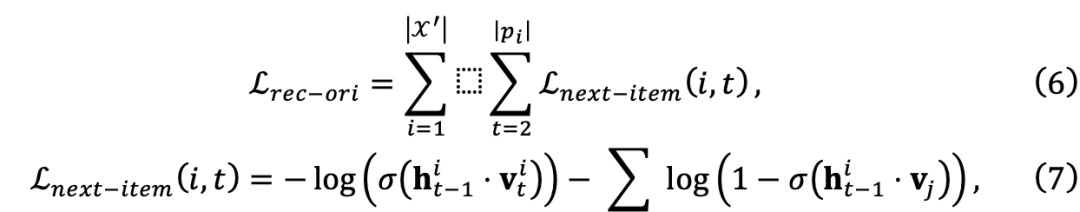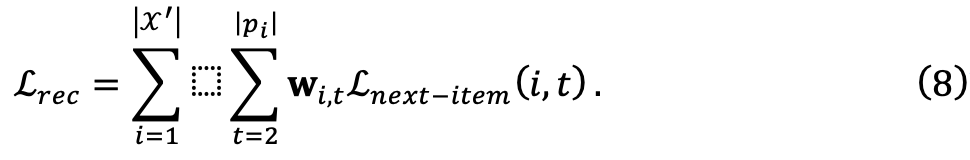AIxivコラムは、本サイト上で学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
この研究は、National Key Laboratory の IEEE Fellow によって後援されました。認知知能の研究は、Chen Enhong のチームと Huawei 社のノアの方舟研究所によって完成されました。 Chen Enhong 教授のチームはデータ マイニングと機械学習の分野に深く携わっており、トップ ジャーナルに多くの論文を発表しており、Google Scholar の論文は 20,000 回以上引用されています。ノアの方舟研究所は、人工知能の基礎研究に従事するファーウェイの研究所であり、理論研究と応用イノベーションを同等に重視するという概念を堅持し、人工知能分野における技術革新と開発の促進に取り組んでいます。 8月25日から29日までスペインのバルセロナで開催された第30回ACM Conference on Knowledge Discovery and Data Mining (KDD2024)に、大学認知知能国家重点研究所のChen Enhong教授が登壇しました。中国科学技術博士、IEEEフェロー、ファーウェイ・ノアと共同発表した論文「逐次推奨のためのデータセット再生成」が、2024年カンファレンスのリサーチトラックで唯一の最優秀学生論文賞を受賞した。論文の筆頭著者は、中国科学技術大学認知知能国家重点研究室のChen Enhong教授とLian Defu教授、そして准研究員としてWang Haote氏の共同指導を受けている博士課程学生のying Mingjia氏である。ファーウェイ・ノア・リウ・ヨン氏と研究者の郭偉氏もこの論文の関連研究に参加した。 KDDが2004年にこの賞を創設して以来、陳恩宏教授のチームの学生がこの賞を受賞するのは2回目となる。
- ペーパーリンク: https://arxiv.org/abs/2405.17795
- コードリンク: https://github.com/USTC -StarTeam/DR4SR
シーケンス推奨システム (Sequential Recommender、SR) は、ユーザーの変化する好みを捕捉することを目的としているため、最新のレコメンデーション システムの重要な部分です。近年、研究者は配列推奨システムの機能を強化するために多大な努力を払ってきました。これらの手法は通常、固定データセットに基づいて効果的なモデルを開発するというモデル中心のパラダイムに従います。ただし、このアプローチでは、潜在的な品質問題やデータの欠陥が見落とされることがよくあります。これらの問題を解決するために、学界は、固定モデルを使用して高品質のデータセットを生成することに焦点を当てたデータ中心のパラダイムを提案しました。私たちはこれを「データセット再構成」問題として枠組み付けします。 最良のトレーニング データを取得するために、研究チームの重要なアイデアは、アイテム転送パターンを明示的に含む新しいデータセットを学習することです。具体的には、レコメンダシステムのモデリングプロセスを、元のデータセットから転送パターン を抽出する段階と、に基づいてユーザーの好みを学習する段階の2段階に分けました。 からのマッピングの学習には 2 つの暗黙的なマッピング が含まれるため、このプロセスは困難です。