
MLOps: AI プロジェクトのパフォーマンスを向上させるツールキットを構築する方法

- 百草オリジナル
- 2024-09-04 13:35:57699ブラウズ
約束を掲げて立ち上げられた数多くの AI プロジェクトは、船出に失敗しています。これは通常、機械学習 (ML) モデルの品質によるものではありません。実装とシステム統合が不十分な場合、プロジェクトの 90% が失敗します。組織は AI の取り組みを節約できます。適切な MLOps プラクティスを採用し、適切なツール セットを選択する必要があります。この記事では、沈滞している AI プロジェクトを救い、堅牢な AI プロジェクトを促進し、プロジェクトの立ち上げ速度を 2 倍にする可能性がある MLOps の実践方法とツールについて説明します。

期待して立ち上げられた AI プロジェクトの多くは失敗に終わります。出航する。通常、これは機械学習(ML)モデルの品質によるものではありません。実装とシステム統合が不十分な場合、プロジェクトの 90% が失敗します。組織は AI の取り組みを節約できます。適切な MLOps プラクティスを採用し、適切なツール セットを選択する必要があります。この記事では、沈みかけている AI プロジェクトを節約し、堅牢な AI プロジェクトを促進して、プロジェクトの起動速度を 2 倍にする可能性がある MLOps のプラクティスとツールについて説明します。
MLOps の概要
MLOps は、機械学習アプリケーション開発を組み合わせたものです (開発)と運用活動(Ops)。これは、ML モデルのデプロイを自動化および合理化するのに役立つ一連のプラクティスです。その結果、ML ライフサイクル全体が標準化されます。
MLOps は複雑です。データ管理、モデル開発、運用の間の調和が必要です。また、組織内のテクノロジーや文化の変化も必要になる場合があります。 MLOps をスムーズに導入できれば、専門家はデータのラベル付けなどの面倒なタスクを自動化し、展開プロセスを透明化できます。これは、プロジェクト データが安全であり、データ プライバシー法に準拠していることを確認するのに役立ちます。
組織は、MLOps の実践を通じて ML システムを強化および拡張します。これにより、データ サイエンティストとエンジニアのコラボレーションがより効果的になり、イノベーションが促進されます。
課題から AI プロジェクトを紡ぎ出す
MLOps プロフェッショナルは、生のビジネス課題を合理化された測定可能な機械学習目標に変換します。彼らは ML パイプラインを設計および管理し、AI プロジェクトのライフサイクル全体を通じて徹底したテストと説明責任を保証します。
ユースケース発見と呼ばれる AI プロジェクトの初期段階では、データ サイエンティストは企業と協力して問題を定義します。それを ML の問題ステートメントに変換し、明確な目標と KPI を設定します。
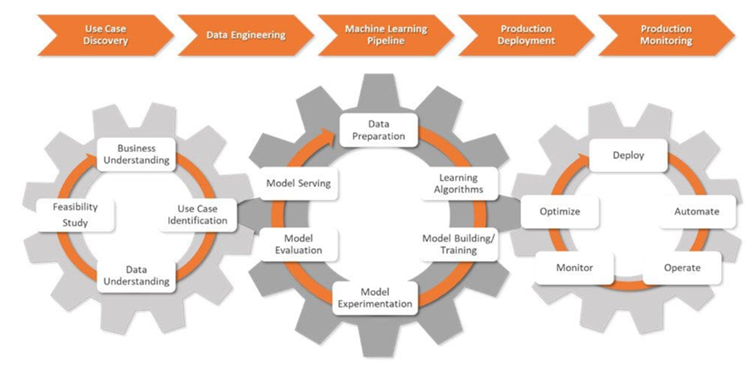
次に、データ サイエンティストはデータ エンジニアとチームを組みます。さまざまなソースからデータを収集し、このデータをクリーンアップ、処理、検証します。
データのモデリングの準備ができたら、データ サイエンティストは、CI/CD プロセスと統合された堅牢な ML パイプラインを設計してデプロイします。これらのパイプラインはテストと実験をサポートし、すべての実験にわたってデータ、モデル系統、関連する KPI を追跡するのに役立ちます。
本番環境のデプロイ段階では、ML モデルは選択した環境 (クラウド、オンプレミス、ハイブリッド) にデプロイされます。 。
データ サイエンティストは、主要な指標を使用してモデルとインフラストラクチャを監視し、データやモデルのパフォーマンスの変化を特定します。変更を検出すると、アルゴリズム、データ、ハイパーパラメーターが更新され、新しいバージョンの ML パイプラインが作成されます。また、メモリとコンピューティング リソースも管理して、モデルのスケーラビリティとスムーズな実行を維持します。
MLOps ツールと AI プロジェクトの融合
クライアントの製品設計プロセスを強化するために AI アプリケーションを開発しているデータ サイエンティストを想像してください。このソリューションは、指定されたパラメーターに基づいて AI によって生成された設計の代替案を提供することで、プロトタイピング段階を加速します。
データ サイエンティストは、フレームワークの設計から AI モデルのリアルタイム監視まで、さまざまなタスクを実行します。適切なツールと、各段階での使用方法の把握が必要です。
LLM パフォーマンスの向上、AI アプリのスマート化
正確で適応性のある AI ソリューションの中核となるのは、ベクトル データベースと、LLM のパフォーマンスを向上させるための重要なツールです:
