


このチュートリアルでは、ユーザーが PDF をアップロードし、OpenAI の API を使用してそのコンテンツを取得し、 を使用してチャットのようなインターフェイスに応答を表示できるシンプルなチャット インターフェイスを構築します。ストリームリット。また、@pinata を利用して PDF ファイルをアップロードして保存します。
次に進む前に、構築しているものを少し見てみましょう:
前提条件:
- Python の基礎知識
- Pinata API キー (PDF アップロード用)
- OpenAI API キー (応答生成用)
- Streamlit がインストールされています (UI の構築用)
ステップ 1: プロジェクトのセットアップ
まず、新しい Python プロジェクト ディレクトリを作成します。
mkdir chat-with-pdf cd chat-with-pdf python3 -m venv venv source venv/bin/activate pip install streamlit openai requests PyPDF2
次に、プロジェクトのルートに .env ファイルを作成し、次の環境変数を追加します。
PINATA_API_KEY=<your pinata api key> PINATA_SECRET_API_KEY=<your pinata secret key> OPENAI_API_KEY=<your openai api key> </your></your></your>
OPENAI_API_KEY は有料なので自分で管理する必要がありますが、Pinita で API キーを作成するプロセスを見てみましょう。
それでは、先に進む前に、ピニャータを使用する理由をお知らせください。

Pinata は、分散型 および 分散型 ファイル ストレージ システムである IPFS (InterPlanetary File System) 上でファイルを保存および管理するためのプラットフォームを提供するサービスです。
- 分散ストレージ: Pinata は、分散ネットワークである IPFS にファイルを保存するのに役立ちます。
- 使いやすさ: ファイル管理のための使いやすいツールと API を提供します。
- ファイルの可用性: Pinata は、ファイルを IPFS に「固定」することでファイルにアクセスできるようにします。
- NFT サポート: NFT および Web3 アプリのメタデータの保存に最適です。
- 費用対効果: Pinata は、従来のクラウド ストレージに代わる安価な代替手段となります。
サインインして必要なトークンを作成しましょう:
次のステップは、登録したメールアドレスを確認することです:

サインインを確認して API キーを生成した後:

その後、API キーセクションに移動し、新しい API キーを作成します:
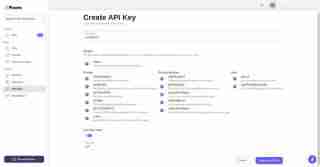
最後に、キーが正常に生成されました。そのキーをコピーして、コード エディターに保存してください。
OPENAI_API_KEY=<your openai api key> PINATA_API_KEY=dfc05775d0c8a1743247 PINATA_SECRET_API_KEY=a54a70cd227a85e68615a5682500d73e9a12cd211dfbf5e25179830dc8278efc </your>
ステップ 2: Pinata を使用した PDF アップロード
Pinata の API を使用して PDF をアップロードし、各ファイルのハッシュ (CID) を取得します。 PDF アップロードを処理するために pinata_helper.py という名前のファイルを作成します。
import os # Import the os module to interact with the operating system
import requests # Import the requests library to make HTTP requests
from dotenv import load_dotenv # Import load_dotenv to load environment variables from a .env file
# Load environment variables from the .env file
load_dotenv()
# Define the Pinata API URL for pinning files to IPFS
PINATA_API_URL = "https://api.pinata.cloud/pinning/pinFileToIPFS"
# Retrieve Pinata API keys from environment variables
PINATA_API_KEY = os.getenv("PINATA_API_KEY")
PINATA_SECRET_API_KEY = os.getenv("PINATA_SECRET_API_KEY")
def upload_pdf_to_pinata(file_path):
"""
Uploads a PDF file to Pinata's IPFS service.
Args:
file_path (str): The path to the PDF file to be uploaded.
Returns:
str: The IPFS hash of the uploaded file if successful, None otherwise.
"""
# Prepare headers for the API request with the Pinata API keys
headers = {
"pinata_api_key": PINATA_API_KEY,
"pinata_secret_api_key": PINATA_SECRET_API_KEY
}
# Open the file in binary read mode
with open(file_path, 'rb') as file:
# Send a POST request to Pinata API to upload the file
response = requests.post(PINATA_API_URL, files={'file': file}, headers=headers)
# Check if the request was successful (status code 200)
if response.status_code == 200:
print("File uploaded successfully") # Print success message
# Return the IPFS hash from the response JSON
return response.json()['IpfsHash']
else:
# Print an error message if the upload failed
print(f"Error: {response.text}")
return None # Return None to indicate failure
ステップ 3: OpenAI のセットアップ
次に、OpenAI API を使用して PDF から抽出されたテキストを操作する関数を作成します。チャット応答には OpenAI の gpt-4o または gpt-4o-mini モデルを活用します。
新しいファイル openai_helper.py を作成します:
import os
from openai import OpenAI
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Initialize OpenAI client with the API key
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=OPENAI_API_KEY)
def get_openai_response(text, pdf_text):
try:
# Create the chat completion request
print("User Input:", text)
print("PDF Content:", pdf_text) # Optional: for debugging
# Combine the user's input and PDF content for context
messages = [
{"role": "system", "content": "You are a helpful assistant for answering questions about the PDF."},
{"role": "user", "content": pdf_text}, # Providing the PDF content
{"role": "user", "content": text} # Providing the user question or request
]
response = client.chat.completions.create(
model="gpt-4", # Use "gpt-4" or "gpt-4o mini" based on your access
messages=messages,
max_tokens=100, # Adjust as necessary
temperature=0.7 # Adjust to control response creativity
)
# Extract the content of the response
return response.choices[0].message.content # Corrected access method
except Exception as e:
return f"Error: {str(e)}"
ステップ 4: Streamlit インターフェイスの構築
ヘルパー関数の準備ができたので、PDF をアップロードし、OpenAI から応答を取得し、チャットを表示する Streamlit アプリを構築します。
app.py という名前のファイルを作成します:
import streamlit as st
import os
import time
from pinata_helper import upload_pdf_to_pinata
from openai_helper import get_openai_response
from PyPDF2 import PdfReader
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
st.set_page_config(page_title="Chat with PDFs", layout="centered")
st.title("Chat with PDFs using OpenAI and Pinata")
uploaded_file = st.file_uploader("Upload your PDF", type="pdf")
# Initialize session state for chat history and loading state
if "chat_history" not in st.session_state:
st.session_state.chat_history = []
if "loading" not in st.session_state:
st.session_state.loading = False
if uploaded_file is not None:
# Save the uploaded file temporarily
file_path = os.path.join("temp", uploaded_file.name)
with open(file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
# Upload PDF to Pinata
st.write("Uploading PDF to Pinata...")
pdf_cid = upload_pdf_to_pinata(file_path)
if pdf_cid:
st.write(f"File uploaded to IPFS with CID: {pdf_cid}")
# Extract PDF content
reader = PdfReader(file_path)
pdf_text = ""
for page in reader.pages:
pdf_text += page.extract_text()
if pdf_text:
st.text_area("PDF Content", pdf_text, height=200)
# Allow user to ask questions about the PDF
user_input = st.text_input("Ask something about the PDF:", disabled=st.session_state.loading)
if st.button("Send", disabled=st.session_state.loading):
if user_input:
# Set loading state to True
st.session_state.loading = True
# Display loading indicator
with st.spinner("AI is thinking..."):
# Simulate loading with sleep (remove in production)
time.sleep(1) # Simulate network delay
# Get AI response
response = get_openai_response(user_input, pdf_text)
# Update chat history
st.session_state.chat_history.append({"user": user_input, "ai": response})
# Clear the input box after sending
st.session_state.input_text = ""
# Reset loading state
st.session_state.loading = False
# Display chat history
if st.session_state.chat_history:
for chat in st.session_state.chat_history:
st.write(f"**You:** {chat['user']}")
st.write(f"**AI:** {chat['ai']}")
# Auto-scroll to the bottom of the chat
st.write("<style>div.stChat {overflow-y: auto;}</style>", unsafe_allow_html=True)
# Add three dots as a loading indicator if still waiting for response
if st.session_state.loading:
st.write("**AI is typing** ...")
else:
st.error("Could not extract text from the PDF.")
else:
st.error("Failed to upload PDF to Pinata.")
ステップ 5: アプリを実行する
アプリをローカルで実行するには、次のコマンドを使用します:
streamlit run app.py
ファイルは Pinata プラットフォームに正常にアップロードされました:

ステップ 6: コードの説明
ピニャータのアップロード
- ユーザーは PDF ファイルをアップロードします。このファイルは一時的にローカルに保存され、upload_pdf_to_pinata 関数を使用して Pinata にアップロードされます。 Pinata は、IPFS に保存されているファイルを表すハッシュ (CID) を返します。
PDF 抽出
- ファイルがアップロードされると、PyPDF2 を使用して PDF のコンテンツが抽出されます。このテキストはテキスト領域に表示されます。
OpenAI インタラクション
- ユーザーはテキスト入力を使用して PDF コンテンツについて質問できます。 get_openai_response 関数は、ユーザーのクエリを PDF コンテンツとともに OpenAI に送信し、OpenAI は関連する応答を返します。
最終コードはこの github リポジトリで入手できます:
https://github.com/Jagroop2001/chat-with-pdf
このブログは以上です。さらなるアップデートに注目して、素晴らしいアプリを構築し続けてください! ?✨
コーディングを楽しんでください! ?
以上がPinata、OpenAI、Streamlit を使用して PDF とチャットするの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?Apr 01, 2025 pm 05:09 PMLinuxターミナルでPythonバージョンを表示する際の許可の問題の解決策PythonターミナルでPythonバージョンを表示しようとするとき、Pythonを入力してください...
 HTMLを解析するために美しいスープを使用するにはどうすればよいですか?Mar 10, 2025 pm 06:54 PM
HTMLを解析するために美しいスープを使用するにはどうすればよいですか?Mar 10, 2025 pm 06:54 PMこの記事では、Pythonライブラリである美しいスープを使用してHTMLを解析する方法について説明します。 find()、find_all()、select()、およびget_text()などの一般的な方法は、データ抽出、多様なHTML構造とエラーの処理、および代替案(SEL
 TensorflowまたはPytorchで深い学習を実行する方法は?Mar 10, 2025 pm 06:52 PM
TensorflowまたはPytorchで深い学習を実行する方法は?Mar 10, 2025 pm 06:52 PMこの記事では、深い学習のためにTensorflowとPytorchを比較しています。 関連する手順、データの準備、モデルの構築、トレーニング、評価、展開について詳しく説明しています。 特に計算グラップに関して、フレームワーク間の重要な違い
 Pythonでコマンドラインインターフェイス(CLI)を作成する方法は?Mar 10, 2025 pm 06:48 PM
Pythonでコマンドラインインターフェイス(CLI)を作成する方法は?Mar 10, 2025 pm 06:48 PMこの記事では、コマンドラインインターフェイス(CLI)の構築に関するPython開発者をガイドします。 Typer、Click、Argparseなどのライブラリを使用して、入力/出力の処理を強調し、CLIの使いやすさを改善するためのユーザーフレンドリーな設計パターンを促進することを詳述しています。
 人気のあるPythonライブラリとその用途は何ですか?Mar 21, 2025 pm 06:46 PM
人気のあるPythonライブラリとその用途は何ですか?Mar 21, 2025 pm 06:46 PMこの記事では、numpy、pandas、matplotlib、scikit-learn、tensorflow、django、flask、and requestsなどの人気のあるPythonライブラリについて説明し、科学的コンピューティング、データ分析、視覚化、機械学習、Web開発、Hの使用について説明します。
 あるデータフレームの列全体を、Python内の異なる構造を持つ別のデータフレームに効率的にコピーする方法は?Apr 01, 2025 pm 11:15 PM
あるデータフレームの列全体を、Python内の異なる構造を持つ別のデータフレームに効率的にコピーする方法は?Apr 01, 2025 pm 11:15 PMPythonのPandasライブラリを使用する場合、異なる構造を持つ2つのデータフレーム間で列全体をコピーする方法は一般的な問題です。 2つのデータがあるとします...
 Pythonの仮想環境の目的を説明してください。Mar 19, 2025 pm 02:27 PM
Pythonの仮想環境の目的を説明してください。Mar 19, 2025 pm 02:27 PMこの記事では、Pythonにおける仮想環境の役割について説明し、プロジェクトの依存関係の管理と競合の回避に焦点を当てています。プロジェクト管理の改善と依存関係の問題を減らすための作成、アクティベーション、およびメリットを詳しく説明しています。
 正規表現とは何ですか?Mar 20, 2025 pm 06:25 PM
正規表現とは何ですか?Mar 20, 2025 pm 06:25 PM正規表現は、プログラミングにおけるパターンマッチングとテキスト操作のための強力なツールであり、さまざまなアプリケーションにわたるテキスト処理の効率を高めます。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

WebStorm Mac版
便利なJavaScript開発ツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター
ホットトピック
 7444
7444 15137152
15137152