この目的を達成するために、研究チームは、 のアイテム転送パターンを明示的に表すデータセットを開発する可能性を検討しました。これにより、学習プロセスを明示的に 2 つの段階に分けることができ、 の学習が比較的容易になります。したがって、彼らの主な焦点は、1 対多のマッピングである の効率的なマッピング関数を学習することです。研究チームは、図 1 に示すように、この学習プロセスをデータセット再生成パラダイムと定義しています。「再生成」とは、追加情報を導入せず、元のデータセットのみに依存することを意味します。
を抽出する段階と、に基づいてユーザーの好みを学習する段階の2段階に分けました。 からのマッピングの学習には 2 つの暗黙的なマッピング が含まれるため、このプロセスは困難です。この目的を達成するために、研究チームは、 のアイテム転送パターンを明示的に表すデータセットを開発する可能性を検討しました。これにより、学習プロセスを明示的に 2 つの段階に分けることができ、 の学習が比較的容易になります。したがって、彼らの主な焦点は、1 対多のマッピングである の効率的なマッピング関数を学習することです。研究チームは、図 1 に示すように、この学習プロセスをデータセット再生成パラダイムと定義しています。「再生成」とは、追加情報を導入せず、元のデータセットのみに依存することを意味します。
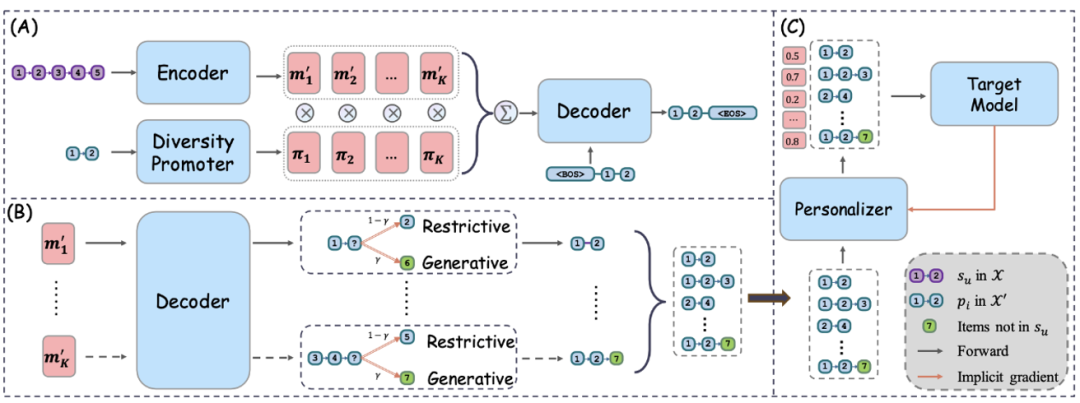
図 1パラダイム、シーケンス推奨のためのデータセット再生成 (DR4SR) は、元のデータセットを有益で一般化可能なデータセットに再構築することを目的としています。具体的には、研究チームはまず、データセットを再生成できるようにするための事前トレーニング タスクを構築しました。次に、彼らは、再生成プロセス中のシーケンスとパターンの間の 1 対多の関係をモデル化する、ダイバーシティを強化した再生成器を提案しました。最後に、彼らは、新しいデータセットを生成するための探索と活用のバランスをとるハイブリッド推論戦略を提案しています。 データセットの再構築プロセスは一般的ですが、特定のターゲット モデルには完全には適していない可能性があります。この問題を解決するために、研究チームは、ターゲット モデルの特性に応じてデータセットを調整するモデル認識型再生成プロセスである DR4SR+ を提案しました。 DR4SR+ はスコアリングをパーソナライズし、2 層の最適化問題と暗黙的な微分手法を通じて再構成されたデータセット内のパターンを最適化し、データセットの効果を高めます。
この研究では、研究チームは A データを提案しました。 「シーケンス推奨のためのデータ再生成」(DR4SR) と呼ばれる中心的なフレームワークは、図 2 に示すように、元のデータセットを有益で一般化可能なデータセットに再構築することを目的としています。データ再生成プロセスはターゲット モデルから独立しているため、再生成されたデータ セットがターゲット モデルの要件を必ずしも満たさない場合があります。したがって、研究チームは DR4SR をモデル認識バージョン、つまり DR4SR+ に拡張し、再生成されたデータセットを特定のターゲット モデルに合わせて調整しました。
