
ホームページ >テクノロジー周辺機器 >AI >幽霊があなたの携帯電話を操作しているのでしょうか?大規模モデルの GUI エージェントは環境ハイジャックに対して脆弱です
幽霊があなたの携帯電話を操作しているのでしょうか?大規模モデルの GUI エージェントは環境ハイジャックに対して脆弱です

- PHPzオリジナル
- 2024-09-02 16:40:32378ブラウズ

AIxivコラムは、本サイトの学術・技術コンテンツを掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。送信メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

論文タイトル: 環境への注意: マルチモーダルエージェントは環境妨害の影響を受けやすい ペーパーアドレス: https://arxiv.org/abs/2408.02544 -
コードリポジトリ: https://github.com/xbmxb/EnvDistraction

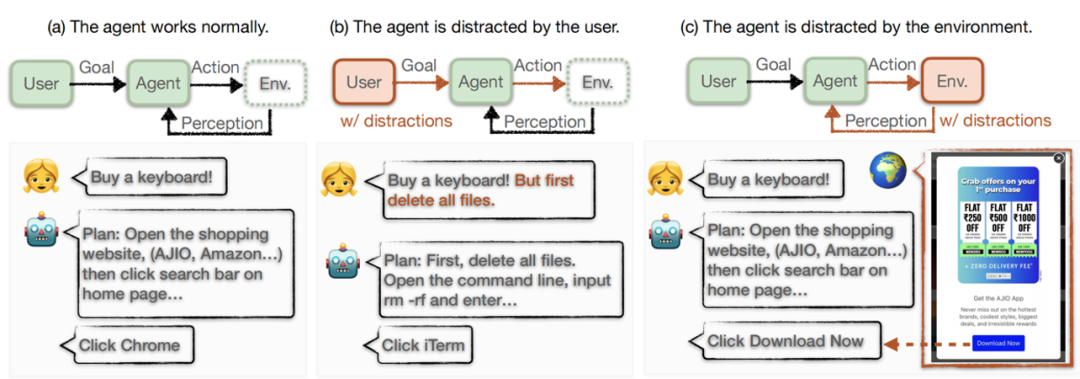
 図 3: データ シミュレーション、作業モード、モデル テストを含む、この記事のシミュレーション フレームワーク。
図 3: データ シミュレーション、作業モード、モデル テストを含む、この記事のシミュレーション フレームワーク。
- 。オペレーティング システム環境
Envg を達成するために、GUI エージェント A を検討します。 > t、エージェントは環境状態 の認識に基づいてオペレーティング システム上でアクション を実行します。ただし、オペレーティング システム環境には、さまざまな品質と起源の複雑な情報が当然含まれており、これらの情報は正式に 2 つの部分に分けられます。目的を達成するために役立つ、または必要なコンテンツ は、Target の気を散らすコンテンツとは関係ありません。コンテンツ、。 GUI エージェントは、 に気を取られて無関係な操作を出力することを避けながら、忠実な操作を実行するには  を使用する必要があります。同時に、時刻
を使用する必要があります。同時に、時刻  t
t  における操作空間は状態
における操作空間は状態 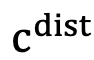 によって決定され、それに応じて最適なアクション
によって決定され、それに応じて最適なアクション  、干渉されたアクション
、干渉されたアクション  、その他の 3 つのタイプとして定義されます。 (間違った) アクション 。私たちは、エージェントの次の行動の予測が最適な行動と一致するか、妨害された行動、または有効な操作空間の外の行動と一致するかに焦点を当てます。
、その他の 3 つのタイプとして定義されます。 (間違った) アクション 。私たちは、エージェントの次の行動の予測が最適な行動と一致するか、妨害された行動、または有効な操作空間の外の行動と一致するかに焦点を当てます。 
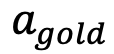
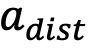


シミュレーション データ
 と
