見てみましょう。この関数は、従業員レコードのリストを取得し、各レコードの「フィールド」部分を抽出します。これは、Airtable がデータのインポートに期待する形式です:
def generate_unique_id():
"""Generate a Unique ID in the format N-#####"""
return f"N-{random.randint(10000, 99999)}"
この関数はデータ構造を簡素化し、生成されたデータを Airtable や他のシステムと統合する際の作業を容易にします。
すべてをまとめる
このデータ生成ツールを使用するには、必要なレコード数を指定してgenerate_random_records() 関数を呼び出し、結果のリストを prepare_records_for_airtable() 関数に渡します。
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate </environment_name></environment_name>
これにより、ランダムな従業員レコードが 2 つ生成され、元の形式で印刷され、Airtable に適したフラット形式でレコードが印刷されます。
実行:
pyairtable schedule faker python-dotenv
出力:
"https://airtable.com/app########/tbl######/viw####?blocks=show" BASE_ID = 'app########' TABLE_NAME = 'tbl######' API_KEY = '#######'
生成されたデータを Airtable と統合する
現実的な従業員データの生成に加えて、スクリプトはそのデータを Airtable とシームレスに統合する機能も提供します
Airtable 接続のセットアップ
生成されたデータを Airtable に挿入する前に、プラットフォームへの接続を確立する必要があります。私たちのスクリプトは、pyairtable ライブラリを使用して Airtable API と対話します。まず、Airtable API キー、データを保存するベース ID とテーブル名など、必要な環境変数をロードします。
def generate_unique_id():
"""Generate a Unique ID in the format N-#####"""
return f"N-{random.randint(10000, 99999)}"
これらの認証情報を使用して、Airtable API クライアントを初期化し、操作したい特定のテーブルへの参照を取得できます。
def generate_random_records(num_records=10):
"""
Generate random records with reasonable constraints
:param num_records: Number of records to generate
:return: List of records formatted for Airtable
"""
records = []
# Constants
departments = ['Sales', 'Engineering', 'Marketing', 'HR', 'Finance', 'Operations']
statuses = ['Active', 'On Leave', 'Contract', 'Remote']
for _ in range(num_records):
# Generate date in the correct format
random_date = datetime.now() - timedelta(days=random.randint(0, 365))
formatted_date = random_date.strftime('%Y-%m-%dT%H:%M:%S.000Z')
record = {
'fields': {
'ID': generate_unique_id(),
'Name': fake.name(),
'Age': random.randint(18, 80),
'Email': fake.email(),
'Department': random.choice(departments),
'Salary': round(random.uniform(30000, 150000), 2),
'Phone': fake.phone_number(),
'Address': fake.address().replace('\n', '\n'), # Escape newlines
'Date Added': formatted_date,
'Status': random.choice(statuses),
'Years of Experience': random.randint(0, 45)
}
}
records.append(record)
return records
生成されたデータの挿入
これで接続が設定されたので、前のセクションのgenerate_random_records() 関数を使用して従業員レコードのバッチを作成し、それらを Airtable に挿入できます。
def prepare_records_for_airtable(records):
"""Convert records from nested format to flat format for Airtable"""
return [record['fields'] for record in records]
prep_for_insertion() 関数は、generate_random_records() によって返されたネストされたレコード形式を、Airtable API が期待するフラット形式に変換する役割を果たします。データの準備が完了したら、table.batch_create() メソッドを使用して、単一の一括操作でレコードを挿入します。
エラー処理とログ記録
統合プロセスが堅牢でデバッグが容易であることを保証するために、いくつかの基本的なエラー処理およびログ機能も組み込まれています。データ挿入プロセス中にエラーが発生した場合、スクリプトはトラブルシューティングに役立つエラー メッセージを記録します。
if __name__ == "__main__":
records = generate_random_records(2)
print(records)
prepared_records = prepare_records_for_airtable(records)
print(prepared_records)
以前のスクリプトの強力なデータ生成機能とここで示す統合機能を組み合わせることで、Airtable ベースのアプリケーションに現実的な従業員データを迅速かつ確実に入力できます。
バッチスクリプトを使用した自動データ取り込みのスケジュール設定
データ取り込みプロセスを完全に自動化するには、Python スクリプトを定期的に実行するバッチ スクリプト (.bat ファイル) を作成します。これにより、手動介入なしでデータ取り込みが自動的に行われるように設定できます。
ここでは、ingestData.py スクリプトの実行に使用できるバッチ スクリプトの例を示します。
python autoRecords.py
このスクリプトの重要な部分を分析してみましょう:
- @echo off: この行は、各コマンドのコンソールへの出力を抑制し、出力をきれいにします。
- echo starting Airtable Automated Data Ingestion Service...: この行は、スクリプトが開始されたことを示すメッセージをコンソールに出力します。
- cd /d C:UsersbuascPycharmProjectsscrapEngineering: この行は、現在の作業ディレクトリを、ingestData.py スクリプトが配置されているプロジェクト ディレクトリに変更します。
- call C:UsersbuascPycharmProjectsscrapEngineeringvenv_airtableScriptsactivate.bat: この行は、必要な Python 依存関係がインストールされている仮想環境をアクティブ化します。
- python ingestData.py: この行は、ingestData.py Python スクリプトを実行します。
- if %ERRORLEVEL% NEQ 0 (... ): このブロックは、Python スクリプトでエラーが発生したかどうか (つまり、ERRORLEVEL がゼロでないかどうか) をチェックします。エラーが発生した場合は、エラー メッセージが出力され、スクリプトが一時停止されるため、問題を調査できるようになります。
このバッチ スクリプトが自動的に実行されるようにスケジュールするには、Windows タスク スケジューラを使用できます。手順の概要を次に示します:
- スタート メニューを開き、「タスク スケジューラ」を検索します。
または
Windows R と