Guardrails は、データ サイエンティストが LLM 出力に構造、型、品質チェックを追加するのに役立つオープンソースの Python パッケージです。エラーを自動的に処理し、検証が失敗した場合は LLM の再クエリなどのアクションを実行します。また、JSON などの出力構造と型の保証も強制されます。
データ サイエンティストは、大規模なデータセットを効率的にインデックス付け、検索、分析するためのツールを必要としています。ここで、LlamaIndex が介入します。このフレームワークは、広範な情報リポジトリを管理し、そこから洞察を抽出するための強力な機能を提供します。
DUST フレームワークにより、LLM を利用したアプリケーションを実行コードなしで作成およびデプロイできます。 。これは、モデル出力のイントロスペクションに役立ち、反復的な設計の改善をサポートし、さまざまなソリューションのバージョンを追跡します。
実験の追跡とモデルのメタデータの管理
データ サイエンティストは、時間の経過とともに ML モデルをより深く理解し、改善するために実験を行います。現実世界の結果に基づいてモデルの精度と効率を向上させるシステムをセットアップするためのツールが必要です。
MLflow はオープンソースの強力なツールであり、ML ライフサイクル全体を監視するのに役立ちます。実験の追跡、モデルのバージョン管理、展開機能などの機能を提供します。このスイートを使用すると、データ サイエンティストは実験の記録と比較、指標の監視、ML モデルとアーティファクトの整理を行うことができます。
Comet ML は、ML モデルとモデルを追跡、比較、説明、最適化するためのプラットフォームです。実験。データサイエンティストは、Scikit-learn、PyTorch、TensorFlow、または HuggingFace とともに Comet ML を使用できます。これにより、ML モデルを改善するための洞察が得られます。
Amazon SageMaker は、機械学習のライフサイクル全体をカバーします。データのラベル付けと準備に加え、複雑な ML モデルの構築、トレーニング、デプロイにも役立ちます。このツールを使用すると、データ サイエンティストはさまざまな環境にモデルを迅速にデプロイし、スケーリングできます。
Microsoft Azure ML は、機械学習ワークフローの合理化に役立つクラウドベースのプラットフォームです。 TensorFlow や PyTorch などのフレームワークをサポートしており、他の Azure サービスと統合することもできます。このツールは、データ サイエンティストによる実験の追跡、モデル管理、デプロイメントに役立ちます。
DVC (データ バージョン コントロール) は、大規模なデータ セットや機械学習の実験を処理することを目的としたオープンソース ツールです。このツールにより、データ サイエンスのワークフローがより俊敏で再現可能になり、共同作業が可能になります。 DVC は Git などの既存のバージョン管理システムと連携し、データ サイエンティストが変更を追跡し、複雑な AI プロジェクトの進捗状況を共有する方法を簡素化します。
ML ワークフローの最適化と管理
データ サイエンティストが必要とするワークフローを最適化し、AI プロジェクトのよりスムーズで効果的なプロセスを実現します。次のツールが役立ちます。
Prefect は、データ サイエンティストがワークフローの監視と調整に使用する最新のオープンソース ツールです。軽量で柔軟で、ML パイプライン (Prefect Orion UI および Prefect Cloud) を管理するオプションがあります。
Metaflow は、ワークフローを管理するための強力なツールです。データサイエンスと機械学習を対象としています。 MLOps の複雑さに煩わされることなく、モデル開発に集中することが容易になります。
Kedro は、データ サイエンティストがプロジェクトを再現可能、モジュール式で維持しやすい状態に保つのに役立つ Python ベースのツールです。これは、主要なソフトウェア エンジニアリングの原則を機械学習 (モジュール性、関心事の分離、バージョン管理) に適用します。これは、データ サイエンティストが効率的でスケーラブルなプロジェクトを構築するのに役立ちます。
データとパイプライン バージョンの管理
ML ワークフローには、正確なデータ管理とパイプラインの整合性が必要です。適切なツールを使用すると、データ サイエンティストはこれらのタスクを常に管理し、最も複雑なデータの課題にも自信を持って対処できます。
Pachyderm は、データ サイエンティストによるデータ変換の自動化を支援し、データのバージョニング、リネージ、エンドツーエンドのパイプラインのための堅牢な機能を提供します。これらの機能は Kubernetes 上でシームレスに実行できます。 Pachyderm は、画像、ログ、ビデオ、CSV、および複数の言語 (Python、R、SQL、C/C) など、さまざまなデータ タイプとの統合をサポートしています。ペタバイトのデータと数千のジョブを処理できるように拡張できます。
LakeFS は、拡張性を考慮して設計されたオープンソース ツールです。 Git のようなバージョン管理をオブジェクト ストレージに追加し、エクサバイト スケールでのデータ バージョン管理をサポートします。このツールは、大規模なデータレイクを処理するのに最適です。データ サイエンティストは、このツールを使用して、コードを処理するのと同じくらい簡単にデータ レイクを管理します。
品質と公平性を確保するために ML モデルをテストします
データ サイエンティストは、より信頼性の高い開発に重点を置いていますそして公平な ML ソリューション。モデルをテストしてバイアスを最小限に抑えます。適切なツールは、精度や AUC などの主要な指標を評価し、エラー分析とバージョン比較、ドキュメント プロセスをサポートし、ML パイプラインにシームレスに統合するのに役立ちます。
Deepchecks は、以下を支援する Python パッケージです。 ML モデルとデータ検証を使用します。また、モデルのパフォーマンス チェック、データの整合性、分布の不一致も緩和されます。
Truera は、データ サイエンティストが ML モデルの信頼性と透明性を高めるのに役立つ最新のモデル インテリジェンス プラットフォームです。このツールを使用すると、モデルの動作を理解し、問題を特定し、バイアスを軽減できます。 Truera は、モデルのデバッグ、説明可能性、公平性評価の機能を提供します。
Kolena は、厳密なテストとデバッグを通じてチームの連携と信頼を強化するプラットフォームです。結果と洞察を記録するためのオンライン環境を提供します。その焦点は、大規模な ML 単体テストと検証です。これは、さまざまなシナリオにわたって一貫したモデルのパフォーマンスの鍵となります。
モデルに命を吹き込む
データ サイエンティストには信頼できるツールが必要ですML モデルを効率的にデプロイし、予測を確実に提供します。次のツールは、スムーズでスケーラブルな ML 運用の実現に役立ちます。
BentoML は、データ サイエンティストが本番環境で ML 運用を処理するのに役立つオープン プラットフォームです。これは、モデルのパッケージ化を合理化し、サービス提供ワークロードを最適化して効率を高めるのに役立ちます。また、予測サービスの迅速なセットアップ、デプロイ、モニタリングにも役立ちます。
Kubeflow は、Kubernetes (ローカル、オンプレミス、またはクラウド) への ML モデルのデプロイを簡素化します。このツールを使用すると、プロセス全体が簡単になり、移植可能でスケーラブルになります。データの準備から予測の提供まですべてをサポートします。
エンドツーエンドの MLOps プラットフォームで ML ライフサイクルを簡素化
エンドツーエンドの MLOps プラットフォームは、機械学習のライフサイクルを最適化し、合理化されたアプローチを提供するために不可欠です。 ML モデルを効果的に開発、デプロイ、管理することができます。この分野の主要なプラットフォームをいくつか紹介します。
Amazon SageMaker は、データサイエンティストが ML ライフサイクル全体を処理するのに役立つ包括的なインターフェイスを提供します。データの前処理、モデルのトレーニング、実験を合理化し、データ サイエンティスト間のコラボレーションを強化します。組み込みアルゴリズム、自動モデル調整、AWS サービスとの緊密な統合などの機能を備えた SageMaker は、スケーラブルな機械学習ソリューションの開発とデプロイに最適です。
Microsoft Azure ML Platform は、さまざまなプログラミング言語とフレームワークをサポートするコラボレーション環境。データ サイエンティストは、事前に構築されたモデルを使用し、ML タスクを自動化し、他の Azure サービスとシームレスに統合できるため、クラウドベースの ML プロジェクトにとって効率的でスケーラブルな選択肢となります。
Google Cloud Vertex AI は、AutoML による自動モデル開発と、一般的なフレームワークを使用したカスタム モデル トレーニングの両方にシームレスな環境を提供します。統合されたツールと Google Cloud サービスへの簡単なアクセスにより、Vertex AI は ML プロセスの簡素化に最適であり、データ サイエンス チームがモデルを簡単かつ大規模に構築およびデプロイできるように支援します。
サインオフ
MLOps は単なる誇大広告ではありません。これは、専門家が大量のデータをより迅速、正確、簡単にトレーニングおよび分析するのに役立つ重要な分野です。これが今後 10 年間でどのように進化するかは想像することしかできませんが、AI、ビッグデータ、自動化が勢いを増し始めていることは明らかです。
以上がMLOps: AI プロジェクトのパフォーマンスを向上させるツールキットを構築する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。