
ホームページ >Java >&#&チュートリアル >指定されたスタックから重複を削除する Java プログラム
指定されたスタックから重複を削除する Java プログラム

- WBOYオリジナル
- 2024-08-28 12:01:04593ブラウズ
この記事では、Java のスタックから重複要素を削除する 2 つの方法を検討します。 ネストされたループを使用した単純なアプローチと、HashSet を使用したより効率的な方法を比較します。目標は、重複の削除を最適化する方法を実証し、各アプローチのパフォーマンスを評価することです。
問題ステートメント
重複した要素をスタックから削除する Java プログラムを作成します。
入力
リーリー出力
リーリー特定のスタックから重複を削除するには、2 つのアプローチがあります -
- 単純なアプローチ: 2 つの ネストされたループ を作成して、どの要素が既に存在するかを確認し、結果スタックの戻り値に要素が追加されるのを防ぎます。
- HashSet アプローチ: Set を使用して一意の要素を保存し、その O(1) 複雑さを利用して要素が存在するかどうかを確認します。
ランダムスタックの生成と複製
以下は、Java プログラムが最初にランダムなスタックを構築し、その後使用するためにその複製を作成します -
initData は、指定されたサイズと 1 ~ 100 の範囲のランダムな要素を持つスタックを作成するのに役立ちます。
manualCloneStack は、別のスタックからデータをコピーしてデータを生成し、それを 2 つのアイデア間のパフォーマンス比較に使用します。
素朴なアプローチを使用して、指定されたスタックから重複を削除します
以下は、素朴なアプローチを使用して特定のスタックから重複を削除する手順です -
- タイマーを開始します。
- 一意の要素を保存するために空のスタックを作成します。
- while ループを使用して繰り返し、元のスタックが空になるまで続行し、最上位の要素をポップします。
- resultStack.contains(element) を使用して重複をチェックし、要素がすでに結果スタックにあるかどうかを確認します。
- 要素が結果スタックにない場合は、resultStack に追加します。
- 終了時間を記録し、かかった合計時間を計算します。
- 結果を返します
例
以下は、素朴なアプローチを使用して特定のスタックから重複を削除する Java プログラムです -
リーリー素朴なアプローチの場合、
を使用しますStack<Integer> data = initData(10L);はスタック内のすべての要素を通過する最初のループを処理し、2 番目のループは
<pre class="brush:php;toolbar:false">Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5]
Time spent for Naive Approach: 18200 nanoseconds
Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5]
Time spent for Optimized Approach: 34800 nanoseconds</pre>
で要素がすでに存在するかどうかを確認します。最適化されたアプローチ (HashSet) を使用して、指定されたスタックから重複を削除します
以下は、最適化されたアプローチを使用して特定のスタックから重複を削除する手順です -
- タイマーを開始します
- 表示された要素を追跡するためのセットを作成します (O(1) 複雑さチェック用)。
- 固有の要素を保存するための一時スタックを作成します。
- while ループを使用して反復します スタックが空になるまで継続します。 スタックから一番上の要素を削除します。
- 重複をチェックするには、
- seen.contains(element) を使用して、要素がすでにセット内にあるかどうかを確認します。 要素がセットにない場合は、表示されたスタックと一時スタックの両方に追加します。
- 終了時間を記録し、かかった合計時間を計算します。
- 結果を返します
以下は、HashSet を使用して指定されたスタックから重複を削除する Java プログラムです -
リーリー
最適化されたアプローチには、を使用します 一意の要素を Set に格納するには、ランダムな要素にアクセスするときに
O(1) の複雑さ を利用して、要素が存在するかどうかを確認する計算コストを削減します。両方のアプローチを併用する
以下は、上記の両方のアプローチを使用して、特定のスタックから重複を削除する手順です-
- initData(Long size) メソッド を使用してデータを初期化し、ランダムな整数で満たされたスタックを作成します。
- cloneStack(Stack stack) メソッド を使用してスタックのクローンを作成し、元のスタックの正確なコピーを作成します。
- initData を使用して初期スタックを生成します。
- cloneStack を使用してこのスタックのクローンを作成します。
- 単純なアプローチを適用して、元のスタックから重複を削除します。
- 最適化されたアプローチを適用して、複製されたスタックから重複を削除します。 各方法にかかる時間と、両方のアプローチによって生成される固有の要素を表示します
例
以下は、上記の両方のアプローチを使用してスタックから重複要素を削除する Java プログラムです -
リーリー
出力
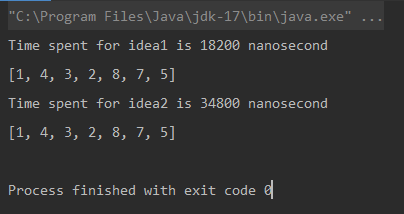
* 測定単位はナノ秒です。
public static void main(String[] args) {
Stack<Integer> data1 = initData(<number of stack size want to test>);
Stack<Integer> data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| Method | 100 elements | 1000 elements |
10000 elements |
100000 elements |
1000000 elements |
| Idea 1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| Idea 2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
As observed, the time running for Idea 2 is shorter than for Idea 1 because the complexity of Idea 1 is O(n²), while the complexity of Idea 2 is O(n). So, when the number of stacks increases, the time spent on calculations also increases based on it.
以上が指定されたスタックから重複を削除する Java プログラムの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。