図 2 rator を使用して、データセットの自動再生成を容易にします。ただし、元のデータセットには、データセット再生成器を学習するための監視情報が不足しています。したがって、自己教師あり学習の方法でこれを達成する必要があります。この目的を達成するために、彼らは、多様性を強化した再生器の学習をガイドする事前トレーニング タスクを導入しました。事前トレーニングを完了した後、研究チームはさらにハイブリッド推論戦略を使用して新しいデータセットを再生成しました。
データ再構成事前トレーニング タスクの構築:
に再生成できる必要があります。研究チームは、事前トレーニング データセット全体を
事前トレーニング タスクにより、研究チームはデータセット再生成器を事前トレーニングできるようになりました。この論文では、再生器の主なアーキテクチャとして Transformer モデルを採用しており、その発電能力は広く検証されています。データセット再生成器は、元のデータセット内のシーケンス表現を取得するエンコーダー、パターンを再生成するデコーダー、および 1 対多のマッピング関係をキャプチャするダイバーシティ強化モジュールの 3 つのモジュールで構成されます。次に、研究チームはこれらのモジュールを個別に紹介します。
エンコーダーは、複数のスタックされたマルチヘッド セルフ アテンション (MHSA) レイヤーとフィードフォワード ネットワーク (FFN) レイヤーで構成されます。デコーダに関しては、入力としてデータセット X' 内のパターンを再現します。デコーダの目的は、エンコーダによって生成されたシーケンス表現を考慮してパターン を再構築することです。ただし、シーケンスから複数のパターンを抽出することもできます。 . モード。トレーニング中に課題が発生する可能性があります。この1対多マッピングの問題を解決するために、研究チームはさらにダイバーシティ強化モジュールを提案しました。
具体的には、研究チームは、ターゲットパターンからの情報をデコード段階に統合することで、元のシーケンスの影響を適応的に調整します。まず、エンコーダによって生成されたメモリ を
個の異なるベクトル空間、つまり
に投影します。理想的には、異なるターゲット パターンが異なる記憶と一致する必要があります。この目的のために、ターゲット パターンをエンコードして
を取得するための Transformer エンコーダも導入しました。 を確率ベクトルに圧縮しました:
、
は k 番目のメモリを選択する確率です。各メモリ空間が完全にトレーニングされていることを確認するために、ハード選択は実行せず、代わりに重み付き合計を通じて最終メモリを取得します:
最終的には、取得したメモリを利用してデコード プロセスを容易にし、シーケンスとパターン間の複雑な 1 対多の関係を効果的にキャプチャできます。 前の再生成プロセスとターゲット モデルによる不可知論的なため、再構成されたデータセットは特定のターゲット モデルにとって最適ではない可能性があります。したがって、モデルに依存しないデータセット再構成プロセスをモデル認識型再構成プロセスに拡張します。この目的を達成するために、データセット再生成器に基づいて、再生成されたデータセット内の各データ サンプルのスコアを評価するデータセット パーソナライザーを導入しました。研究チームはその後、暗黙的な微分を通じてデータセット パーソナライザーをさらに効率的に最適化しました。 研究チームの目標は、実装された Dataset Personalizer に基づいてパラメータをトレーニングすることですMLP によって、ターゲット モデルの各データ サンプル W のスコアを評価します。フレームワークの汎用性を確保するために、研究チームは計算されたスコアを使用してトレーニング損失の重みを調整しました。これにより、ターゲット モデルに追加の変更を加える必要がなくなりました。元の次のアイテムの予測損失を定義することから始めます: その後、パーソナライズされたデータセットのトレーニング損失関数は次のように定義できます:
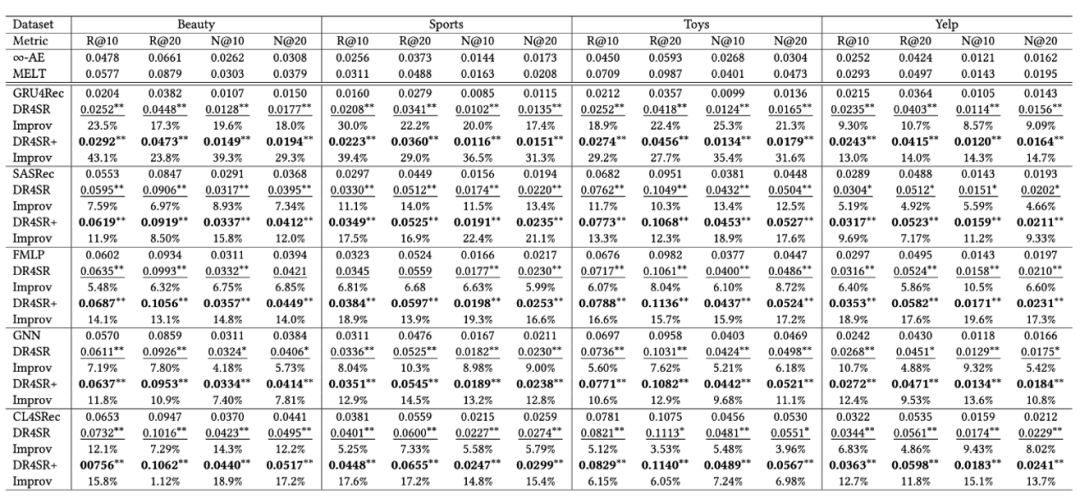
研究チームは、提案されたフレームワークの有効性を検証するために、各ターゲットモデルのパフォーマンスを「DR4SR」および「DR4SR+」バリアントと比較しました。図 4
図 4 の全体像のパフォーマンスから、次の結論が得られます。DR4SR は有益で一般的に適用可能なデータセットを再構築できます
異なるターゲット モデルは異なるデータ セットを優先します以上がKDD2024 最優秀学生論文、中国科学技術大学、Huawei Noah: シーケンス推奨の新しいパラダイム DR4SR の解釈の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




 を抽出する段階と、
を抽出する段階と、 に基づいてユーザーの好み
に基づいてユーザーの好み を学習する段階の2段階に分けました。
を学習する段階の2段階に分けました。  からのマッピングの学習には 2 つの暗黙的なマッピング
からのマッピングの学習には 2 つの暗黙的なマッピング  が含まれるため、このプロセスは困難です。この目的を達成するために、研究チームは、
が含まれるため、このプロセスは困難です。この目的を達成するために、研究チームは、 の学習が比較的容易になります。したがって、彼らの主な焦点は、1 対多のマッピングである
の学習が比較的容易になります。したがって、彼らの主な焦点は、1 対多のマッピングである  の効率的なマッピング関数を学習することです。研究チームは、図 1 に示すように、この学習プロセスをデータセット再生成パラダイムと定義しています。「再生成」とは、追加情報を導入せず、元のデータセットのみに依存することを意味します。
の効率的なマッピング関数を学習することです。研究チームは、図 1 に示すように、この学習プロセスをデータセット再生成パラダイムと定義しています。「再生成」とは、追加情報を導入せず、元のデータセットのみに依存することを意味します。 

 として示し、多様性を促進する再生器:
として示し、多様性を促進する再生器: 

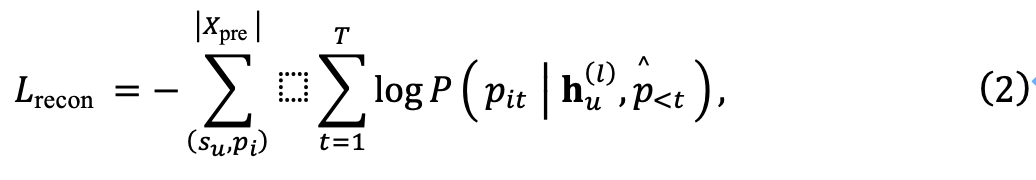



 ここで、
ここで、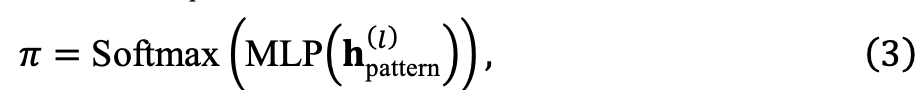
 に基づいてパラメータをトレーニングすることですMLP によって、ターゲット モデルの各データ サンプル
に基づいてパラメータをトレーニングすることですMLP によって、ターゲット モデルの各データ サンプル  W のスコアを評価します。フレームワークの汎用性を確保するために、研究チームは計算されたスコアを使用してトレーニング損失の重みを調整しました。これにより、ターゲット モデルに追加の変更を加える必要がなくなりました。元の次のアイテムの予測損失を定義することから始めます:
W のスコアを評価します。フレームワークの汎用性を確保するために、研究チームは計算されたスコアを使用してトレーニング損失の重みを調整しました。これにより、ターゲット モデルに追加の変更を加える必要がなくなりました。元の次のアイテムの予測損失を定義することから始めます: