
ホームページ >バックエンド開発 >Python チュートリアル >ML でのラベル エンコーディング
ML でのラベル エンコーディング

- 王林オリジナル
- 2024-08-23 06:01:081405ブラウズ
ラベル エンコーディング は、機械学習で最もよく使用される手法の 1 つです。カテゴリデータを数値形式に変換するために使用されます。したがって、データをモデルに当てはめることができます。
ラベル エンコーディングを使用する理由を理解しましょう。 string の形式で必須の列を含むデータがあると想像してください。しかし、モデリングは数値データに対してのみ機能するため、このデータをモデルに当てはめることはできません。どうすればよいでしょうか?ここで、フィッティング用のデータを準備する前処理ステップで評価される救命テクニック、ラベル エンコーディング を紹介します。
Label Encoder の仕組みを理解するために、Scikit-Learn ライブラリの iris データセットを使用します。次のライブラリがインストールされていることを確認してください。
pandas scikit-learn
ライブラリとしてインストールするには、次のコマンドを実行します:
$ python install -U pandas scikit-learn
ここで、Google Colab ノートブックを開いて、Label Encoder のコーディングと学習に取り組みましょう。
コードを書いてみましょう
- 次のライブラリをインポートすることから始めます:
import pandas as pd from sklearn import preprocessing
- iris データセットをインポートし、使用できるように初期化します。
from sklearn.datasets import load_iris iris = load_iris()
- 次に、エンコードするデータを選択する必要があります。アヤメの種名をエンコードします。
species = iris.target_names print(species)
出力:
array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
- 前処理 からクラス LabelEncoder をインスタンス化しましょう。
label_encoder = preprocessing.LabelEncoder()
- これで、ラベル エンコーダを使用してデータを適合させる準備が整いました。
label_encoder.fit(species)
次のような出力が表示されます:
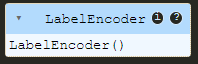
この出力が得られれば、データは正常に適合されています。しかし、問題は、各種にどのような値がどのような順序で割り当てられているかをどのようにして調べるかということです。
Label Encoder がデータに適合する順序は、classes_ 属性に保存されます。エンコードは 0 から data_length-1 まで始まります。
label_encoder.classes_
出力:
array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
ラベルエンコーダーはデータを自動的にソートし、左側からエンコードを開始します。ここ:
setosa -> 0 versicolor -> 1 virginica -> 2
- それでは、当てはめたデータをテストしてみましょう。アヤメの種 setosa を変身させます。
label_encoder.transform(['setosa'])
出力: array([0])
もう一度、正種の virginica を変換した場合です。
label_encoder.transform(['virginica'])
出力: array([2])
["setosa"、"virginica"] などの種のリストを入力することもできます
ラベル エンコーダーの Scikit Learn ドキュメント >>>
以上がML でのラベル エンコーディングの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。