


概要
- モデル評価の目標は何ですか?
- モデル評価の目的とそのいくつかは何ですか? 一般的な評価手順?
- 分類精度の用途とその精度は何ですか? 制限?
- 混同行列は、オブジェクトのパフォーマンスをどのように説明しますか? 分類子?
- 混同行列から計算できるメトリクスは何ですか?
Tモデル評価の目標は、質問に答えることです。
さまざまなモデルを選択するにはどうすればよいですか?
機械学習を評価するプロセスは、モデルがそのアプリケーションに対してどの程度信頼性があり効果的であるかを判断するのに役立ちます。これには、パフォーマンス、指標、予測や意思決定の精度などのさまざまな要素を評価することが含まれます。
どのモデルを使用する場合でも、さまざまなモデル タイプ、チューニング パラメーター、機能など、モデル間で選択する方法が必要です。また、モデルが目に見えないデータに対してどの程度一般化されるかを推定するには、モデル評価手順も必要です。最後に、モデルのパフォーマンスを定量化するために、他の手順と組み合わせる評価手順が必要です。
先に進む前に、さまざまなモデルの評価手順とその動作方法をいくつか確認してみましょう。
モデルの評価手順とその運用方法。
-
同じデータに対するトレーニングとテスト
- トレーニング データを「過剰適合」し、必ずしも一般化できない、過度に複雑なモデルに報酬を与えます
-
トレーニング/テストの分割
- データセットを 2 つの部分に分割し、異なるデータでモデルをトレーニングおよびテストできるようにします
- サンプル外のパフォーマンスの推定値は改善されましたが、依然として「変動が大きい」推定値です
- スピード、シンプルさ、柔軟性により便利です
-
K 分割交差検証
- 「K」個のトレーニング/テスト分割を体系的に作成し、結果をまとめて平均します
- サンプル外のパフォーマンスのさらに正確な推定
- トレーニング/テスト分割よりも「K」倍遅く実行されます。
上記のことから、次のことが推測できます:
同じデータでのトレーニングとテストは、新しいデータに一般化されず、実際には役に立たない過度に複雑なモデルを構築する過学習の典型的な原因です。
Train_Test_Split は、サンプル外のパフォーマンスをより正確に推定します。
K 分割相互検証は、系統的に K トレーニング テストを分割し、結果をまとめて平均することでより効果的に実行されます。
要約すると、train_tests_split はその速度とシンプルさのおかげで相互検証に依然として有益であり、それをこのチュートリアル ガイドで使用します。
モデルの評価指標:
選択した手順に沿って評価指標が常に必要になります。指標の選択は、対処している問題によって異なります。分類問題の場合は、分類精度を使用できます。ただし、このガイドでは他の重要な分類評価指標に焦点を当てます。
新しい評価指標を学ぶ前に、分類精度を確認し、その長所と短所について話しましょう。
分類精度
このチュートリアルでは、768 人の患者の健康データと糖尿病の状態を含むピマ インディアン糖尿病データセットを選択しました。

データを読み取り、データの最初の 5 行を出力しましょう。ラベル列は、患者が糖尿病を患っている場合は 1、患者が糖尿病を患っていない場合は 0 を示し、次の質問に答える予定です。
質問: 健康測定結果から患者の糖尿病の状態を予測できますか?
特徴メトリクス X と応答ベクトル Y を定義します。train_test_split を使用して、X と Y をトレーニング セットとテスト セットに分割します。

次に、トレーニング セットでロジスティック回帰モデルをトレーニングします。その後の当てはめステップ中に、logreg モデル オブジェクトは X_train と Y_train の間の関係を学習します。最後に、テスト セットのクラス予測を作成します。
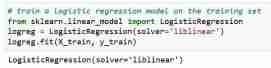