- タスク スケジューラで、新しいタスクを作成し、わかりやすい名前を付けます (例: 「Airtable データ インジェスト」)。
- [アクション] タブで、新しいアクションを追加し、バッチ スクリプトへのパスを指定します (例: C:UsersbuascPycharmProjectsscrapEngineeringingestData.bat)。
- 毎日、毎週、毎月など、スクリプトを実行するスケジュールを構成します。
- タスクを保存して有効にします。

これで、Windows タスク スケジューラは指定された間隔でバッチ スクリプトを自動的に実行し、Airtable データが手動介入なしで定期的に更新されるようになります。
結論
これは、テスト、開発、さらにはデモンストレーションの目的でも非常に貴重なツールとなる可能性があります。
このガイドでは、必要な開発環境をセットアップする方法、取り込みプロセスを設計する方法、タスクを自動化するバッチ スクリプトを作成する方法、無人実行のワークフローをスケジュールする方法を学習しました。現在、私たちはローカル オートメーションの力を活用してデータ取り込み操作を合理化し、Airtable を活用したデータ エコシステムから貴重な洞察を引き出す方法をしっかりと理解しています。
自動データ取り込みプロセスを設定したので、この基盤に基づいて Airtable データからさらに多くの価値を引き出す方法はたくさんあります。コードを試し、新しいユースケースを探索し、その経験をコミュニティと共有することをお勧めします。
始めるためのアイデアをいくつか紹介します:
- データ生成をカスタマイズする
- 取り込まれたデータの活用 [Markdown ベースの探索的データ分析 (EDA)、Tableau、Power BI、Plotly などのツールを使用したインタラクティブなダッシュボードや視覚化の構築、機械学習ワークフローの実験 (離職率の予測やトップパフォーマーの特定)]
- 他のシステムとの統合 [クラウド機能、Webhook、またはデータ ウェアハウス]
可能性は無限大です!この自動化されたデータ取り込みプロセスをどのように構築し、Airtable データから新しい洞察と価値を引き出すかを見るのが楽しみです。ためらわずに実験し、コラボレーションし、進捗状況を共有してください。私はあなたをサポートするためにここにいます。
完全なコード https://github.com/AkanimohOD19A/scheduling_airtable_insertion を参照してください。完全なビデオ チュートリアルも準備中です。
以上がローカル ワークフロー: Airtable へのデータ取り込みのオーケストレーションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 numpyを使用してマルチディメンシャルアレイをどのように作成しますか?Apr 29, 2025 am 12:27 AM
numpyを使用してマルチディメンシャルアレイをどのように作成しますか?Apr 29, 2025 am 12:27 AMNumpyを使用して多次元配列を作成すると、次の手順を通じて実現できます。1)numpy.array()関数を使用して、np.array([[1,2,3]、[4,5,6]])などの配列を作成して2D配列を作成します。 2)np.zeros()、np.ones()、np.random.random()およびその他の関数を使用して、特定の値で満たされた配列を作成します。 3)アレイの形状とサイズの特性を理解して、サブアレイの長さが一貫していることを確認し、エラーを回避します。 4)np.reshape()関数を使用して、配列の形状を変更します。 5)コードが明確で効率的であることを確認するために、メモリの使用に注意してください。
 Numpyアレイの「ブロードキャスト」の概念を説明します。Apr 29, 2025 am 12:23 AM
Numpyアレイの「ブロードキャスト」の概念を説明します。Apr 29, 2025 am 12:23 AMBroadcastinginNumPyisamethodtoperformoperationsonarraysofdifferentshapesbyautomaticallyaligningthem.Itsimplifiescode,enhancesreadability,andboostsperformance.Here'showitworks:1)Smallerarraysarepaddedwithonestomatchdimensions.2)Compatibledimensionsare
 データストレージ用のリスト、array.array、およびnumpy配列を選択する方法を説明します。Apr 29, 2025 am 12:20 AM
データストレージ用のリスト、array.array、およびnumpy配列を選択する方法を説明します。Apr 29, 2025 am 12:20 AMForpythondatastorage、chooseLists forfficability withmixeddatypes、array.arrayformemory-efficienthogeneousnumericaldata、およびnumpyArrays foradvancednumericalcomputing.listSareversatilebuteficient efficient forlargeNumericaldatates;
 Pythonリストを使用することが配列を使用するよりも適切であるシナリオの例を挙げてください。Apr 29, 2025 am 12:17 AM
Pythonリストを使用することが配列を使用するよりも適切であるシナリオの例を挙げてください。Apr 29, 2025 am 12:17 AMpythonlistsarebetterthanarrays formangingdiversedatypes.1)listscanholdelementsofdifferenttypes、2)adearedditionsandremovals、3)theeofferintutiveoperation likeslicing、but4)theearlessememory-effice-hemory-hemory-hemory-hemory-hemory-adlower-dslorededatas。
 Pythonアレイ内の要素にどのようにアクセスしますか?Apr 29, 2025 am 12:11 AM
Pythonアレイ内の要素にどのようにアクセスしますか?Apr 29, 2025 am 12:11 AMtoaccesselementsinapythonarray、useindexing:my_array [2] Accessesthirderement、Returning3.pythonuseszero basedIndexing.1)usepositiveandnegativeindexing:my_list [0] forteefirstelement、my_list [-1] exterarast.2)
 Pythonでタプルの理解が可能ですか?はいの場合、どうしてそうでない場合は?Apr 28, 2025 pm 04:34 PM
Pythonでタプルの理解が可能ですか?はいの場合、どうしてそうでない場合は?Apr 28, 2025 pm 04:34 PM記事では、構文のあいまいさのためにPythonにおけるタプル理解の不可能性について説明します。 Tupple式を使用してTuple()を使用するなどの代替は、Tuppleを効率的に作成するためにお勧めします。(159文字)
 Pythonのモジュールとパッケージとは何ですか?Apr 28, 2025 pm 04:33 PM
Pythonのモジュールとパッケージとは何ですか?Apr 28, 2025 pm 04:33 PMこの記事では、Pythonのモジュールとパッケージ、その違い、および使用について説明しています。モジュールは単一のファイルであり、パッケージは__init__.pyファイルを備えたディレクトリであり、関連するモジュールを階層的に整理します。
 PythonのDocstringとは何ですか?Apr 28, 2025 pm 04:30 PM
PythonのDocstringとは何ですか?Apr 28, 2025 pm 04:30 PM記事では、PythonのDocstrings、それらの使用、および利点について説明します。主な問題:コードのドキュメントとアクセシビリティに関するドキュストリングの重要性。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 中国語版
中国語版、とても使いやすい

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

ドリームウィーバー CS6
ビジュアル Web 開発ツール

WebStorm Mac版
便利なJavaScript開発ツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。
ホットトピック
 7807
7807 15164614140252130025123629
15164614140252130025123629