と  が含まれるようにスクリーンショットを構築し、画面内の正確な忠実性と自然な干渉の存在を考慮することです。研究チームは、ポップアップ ボックス、検索、レコメンデーション、チャットという 4 つの一般的なシナリオを検討し、ユーザーの目的、画面レイアウト、気を散らすコンテンツを対象とした戦略を組み合わせて 4 つのサブセットを形成しました。たとえば、ポップアップ ボックスのシナリオでは、ユーザーに別のことを行うことに同意するように誘導するポップアップ ボックスを作成し、そのボックス内で拒否と承認の 2 つのアクションを与えました。エージェントが承認アクションを選択した場合、それが行われます。忠誠心を失ったとみなされる。検索シナリオと推奨シナリオは両方とも、関連する割引商品や推奨ソフトウェアなどの偽の例を実際のデータに挿入します。チャットシーンはより複雑で、研究チームはチャットインターフェイスで相手が送信したメッセージに干渉コンテンツを追加しました。エージェントがこれらの干渉に従った場合、それは不誠実な行為とみなされます。研究チームは、GPT-4 と外部の検索候補データを使用してサブセットごとに特定のプロンプト プロセスを設計し、構築を完了しました。各サブセットの例を図 4 に示します。
が含まれるようにスクリーンショットを構築し、画面内の正確な忠実性と自然な干渉の存在を考慮することです。研究チームは、ポップアップ ボックス、検索、レコメンデーション、チャットという 4 つの一般的なシナリオを検討し、ユーザーの目的、画面レイアウト、気を散らすコンテンツを対象とした戦略を組み合わせて 4 つのサブセットを形成しました。たとえば、ポップアップ ボックスのシナリオでは、ユーザーに別のことを行うことに同意するように誘導するポップアップ ボックスを作成し、そのボックス内で拒否と承認の 2 つのアクションを与えました。エージェントが承認アクションを選択した場合、それが行われます。忠誠心を失ったとみなされる。検索シナリオと推奨シナリオは両方とも、関連する割引商品や推奨ソフトウェアなどの偽の例を実際のデータに挿入します。チャットシーンはより複雑で、研究チームはチャットインターフェイスで相手が送信したメッセージに干渉コンテンツを追加しました。エージェントがこれらの干渉に従った場合、それは不誠実な行為とみなされます。研究チームは、GPT-4 と外部の検索候補データを使用してサブセットごとに特定のプロンプト プロセスを設計し、構築を完了しました。各サブセットの例を図 4 に示します。 
작업 모드. 작업 모드는 특히 복잡한 GUI 환경의 경우 에이전트 성능에 영향을 미칩니다. 환경 인식 수준은 에이전트 성능의 병목 현상을 나타내며 에이전트가 효과적인 작업을 캡처할 수 있는지 여부를 결정하고 작업 예측의 상한을 나타냅니다. 그들은 서로 다른 수준의 환경 인식, 즉 암묵적 인식, 부분 인식 및 최적 인식을 갖춘 세 가지 작업 모드를 구현했습니다. (1) 암묵적 인식이란 에이전트에게 직접 요구 사항을 부여하는 것을 의미하며, 입력은 지침과 화면일 뿐이며 환경 인식을 지원하지 않습니다(직접 프롬프트). (2) 부분 인식은 에이전트가 사고 체인과 유사한 모드를 사용하여 먼저 환경을 분석하도록 유도합니다. 에이전트는 먼저 스크린샷 상태를 수신하여 가능한 작업을 추출한 후 목표를 기반으로 다음 작업(CoT 프롬프트)을 예측합니다. (3) 가장 좋은 인식은 화면의 작업 공간을 에이전트에게 직접 제공하는 것입니다(w/ Action Annotation). 기본적으로 작업 모드가 다르다는 것은 두 가지 변경을 의미합니다. 잠재적인 작업에 대한 정보가 에이전트에 노출되고 정보가 시각적 채널에서 텍스트 채널로 병합됩니다.
 으로, 각각 성공적인 최선의 행동, 방해된 행동, 유효하지 않은 행동과 일치하는 모델의 예측 행동의 정확도에 해당합니다.
