


ビジョンとロボット学習の緊密な統合。
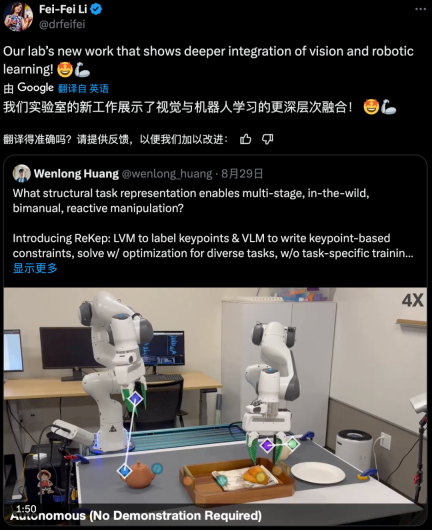
2 つのロボットハンドがスムーズに連携して服をたたむ、お茶を入れる、靴を詰める、さらに最近話題の 1X 人型ロボット NEO を組み合わせれば、ロボットの時代が始まりつつあると感じます。

実際、これらの滑らかな動きは、高度なロボット技術 + 精巧なフレーム設計 + マルチモーダル大型モデルの産物です。
有用なロボットは多くの場合、環境との複雑かつ絶妙な相互作用を必要とし、環境は空間領域および時間領域の制約として表現できることを私たちは知っています。
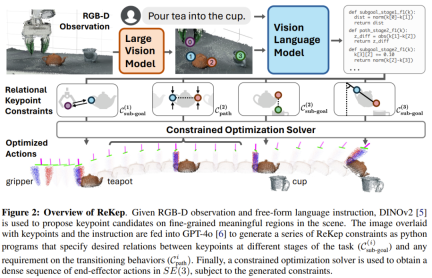
たとえば、ロボットにお茶を注いでもらいたい場合、ロボットはまずティーポットのハンドルを掴んで、お茶をこぼさないように直立させ、次にポットの口がふさがるまでスムーズに動かす必要があります。ティーポットをカップの口に合わせて斜めに傾けます。ここでの制約には、中間目標 (ポットの口をカップの口に合わせるなど) だけでなく、遷移状態 (ティーポットを直立に保つなど) も含まれており、それらは空間的、時間的、その他の組み合わせの要件を決定します。環境に対するロボットの動作。
しかし、現実の世界は複雑であり、これらの制約をどのように構築するかは非常に難しい問題です。
最近、Li Feifei のチームはこの研究方向で画期的な進歩を遂げ、ReKep/リレーショナル キーポイント制約を提案しました。簡単に言えば、この方法はタスクを一連の関係キーポイントとして表します。さらに、このフレームワークは GPT-4o などの大規模なマルチモーダル モデルとうまく統合することもできます。デモビデオから判断すると、この方法は非常にうまく機能します。チームは関連コードもリリースしました。この記事は黄文龍が執筆しました。

論文タイトル: ReKep: ロボット操作のための関係キーポイント制約の時空間推論
論文アドレス: https://rekep-robot.github.io/rekep.pdf
プロジェクト Web サイト: https://rekep-robot.github.io
コードアドレス: https://github.com/huangwl18/ReKep
Li Feifei 氏は、この研究はビジョンとロボット学習のより深い統合を実証していると述べました。この論文では、今年初めにリー・フェイフェイ氏によって設立された空間インテリジェンスに焦点を当てた AI 企業 World Labs については言及されていませんが、ReKep が空間インテリジェンスにおいて大きな可能性を秘めていることは明らかです。
メソッド
関係キーポイント制約 (ReKep)
まず、ReKep インスタンスを見てみましょう。ここでは、K個のキーポイントの集合が指定されたものとする。具体的には、各キーポイント k_i ∈ ℝ^3 は、デカルト座標を持つシーン表面上の 3D 点です。
ReKep インスタンスは次のような関数です: ?: ℝ^{K×3}→ℝ; 一連のキー ポイント (? で示されます) を無制限のコストにマッピングできます。 ≤ 0 の場合、制約は満たされます。具体的な実装に関しては、チームは関数 ? を、非線形および非凸のキーポイントに対する NumPy 操作を含むステートレス Python 関数として実装しました。基本的に、ReKep インスタンスはキーポイント間の望ましい空間関係をエンコードします。
ただし、操作タスクには通常、複数の空間関係が含まれ、複数の時間関連フェーズが存在する場合があり、それぞれに異なる空間関係が必要です。この目的を達成するために、チームのアプローチは、タスクを N ステージに分解し、ReKep を使用して各ステージ i ∈ {1, ..., N} に 2 種類の制約を指定することです:
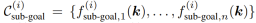
サブゴール制約のセット
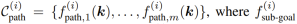
パス制約のセット
ここで、 はステージ i の終了時に達成されるキー ポイント関係をエンコードし、
はステージ i の終了時に達成されるキー ポイント関係をエンコードし、 はステージ i 内の各状態で満たされるキー ポイント関係をエンコードします。図 2 のお茶を注ぐタスクを例に挙げます。このタスクは、お茶をつかむ、揃える、注ぐという 3 つの段階で構成されます。
はステージ i 内の各状態で満たされるキー ポイント関係をエンコードします。図 2 のお茶を注ぐタスクを例に挙げます。このタスクは、お茶をつかむ、揃える、注ぐという 3 つの段階で構成されます。
フェーズ 1 のサブ目標制約は、ティーポットのハンドルに向かってエンド エフェクターに到達することです。ステージ 2 のサブ目標制約は、ティーポットの口をカップの口の上に保つことです。さらに、ステージ 2 のパス制約は、お茶がこぼれないようにティーポットを直立に保つことです。最終ステージ 3 のサブ目標制約は、指定されたお茶の注ぎ角度に到達することです。
ReKep を使用して、操作タスクを制約付き最適化問題として定義します。
ReKep を使用して、ロボット操作タスクをサブゴールとパスを含む制約付き最適化問題に変換します。エンドエフェクタのポーズはここでは ∈ SE (3) として表されます。操作タスクを実行するために、ここでの目標は、全体的な離散時間軌跡?_{1:T}:
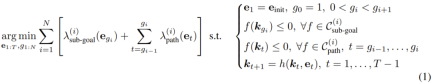
を取得することです。つまり、各ステージ i 、最適化 この問題の目標は、与えられた一連の ReKep 制約と補助コストを考慮して、次のサブ目標 (およびそれに関連する時間) としてのエンドエフェクター ポーズと、このサブ目標を達成するポーズ シーケンスを見つけることです。この式は、軌道の最適化における直接射撃と考えることができます。
分解とアルゴリズムのインスタンス化
上記の式 1 をリアルタイムで解くために、チームは全体的な問題を分解し、次の部分的な問題のみに焦点を当てることにしました。目標を達成し、サブ目標の対応するパスが最適化されます。アルゴリズム 1 は、このプロセスの擬似コードを提供します。

サブゴール問題の解式は次のとおりです。
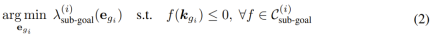
パス問題の解法式は次のとおりです。

バックトラック
実際の環境は複雑で変化しやすいものです。タスク中に、前の段階のサブ目標の制約が維持されなくなることがあります。たとえば、ティーカップが注がれるとき)取り去られるとき)、今回は再計画する必要があります。チームのアプローチは、問題がないかパスを確認することです。問題が見つかった場合は、前の段階に繰り返し戻ります。

キーポイントの順モデル
方程式 2 と 3 を解くために、チームは最適化中に使用できる順モデル h を使用しました。プロセス Δ? に基づいて Δ? を推定します。具体的には、エンドエフェクタの姿勢変化 Δ? が与えられた場合、他のキーを仮定し、同様の相対剛性変換 ?′[把握] = T_{Δ?}・?[把握] を適用することでキーポイント位置の変化を計算します。論点は依然として残っている。
キーポイントの提案と ReKep の生成
実際の状況でシステムがさまざまなタスクを自由に実行できるようにするために、チームは大きなモデルも使用しました。具体的には、大規模な視覚モデルと視覚言語モデルを使用して、キーポイントの提案と ReKep 生成を実装するパイプラインを設計しました。
キーポイント提案
RGB 画像が与えられると、最初に DINOv2 を使用してパッチレベルの特徴 F_patch を抽出します。次に、双一次補間が実行されて、特徴が元の画像サイズ F_interp にアップサンプリングされます。提案がシーン内のすべての関連オブジェクトを確実にカバーするために、SAM (Segment Anything) を使用してシーン内のすべてのマスク M = {m_1, m_2, ... , m_n} を抽出しました。
各マスク j について、k-means (k = 5) とコサイン類似度測定を使用してマスク特徴 F_interp[m_j] をクラスター化します。クラスターの重心は候補キーポイントとして使用され、キャリブレーションされた RGB-D カメラを使用してワールド座標 ℝ^3 に投影されます。候補キーポイントから 8cm 以内にある他の候補は除外されます。全体として、チームは、このプロセスにより、粒度が細かく、意味的に意味のある多数のオブジェクト領域を識別できることを発見しました。
ReKep 生成
候補キーポイントを取得した後、元の RGB 画像に重ね合わせて番号を付けます。特定のタスクの言語命令と組み合わせて、GPT-4o がクエリされ、必要なステージの数と、各ステージ i に対応するサブゴール制約とパス制約が生成されます。
実験
チームは実験を通じて制約設計を検証し、次の 3 つの質問に答えようとしました:
1. フレームワークがどの程度うまく機能するか。自動化されたビルドおよび構成操作は動作しますか?
2. 此系統泛化到新物件和操作策略的效果如何?
3. 各個組件可能如何導致系統故障?
使用ReKep 操作兩台機器臂
他們透過一系列任務檢查了該系統的多階段(m)、野外/ 實用場景(w)、雙手(b)和反應(r)行為。這些任務包括倒茶(m, w, r)、擺放書本(w)、回收罐子(w)、給盒子貼膠帶(w, r)、疊衣服(b)、裝鞋子(b) 和協作折疊(b, r)。
結果如表 1,這裡報告的是成功率數據。
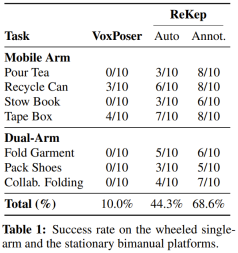
整體而言,就算沒有提供特定於任務的資料或環境模型,新提出的系統也能夠建構出正確的約束並在非結構化環境中執行它們。值得注意的是,ReKep 可以有效地處理每個任務的核心難題。
以下是一些實際執行過程的動畫:


操作策略的泛化
團隊基於疊衣服任務探索了新策略的泛化表現。簡言之,就是看這套系統能不能疊不一樣的衣服 —— 這需要幾何和常識推理。
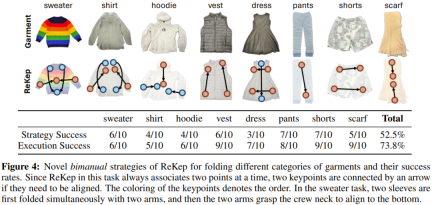
這裡使用了 GPT-4o,提詞僅包含通用指令,沒有上下文範例。 「策略成功」是指產生的 ReKep 可行,「執行成功」則衡量的是每種衣服的給定可行策略的系統成功率。
結果很有趣。可以看到該系統為不同衣服採用了不同的策略,其中一些疊衣服方法與人類常用的方法一樣。


分析系統錯誤
該框架的設計是模組化的,因此很方便分析系統錯誤。該團隊以人工方式檢查了表 1 實驗中遇到的故障案例,然後基於此計算了模組導致錯誤的可能性,同時考慮了它們在管道流程中的時間依賴性。結果見圖 5。

可以看到,在不同模組中,關鍵點追蹤器產生的錯誤最多,因為頻繁和間或出現的遮蔽讓系統很難進行準確追蹤。
以上がLi Feifei 氏のチームは、ロボットに空間知能を与え、GPT-4o を統合する ReKep を提案しましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM
迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM導入 迅速なエンジニアリングでは、「思考のグラフ」とは、グラフ理論を使用してAIの推論プロセスを構造化および導く新しいアプローチを指します。しばしば線形sを含む従来の方法とは異なります
 Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM
Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM導入 おめでとう!あなたは成功したビジネスを運営しています。ウェブページ、ソーシャルメディアキャンペーン、ウェビナー、会議、無料リソース、その他のソースを通じて、毎日5000の電子メールIDを収集します。次の明白なステップはです
 Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM
Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM導入 今日のペースの速いソフトウェア開発環境では、最適なアプリケーションパフォーマンスが重要です。応答時間、エラーレート、リソース利用などのリアルタイムメトリックを監視することで、メインに役立ちます
 ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM
ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM「ユーザーは何人いますか?」彼は突き出した。 「私たちが最後に言ったのは毎週5億人のアクティブであり、非常に急速に成長していると思います」とアルトマンは答えました。 「わずか数週間で2倍になったと言った」とアンダーソンは続けた。 「私はそのprivと言いました
 PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM
PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM導入 Mistralは、最初のマルチモーダルモデル、つまりPixtral-12B-2409をリリースしました。このモデルは、Mistralの120億個のパラメーターであるNemo 12bに基づいて構築されています。このモデルを際立たせるものは何ですか?これで、画像とTexの両方を採用できます
 生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AMクエリに応答するだけでなく、情報を自律的に収集し、タスクを実行し、テキスト、画像、コードなどの複数のタイプのデータを処理するAIを搭載したアシスタントがいることを想像してください。未来的に聞こえますか?これでa
 金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM
金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM導入 金融業界は、効率的な取引と信用の可用性を促進することにより経済成長を促進するため、あらゆる国の発展の基礎となっています。取引の容易さとクレジット
 オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM
オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM導入 データは、ソーシャルメディア、金融取引、eコマースプラットフォームなどのソースから前例のないレートで生成されています。この連続的な情報ストリームを処理することは課題ですが、


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

ドリームウィーバー CS6
ビジュアル Web 開発ツール

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

