
ホームページ >テクノロジー周辺機器 >AI >AI を使用してエージェントを自動的に設計すると、数学のスコアが 25.9% 向上し、手動による設計を大幅に上回りました。
AI を使用してエージェントを自動的に設計すると、数学のスコアが 25.9% 向上し、手動による設計を大幅に上回りました。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-08-22 22:37:32404ブラウズ
The performance of the discovered ADAS-based agent significantly outperforms state-of-the-art hand-designed baselines.
Fundamental models (FM) such as GPT and Claude are becoming a strong support for general-purpose agents and are increasingly used for a variety of reasoning and planning tasks.
However, when solving problems, the agents needed are usually composite agent systems with multiple components rather than monolithic model queries. Furthermore, in order for agents to solve complex real-world tasks, they often require access to external tools such as search engines, code execution, and database queries.
Therefore, many effective building blocks for agent systems have been proposed, such as thought chain planning and reasoning, memory structures, tool usage, and self-reflection. Although these agents have achieved remarkable success in a variety of applications, developing these building blocks and combining them into complex agent systems often requires domain-specific manual tuning and considerable effort from researchers and engineers.
However, the history of machine learning tells us that hand-designed solutions will eventually be replaced by solutions learned by models.
In this article, researchers from the University of British Columbia and the non-profit artificial intelligence research institution Vector Institute have formulated a new research field, namely Automated Design of Agentic Systems (ADAS), and proposed a A simple but effective ADAS algorithm called Meta Agent Search to prove that agents can invent novel and powerful agent designs through code programming.
This research aims to automatically create powerful agent system designs, including developing new building blocks and combining them in new ways.
Experiments show that the performance of agents discovered based on ADAS significantly outperforms state-of-the-art hand-designed baselines. For example, the agent designed in this article improved the F1 score by 13.6/100 (compared to the baseline) in the reading comprehension task of DROP, and improved the accuracy by 14.4% in the mathematics task of MGSM. Furthermore, after cross-domain transfer, their accuracy on GSM8K and GSM-Hard math tasks improves by 25.9% and 13.2% over the baseline, respectively.
Compared with hand-designed solutions, the algorithm in this paper performs well, which illustrates the potential of ADAS in the design of automated agent systems. Furthermore, experiments show that the discovered agents perform well not only when transferring across similar domains, but also when transferring across different domains, such as from mathematics to reading comprehension.

Paper address: https://arxiv.org/pdf/2408.08435
Project address: https://github.com/ShengranHu/ADAS
Paper homepage: https:// www.shengranhu.com/ADAS/
Paper title: Automated Design of Agentic Systems
New research field: Automated Design of Agentic Systems (ADAS)
This study proposes a new research field ——Automated Design of Agentic Systems (ADAS), and describes the three key components of the ADAS algorithm—search space, search algorithm, and evaluation function. ADAS uses search algorithms to discover agent systems across the search space.
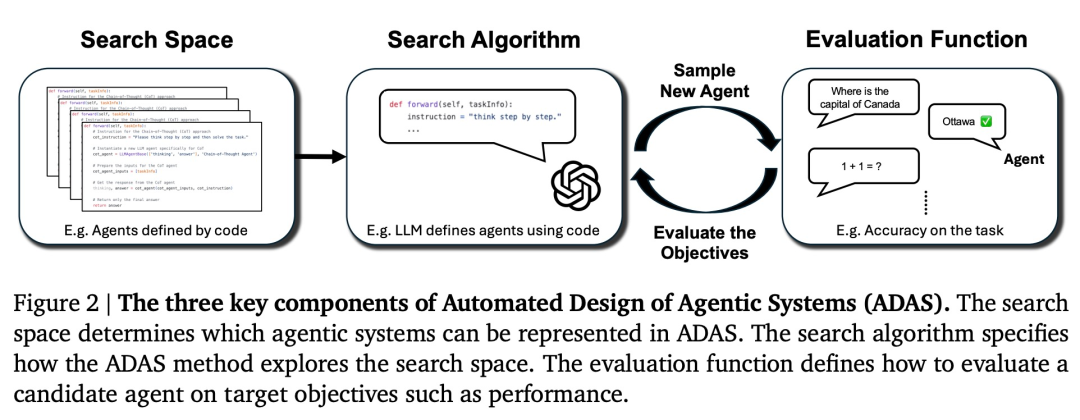
Search space: The search space defines which agent systems can be characterized and discovered in ADAS. For example, work like PromptBreeder (Fernando et al., 2024) only changes the agent's textual prompts, while other components (e.g., control flow) remain unchanged. Therefore, in the search space, it is impossible to characterize an agent with a different control flow than the predefined control flow.
Search algorithm: The search algorithm defines how the ADAS algorithm explores the search space. Since search spaces are often very large or even unbounded, the exploration versus exploitation trade-off should be considered (Sutton & Barto, 2018). Ideally, this algorithm can quickly discover high-performance agent systems while avoiding falling into local optima. Existing methods include using reinforcement learning (Zhuge et al., 2024) or FM that iteratively generates new solutions (Fernando et al., 2024) as search algorithms.
Evaluation function: Depending on the application of the ADAS algorithm, different optimization goals may need to be considered, such as the agent's performance, cost, latency, or safety. The evaluation function defines how to evaluate these metrics for a candidate agent. For example, to evaluate an agent's performance on unseen data, a simple approach is to calculate accuracy on task validation data.
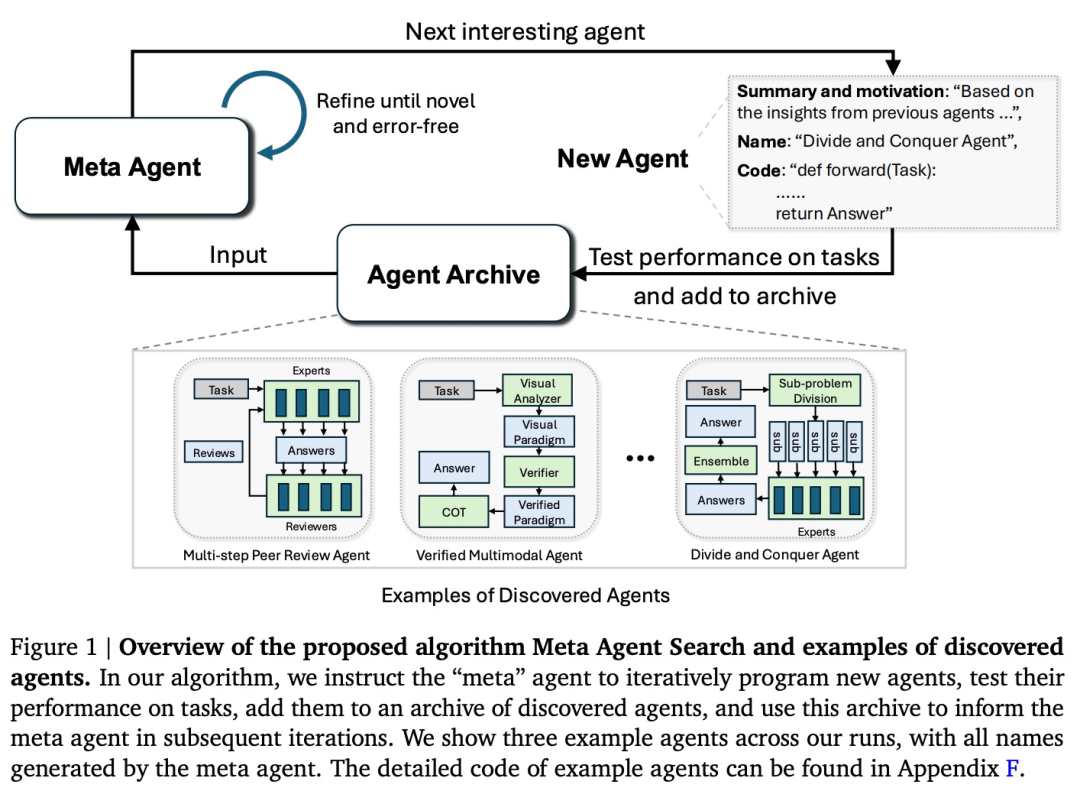
この研究で提案されているシンプルだが効果的な ADAS アルゴリズムの中心概念 - メタエージェント検索は、興味深い新しいエージェントを繰り返し作成し、それらを評価し、エージェント リポジトリに追加し、これを使用するようにメタエージェントに指示することです。リポジトリは役立ちますメタエージェントは、後続の反復で新しくてより興味深いエージェントを作成します。人間の利益の概念を利用する既存のオープンエンドアルゴリズムと同様に、この研究はメタエージェントエージェントが興味深く価値のあるエージェントを探索することを奨励します。
メタエージェント検索の中心となるアイデアは、検索アルゴリズムとして FM を使用し、成長するエージェント リポジトリに基づいて興味深い新しいエージェントを反復的にプログラムすることです。この研究では、メタエージェント用の単純なフレームワーク (コード 100 行以内) を定義し、クエリ FM やフォーマットのヒントなどの基本的な機能セットをメタエージェントに提供します。
したがって、メタエージェントは、FunSearch で行われるのと同様に、新しいエージェント システムを定義する「転送」関数を記述するだけで済みます (Romera-Paredes et al., 2024)。この機能はタスク情報を受け取り、タスクに対するエージェントの応答を出力します。
図 1 に示すように、メタエージェント検索の中心となるアイデアは、メタエージェントがコード内で新しいエージェントを反復的にプログラムできるようにすることです。メタエージェント プログラム 新しいエージェント プログラムのメイン プロンプトを以下に示します。プロンプト内の変数は強調表示されています。

実験
すべての実験結果は、この論文で発見されたエージェントがベースラインの最先端の手作業で設計されたエージェントよりも大幅に優れていることを示しています。注目すべきことに、この研究で見つかったエージェントは、DROP 読解タスクではベースラインより 13.6/100 (F1 スコア)、MGSM 数学タスクでは 14.4% (精度) 向上しました。さらに、研究者が発見したエージェントは、GPT-3.5 から GPT-4 への移行後、および MGSM 数学タスクから GSM8K および GSM-Hard へ移行した場合、ARC タスクのパフォーマンスがベースラインと比較して 14% (精度) 向上しました。 . 数学タスクを保留した後、精度はそれぞれ 25.9% と 13.2% 増加しました。
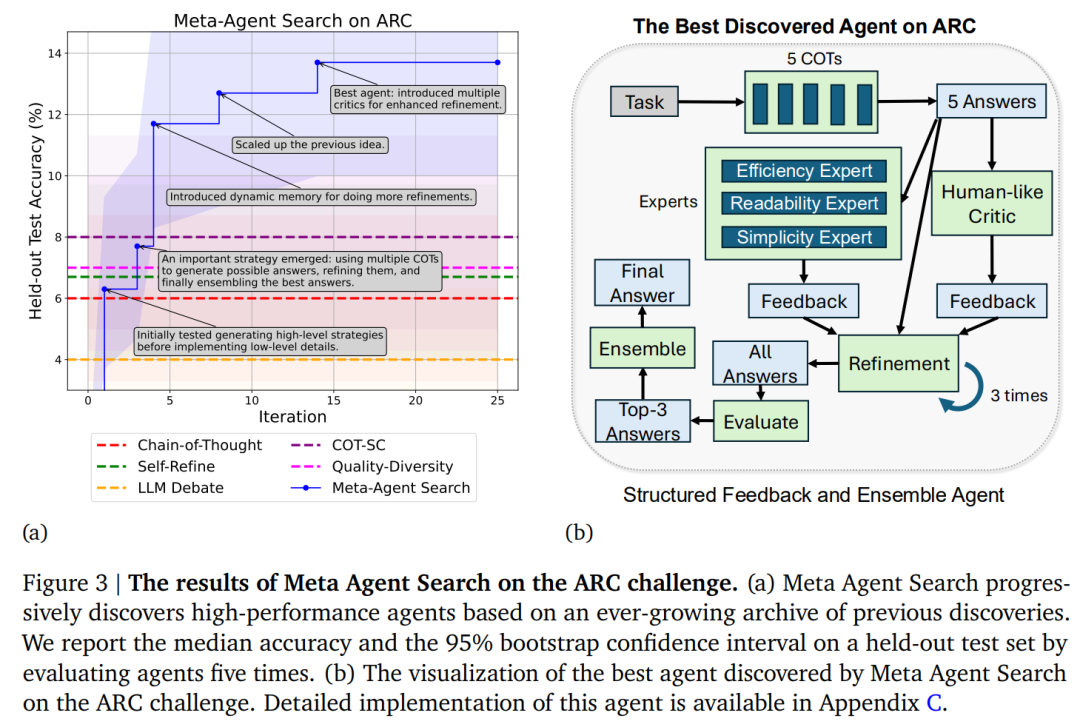
ケーススタディ: ARC チャレンジ
図 3a に示すように、メタエージェント検索により、最新の手作業で設計されたエージェントを上回るパフォーマンスを発揮するエージェントを効率的かつ段階的に発見できます。重要なブレークスルーはテキスト ボックスで強調表示されます。
さらに、図 3b は、最も効率的に答えを絞り込むために複雑なフィードバック メカニズムが採用されている、最もよく発見されたエージェントを示しています。探索の進行状況を詳しく観察すると、この複雑なフィードバック メカニズムが突然現れたわけではないことがわかります。
推論および問題解決ドメイン
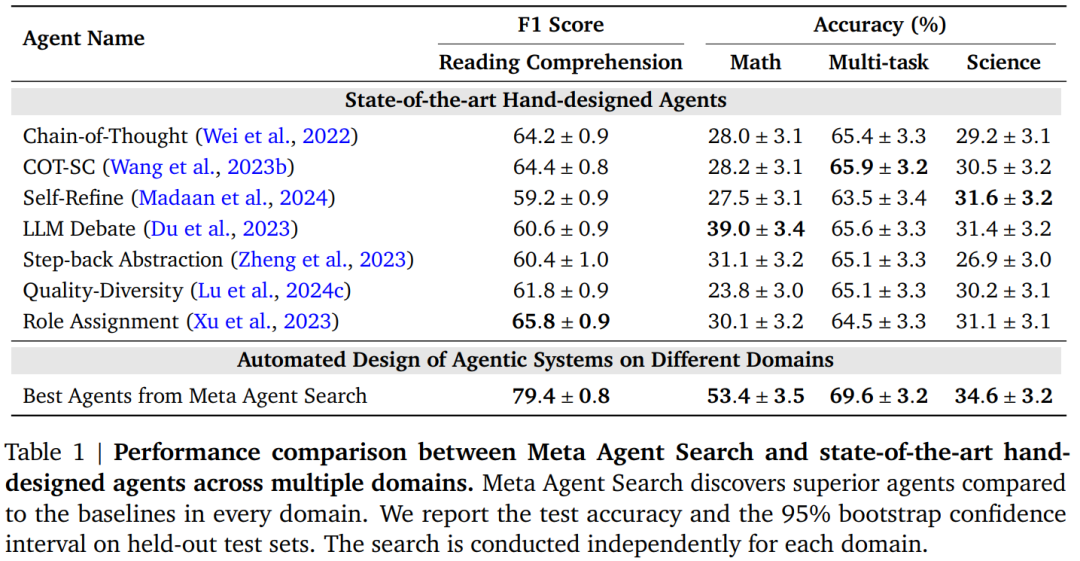
複数のドメインにわたる結果は、メタエージェント検索がSOTAの手動設計エージェントよりも優れたパフォーマンスを発揮するエージェントを発見できることを示しています(表1)。
一般化と転移可能性
研究者らは、発見されたエージェントの転移可能性と一般化可能性をさらに実証しました。
表 2 に示すように、研究者らは、検索されたエージェントが常に手動で設計されたエージェントよりも優れており、その差が大きいことを観察しました。研究者らは、Anthropic の最も強力なモデルである Claude-Sonnet が、テストされたすべてのモデルの中で最も優れたパフォーマンスを示し、このモデルに基づくエージェントが ARC 上で 50% 近くの精度を達成できることを発見したことは注目に値します。
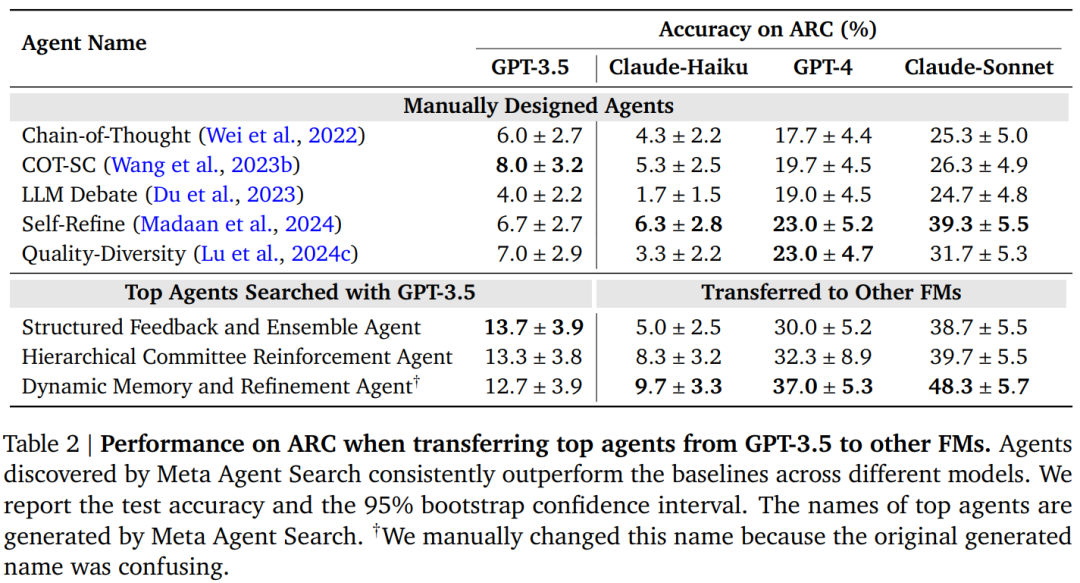
表 3 に示すように、研究者らは、メタエージェント検索のパフォーマンスがベースラインと比較して同様の利点があることを観察しました。ベースラインと比較して、GSM8K および GSM-Hard でのエージェントの精度がそれぞれ 25.9% および 13.2% 増加したことは注目に値します。
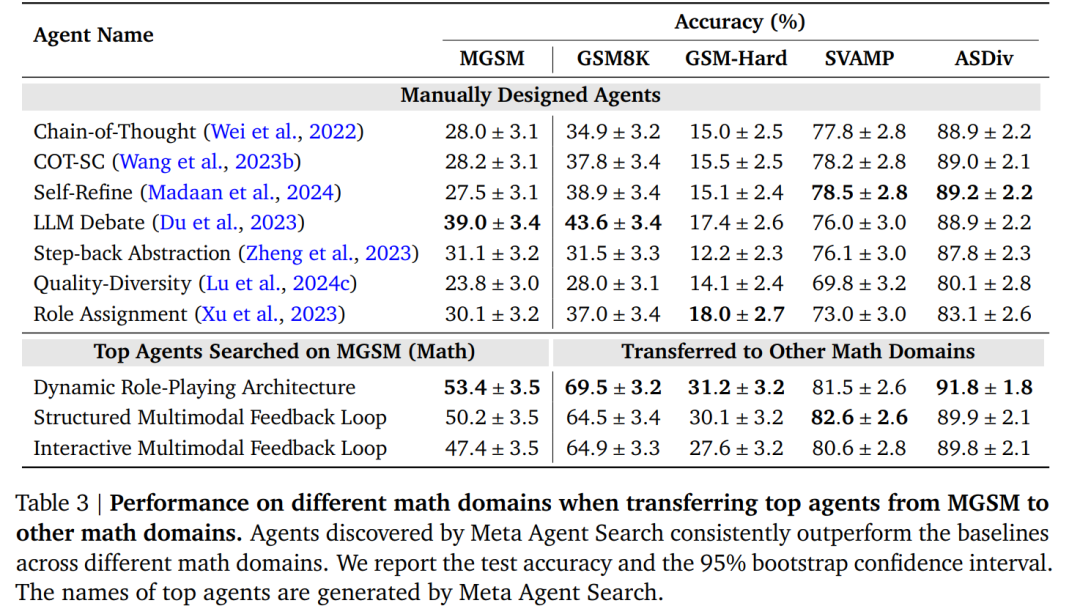
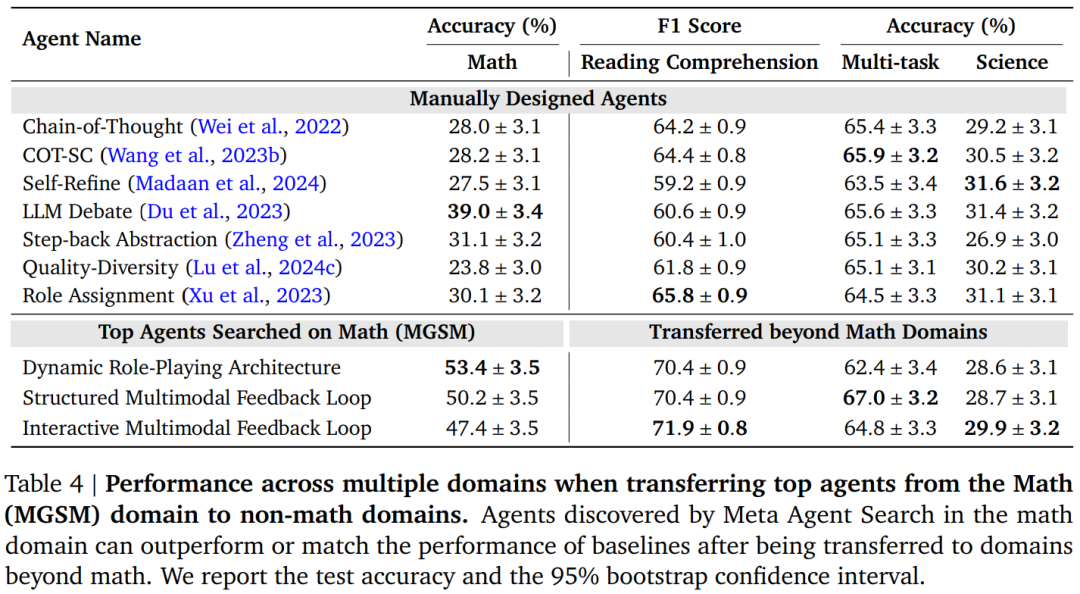
さらに驚くべきことに、研究者たちは、数学的領域で発見されたエージェントが非数学的領域に転送される可能性があることを観察しました (表 4)。
以上がAI を使用してエージェントを自動的に設計すると、数学のスコアが 25.9% 向上し、手動による設計を大幅に上回りました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。