


ヤヌス 1.3B
Janus は、マルチモーダルな理解と生成を統合する新しい自己回帰フレームワークです。理解タスクと生成タスクの両方に単一のビジュアル エンコーダを使用していた以前のモデルとは異なり、Janus ではこれらの関数に対して 2 つの別個のビジュアル エンコード パスウェイが導入されています。
理解と生成のためのエンコーディングの違い
- マルチモーダル理解タスクでは、ビジュアル エンコーダーは、オブジェクト カテゴリや視覚的属性などの高レベルの意味情報を抽出します。このエンコーダは、高次元の意味要素を強調し、複雑な意味を推測することに重点を置いています。
- 一方、ビジュアル生成タスクでは、細部の生成と全体的な一貫性の維持に重点が置かれます。その結果、空間構造とテクスチャをキャプチャできる低次元エンコードが必要になります。
環境のセットアップ
Google Colab で Janus を実行する手順は次のとおりです:
git clone https://github.com/deepseek-ai/Janus cd Janus pip install -e . # If needed, install the following as well # pip install wheel # pip install flash-attn --no-build-isolation
ビジョンタスク
モデルのロード
次のコードを使用して、ビジョン タスクに必要なモデルをロードします。
import torch from transformers import AutoModelForCausalLM from janus.models import MultiModalityCausalLM, VLChatProcessor from janus.utils.io import load_pil_images # Specify the model path model_path = "deepseek-ai/Janus-1.3B" vl_chat_processor = VLChatProcessor.from_pretrained(model_path) tokenizer = vl_chat_processor.tokenizer vl_gpt = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True) vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
エンコード用の画像のロードと準備
次に、画像をロードし、モデルが理解できる形式に変換します。
conversation = [
{
"role": "User",
"content": "<image_placeholder>\nDescribe this chart.",
"images": ["images/pie_chart.png"],
},
{"role": "Assistant", "content": ""},
]
# Load the image and prepare input
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device)
# Run the image encoder and obtain image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
</image_placeholder>
応答の生成
最後に、モデルを実行して応答を生成します。
# Run the model and generate a response
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True,
)
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)
出力例
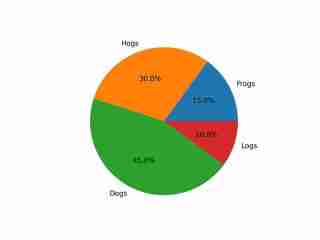
The image depicts a pie chart that illustrates the distribution of four different categories among four distinct groups. The chart is divided into four segments, each representing a category with a specific percentage. The categories and their corresponding percentages are as follows: 1. **Hogs**: This segment is colored in orange and represents 30.0% of the total. 2. **Frog**: This segment is colored in blue and represents 15.0% of the total. 3. **Logs**: This segment is colored in red and represents 10.0% of the total. 4. **Dogs**: This segment is colored in green and represents 45.0% of the total. The pie chart is visually divided into four segments, each with a different color and corresponding percentage. The segments are arranged in a clockwise manner starting from the top-left, moving clockwise. The percentages are clearly labeled next to each segment. The chart is a simple visual representation of data, where the size of each segment corresponds to the percentage of the total category it represents. This type of chart is commonly used to compare the proportions of different categories in a dataset. To summarize, the pie chart shows the following: - Hogs: 30.0% - Frog: 15.0% - Logs: 10.0% - Dogs: 45.0% This chart can be used to understand the relative proportions of each category in the given dataset.
出力は、色やテキストを含む画像を適切に理解していることを示します。
イメージ生成タスク
モデルのロード
次のコードを使用して、画像生成タスクに必要なモデルをロードします。
import os import PIL.Image import torch import numpy as np from transformers import AutoModelForCausalLM from janus.models import MultiModalityCausalLM, VLChatProcessor # Specify the model path model_path = "deepseek-ai/Janus-1.3B" vl_chat_processor = VLChatProcessor.from_pretrained(model_path) tokenizer = vl_chat_processor.tokenizer vl_gpt = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True) vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
プロンプトの準備
次に、ユーザーのリクエストに基づいてプロンプトを準備します。
# Set up the prompt
conversation = [
{
"role": "User",
"content": "cute japanese girl, wearing a bikini, in a beach",
},
{"role": "Assistant", "content": ""},
]
# Convert the prompt into the appropriate format
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
conversations=conversation,
sft_format=vl_chat_processor.sft_format,
system_prompt="",
)
prompt = sft_format + vl_chat_processor.image_start_tag
画像の生成
画像の生成には以下の関数を使用します。デフォルトでは、16 個の画像が生成されます:
@torch.inference_mode()
def generate(
mmgpt: MultiModalityCausalLM,
vl_chat_processor: VLChatProcessor,
prompt: str,
temperature: float = 1,
parallel_size: int = 16,
cfg_weight: float = 5,
image_token_num_per_image: int = 576,
img_size: int = 384,
patch_size: int = 16,
):
input_ids = vl_chat_processor.tokenizer.encode(prompt)
input_ids = torch.LongTensor(input_ids)
tokens = torch.zeros((parallel_size*2, len(input_ids)), dtype=torch.int).cuda()
for i in range(parallel_size*2):
tokens[i, :] = input_ids
if i % 2 != 0:
tokens[i, 1:-1] = vl_chat_processor.pad_id
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
for i in range(image_token_num_per_image):
outputs = mmgpt.language_model.model(
inputs_embeds=inputs_embeds,
use_cache=True,
past_key_values=outputs.past_key_values if i != 0 else None,
)
hidden_states = outputs.last_hidden_state
logits = mmgpt.gen_head(hidden_states[:, -1, :])
logit_cond = logits[0::2, :]
logit_uncond = logits[1::2, :]
logits = logit_uncond + cfg_weight * (logit_cond - logit_uncond)
probs = torch.softmax(logits / temperature, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
generated_tokens[:, i] = next_token.squeeze(dim=-1)
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
inputs_embeds = img_embeds.unsqueeze(dim=1)
dec = mmgpt.gen_vision_model.decode_code(
generated_tokens.to(dtype=torch.int),
shape=[parallel_size, 8, img_size // patch_size, img_size // patch_size],
)
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
visual_img[:, :, :] = dec
os.makedirs('generated_samples', exist_ok=True)
for i in range(parallel_size):
save_path = os.path.join('generated_samples', f"img_{i}.jpg")
PIL.Image.fromarray(visual_img[i]).save(save_path)
# Run the image generation
generate(vl_gpt, vl_chat_processor, prompt)
生成された画像は generated_samples フォルダーに保存されます。
生成された結果のサンプル
以下は生成された画像の例です:

- 犬は比較的よく描かれています。
- 建物は全体的な形状を維持していますが、窓などの一部の細部は非現実的に見える場合があります。
- ただし、人間は、フォトリアルなスタイルとアニメ風のスタイルの両方で顕著な歪みがあり、うまく生成するのが困難です。
以上がJanus B: マルチモーダルな理解と生成タスクのための統合モデルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Pythonと時間:勉強時間を最大限に活用するApr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用するApr 14, 2025 am 12:02 AM限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 Python:ゲーム、GUIなどApr 13, 2025 am 12:14 AM
Python:ゲーム、GUIなどApr 13, 2025 am 12:14 AMPythonはゲームとGUI開発に優れています。 1)ゲーム開発は、2Dゲームの作成に適した図面、オーディオ、その他の機能を提供し、Pygameを使用します。 2)GUI開発は、TKINTERまたはPYQTを選択できます。 TKINTERはシンプルで使いやすく、PYQTは豊富な機能を備えており、専門能力開発に適しています。
 Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AM
Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AMPythonは、データサイエンス、Web開発、自動化タスクに適していますが、Cはシステムプログラミング、ゲーム開発、組み込みシステムに適しています。 Pythonは、そのシンプルさと強力なエコシステムで知られていますが、Cは高性能および基礎となる制御機能で知られています。
 2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM
2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM2時間以内にPythonの基本的なプログラミングの概念とスキルを学ぶことができます。 1.変数とデータ型、2。マスターコントロールフロー(条件付きステートメントとループ)、3。機能の定義と使用を理解する4。
 Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AM
Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AMPythonは、Web開発、データサイエンス、機械学習、自動化、スクリプトの分野で広く使用されています。 1)Web開発では、DjangoおよびFlask Frameworksが開発プロセスを簡素化します。 2)データサイエンスと機械学習の分野では、Numpy、Pandas、Scikit-Learn、Tensorflowライブラリが強力なサポートを提供します。 3)自動化とスクリプトの観点から、Pythonは自動テストやシステム管理などのタスクに適しています。
 2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM
2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM2時間以内にPythonの基本を学ぶことができます。 1。変数とデータ型を学習します。2。ステートメントやループの場合などのマスター制御構造、3。関数の定義と使用を理解します。これらは、簡単なPythonプログラムの作成を開始するのに役立ちます。
 プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM
プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM10時間以内にコンピューター初心者プログラミングの基本を教える方法は?コンピューター初心者にプログラミングの知識を教えるのに10時間しかない場合、何を教えることを選びますか...
 中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?Apr 02, 2025 am 07:15 AM
中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?Apr 02, 2025 am 07:15 AMfiddlereveryversings for the-middleの測定値を使用するときに検出されないようにする方法


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