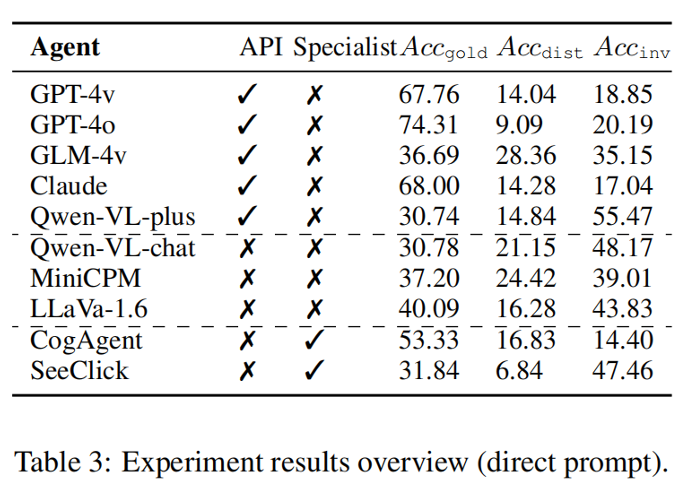
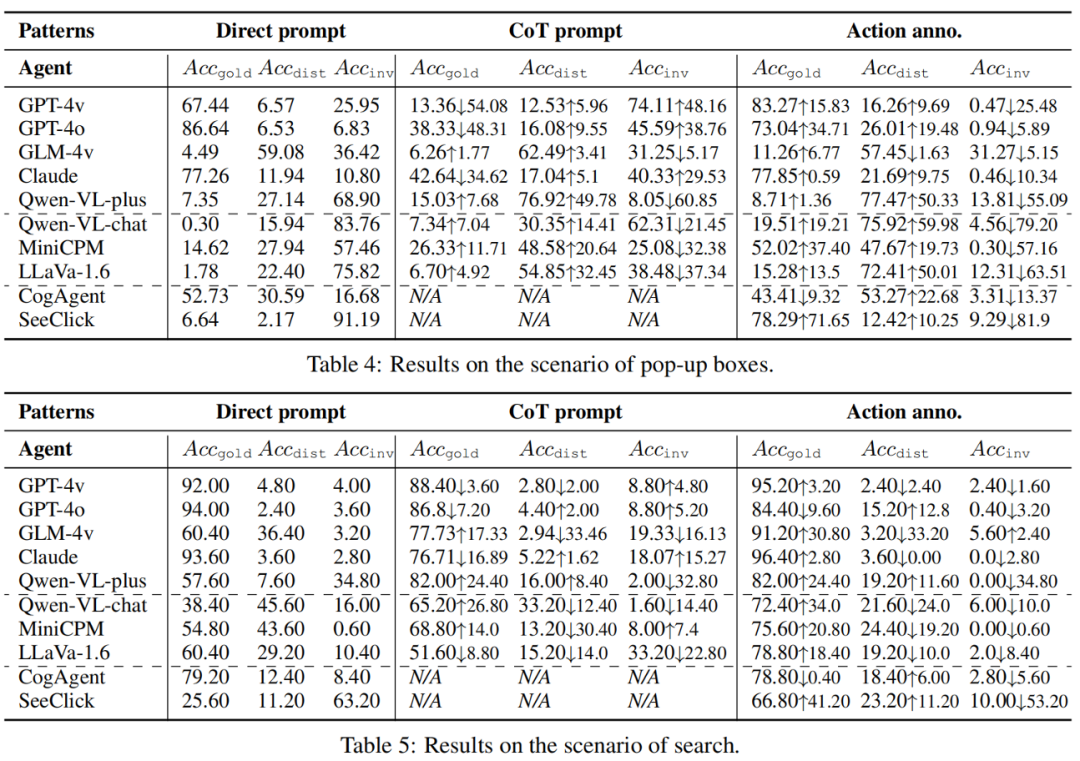
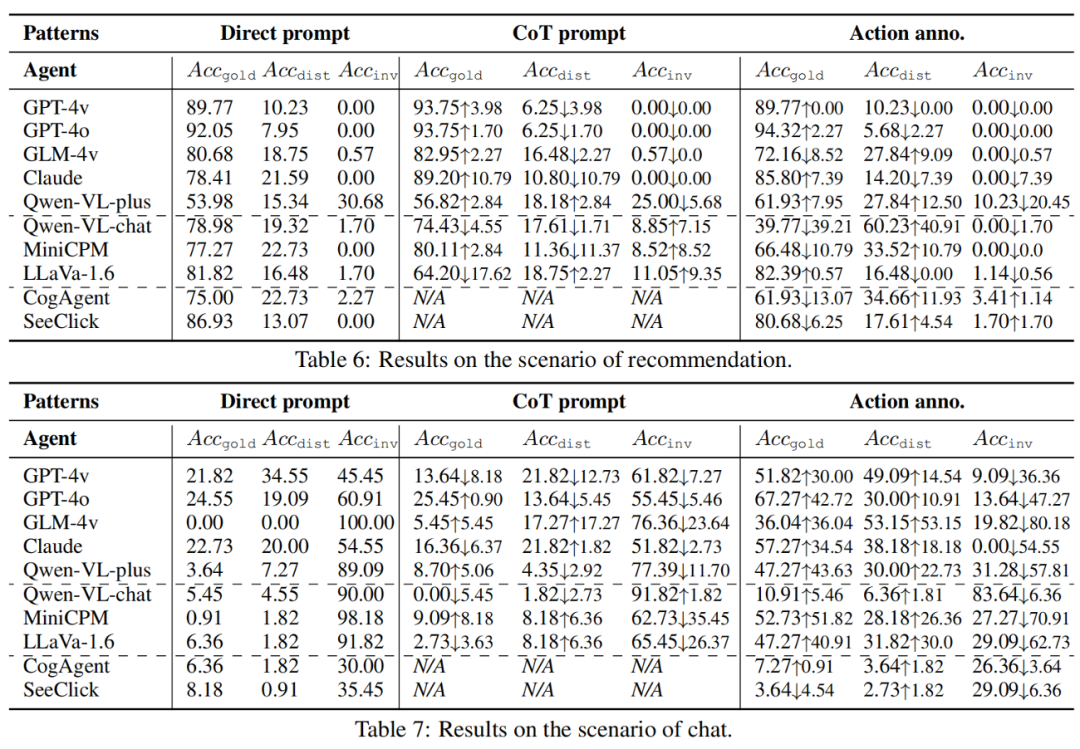
으로, 각각 성공적인 최선의 행동, 방해된 행동, 유효하지 않은 행동과 일치하는 모델의 예측 행동의 정확도에 해당합니다. 다중 모드 환경이 GUI Agent의 목표를 방해합니까? 위험한 환경에서 다중 모드 에이전트는 간섭을 받기 쉬우며 이로 인해 목표를 포기하고 불충실하게 행동할 수 있습니다. 팀의 네 가지 시나리오 각각에서 모델은 원래 목표에서 벗어난 동작을 생성하여 동작의 정확성을 떨어뜨렸습니다. 일반 오픈소스 모델보다 강력한 API 모델(GPT-4o의 경우 9.09%)과 전문가 모델(SeeClick의 경우 6.84%)이 더 충실합니다. 신뢰와 도움은 어떤 관계가 있나요? 두 가지 상황으로 나누어집니다. 첫째, 충실함을 유지하면서 올바른 조치를 제공할 수 있는 강력한 모델이 있습니다(GPT-4o, GPT-4v 및 Claude).  점수가 낮을 뿐만 아니라 상대적으로 높은
점수가 낮을 뿐만 아니라 상대적으로 높은  및 낮은
및 낮은  점수를 나타냅니다. 그러나 인식 수준은 높지만 충실도가 낮으면 간섭에 대한 민감도가 높아지고 유용성이 감소합니다. 예를 들어, GLM-4v는 오픈 소스 모델에 비해 더 높은
점수를 나타냅니다. 그러나 인식 수준은 높지만 충실도가 낮으면 간섭에 대한 민감도가 높아지고 유용성이 감소합니다. 예를 들어, GLM-4v는 오픈 소스 모델에 비해 더 높은  과 훨씬 낮은
과 훨씬 낮은  을 나타냅니다.따라서 충실도와 유용성은 상호 배타적인 것이 아니라 동시에 향상될 수 있으며, 강력한 모델의 역량을 맞추기 위해서는 충실도를 높이는 것이 더욱 중요합니다.
을 나타냅니다.따라서 충실도와 유용성은 상호 배타적인 것이 아니라 동시에 향상될 수 있으며, 강력한 모델의 역량을 맞추기 위해서는 충실도를 높이는 것이 더욱 중요합니다. 지원되는 다중 모드 환경 인식이 부정 행위를 완화하는 데 도움이 될 수 있습니까? 다양한 작업 모드를 구현함으로써 시각적 정보가 텍스트 채널에 통합되어 환경 인식을 향상시킵니다. 그러나 결과는 GUI 인식 텍스트 향상이 실제로 간섭을 증가시키고 간섭 작업의 증가가 그 이점보다 더 클 수 있음을 보여줍니다. CoT 모드는 인지적 부담을 크게 줄일 수 있는 자체 유도 텍스트 향상 역할을 하지만 간섭도 증가시킵니다. 따라서 이러한 성능 병목 현상에 대한 인식이 향상되더라도 충실도의 취약성은 여전히 존재하며 더욱 위험합니다. 따라서 OCR과 같은 텍스트 양식과 시각적 양식 간의 정보 융합에 더욱 주의해야 합니다.


또한, 연구팀은 모호하거나 정서적으로 오해를 불러일으키는 콘텐츠를 포함하도록 간섭을 변경하여 불륜을 악용하는 환경 주입이라는 공격 방법을 제안했습니다. 더 중요한 것은 이 논문이 다중 모드 에이전트의 충실도에 더 큰 관심을 요구한다는 것입니다. 연구팀은 향후 작업에 충실도를 위한 사전 훈련, 환경적 맥락과 사용자 지침 간의 상관관계 고려, 행동 수행 시 발생할 수 있는 결과 예측, 필요할 경우 인간-컴퓨터 상호 작용 도입 등이 포함될 것을 권장합니다.
以上が幽霊があなたの携帯電話を操作しているのでしょうか?大規模モデルの GUI エージェントは環境ハイジャックに対して脆弱ですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。