これで、テスト セットの予測が完了しました。分類精度を計算できます。これは、単純に正しい予測の割合です。

ただし、分類精度を評価指標として使用する場合は常に、それを ヌル精度 と比較することが重要です。これは、最も頻繁に発生するクラスを常に予測することで達成できる精度です。
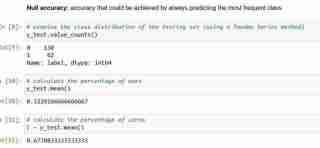
ヌル精度 が質問に答えます。私のモデルが支配的なクラスを 100% の確率で予測するとしたら、それはどれくらいの頻度で正しいでしょうか?上記のシナリオでは、y_test の 32% が 1 です。言い換えれば、患者が糖尿病であると予測する愚かなモデルは、68% の確率で正しくなります (これはゼロです)。これは、ロジスティック回帰を測定する際のベースラインとなります。モデル。
ヌル精度 68% とモデル精度 69% を比較すると、モデルはあまり良くないようです。これは、モデル評価指標としての分類精度の 1 つの弱点を示しています。分類精度からは、テストの基礎となる分布については何もわかりません。
要約:
- 分類精度は、理解するのが最も簡単な分類指標です
- しかし、応答値の基礎となる分布はわかりません
- また、分類子がどのようなエラーの「タイプ」を起こしているかはわかりません。
混同行列を見てみましょう。
混同行列
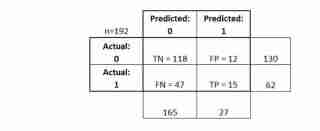
混同行列は、分類モデルのパフォーマンスを説明する表です。
これは分類器のパフォーマンスを理解するのに役立ちますが、モデルの評価指標ではありません。したがって、scikit learn に最適な混同行列を持つモデルを選択するように指示することはできません。ただし、混同行列から計算できるメトリクスは多数あり、それらをモデルの選択に直接使用できます。

- テストセット内のすべての観測値は、正確に 1 つのボックス で表されます。
- 2 つの応答クラスがあるため、これは 2x2 行列です。
- ここに示されている形式は普遍的ではありません
基本的な用語をいくつか説明しましょう。
- 真陽性者 (TP): 私たちは彼らが糖尿病を持っていると正しく予測しました
- 真陰性 (TN): 私たちは彼らが糖尿病にいないと正しく予測しました
- 偽陽性 (FP): 私たちは、彼らが糖尿病を持っていると誤って予測しました (「タイプ I エラー」)
- 偽陰性 (FN): 私たちは、彼らが糖尿病ではないと誤って予測しました (「タイプ II エラー」)

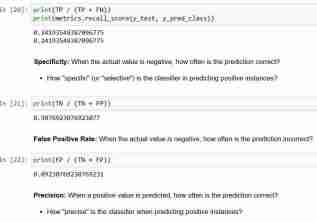
結論:
- 混同行列は、分類器がどのように実行されているかの
- より完全な全体像を提供します さまざまな
- 分類メトリクスを計算することもでき、これらのメトリクスはモデル選択のガイドとなります
以上が機械学習分類モデルの評価の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Pythonと時間:勉強時間を最大限に活用するApr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用するApr 14, 2025 am 12:02 AM限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 Python:ゲーム、GUIなどApr 13, 2025 am 12:14 AM
Python:ゲーム、GUIなどApr 13, 2025 am 12:14 AMPythonはゲームとGUI開発に優れています。 1)ゲーム開発は、2Dゲームの作成に適した図面、オーディオ、その他の機能を提供し、Pygameを使用します。 2)GUI開発は、TKINTERまたはPYQTを選択できます。 TKINTERはシンプルで使いやすく、PYQTは豊富な機能を備えており、専門能力開発に適しています。
 Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AM
Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AMPythonは、データサイエンス、Web開発、自動化タスクに適していますが、Cはシステムプログラミング、ゲーム開発、組み込みシステムに適しています。 Pythonは、そのシンプルさと強力なエコシステムで知られていますが、Cは高性能および基礎となる制御機能で知られています。
 2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM
2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM2時間以内にPythonの基本的なプログラミングの概念とスキルを学ぶことができます。 1.変数とデータ型、2。マスターコントロールフロー(条件付きステートメントとループ)、3。機能の定義と使用を理解する4。
 Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AM
Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AMPythonは、Web開発、データサイエンス、機械学習、自動化、スクリプトの分野で広く使用されています。 1)Web開発では、DjangoおよびFlask Frameworksが開発プロセスを簡素化します。 2)データサイエンスと機械学習の分野では、Numpy、Pandas、Scikit-Learn、Tensorflowライブラリが強力なサポートを提供します。 3)自動化とスクリプトの観点から、Pythonは自動テストやシステム管理などのタスクに適しています。
 2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM
2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM2時間以内にPythonの基本を学ぶことができます。 1。変数とデータ型を学習します。2。ステートメントやループの場合などのマスター制御構造、3。関数の定義と使用を理解します。これらは、簡単なPythonプログラムの作成を開始するのに役立ちます。
 プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM
プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM10時間以内にコンピューター初心者プログラミングの基本を教える方法は?コンピューター初心者にプログラミングの知識を教えるのに10時間しかない場合、何を教えることを選びますか...
 中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?Apr 02, 2025 am 07:15 AM
中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?Apr 02, 2025 am 07:15 AMfiddlereveryversings for the-middleの測定値を使用するときに検出されないようにする方法


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

ドリームウィーバー CS6
ビジュアル Web 開発ツール

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

