
ホームページ >データベース >mysql チュートリアル >SQL インタビュー完全ガイド
SQL インタビュー完全ガイド

- PHPzオリジナル
- 2024-08-22 14:49:321422ブラウズ
構造化クエリ言語 (SQL) は、MySQL、Oracle、SQL Server、PostgreSQL などのリレーショナル データベースからデータを作成、維持、破棄、更新、取得するために使用される標準データベース言語です。
エンティティ関係モデル (ER)
これは、データベース内のデータの構造を記述するために使用される概念的なフレームワークです。これは、現実世界のエンティティとそれらの間の関係をより抽象的な方法で表すように設計されました。これは、プログラミング言語におけるオブジェクト指向プログラミングと似ています。
エンティティ: これらは、顧客、製品、注文など、明確な存在を持つ現実世界のオブジェクトまたは「物」です。
関係: これらは、エンティティが互いにどのように関連するかを定義します。たとえば、「顧客」エンティティは「注文」エンティティと関係を持つ可能性があります
コマンド:
データベースの作成
create database <database_name>;
リストデータベース
show databases;
データベースを使用する
use <database_name>
テーブルの表示構造
DESCRIBE table_name;
SQL のサブ言語
データクエリ言語 (DQL):
データのクエリを実行するために使用される言語。このコマンドは、データベースからデータを取得するために使用されます。
コマンド:
1) 以下を選択します:
select * from table_name; select column1,column2 from table_name; select * from table_name where column1 = "value";
データ定義言語 (DDL):
データベース スキーマの定義に使用される言語。このコマンドはデータベースの作成、変更、削除に使用されますが、データではありません。
コマンド
1) 以下を作成します:
create table table_name( column_name data_type(size) constraint, column_name data_type(size) constraint column_name data_type(size) constraint );
2) ドロップ:
このコマンドはテーブル/データベースを完全に削除します。
drop table table_name; drop database database_name;
3) 切り詰め:
このコマンドはデータのみを削除します。
truncate table table_name;
4) 変更:
このコマンドは、テーブルの列を追加、削除、または更新できます。
追加
alter table table_name add column_name datatype;
変更
alter table table_name modify column column_name datatype; --ALTER TABLE employees --MODIFY COLUMN salary DECIMAL(10,2);
ドロップ
alter table table_name drop column_name datatype;
データ操作言語 (DML):
データベースに存在するデータを操作するために使用される言語。
1) 挿入:
このコマンドは、新しい値のみを挿入するために使用されます。
insert into table_name values (val1,val2,val3,val4); //4 columns
2) 更新:
update table_name set col1=val1, col2=val2 where col3 = val3;
3) 削除:
delete from table_name where col1=val1;
データ制御言語 (DCL):
GRANT: 指定されたユーザーに指定されたタスクの実行を許可します。
REVOKE: 以前に付与または拒否されたアクセス許可を取り消します。
トランザクション制御言語 (TCL):
データベース内のトランザクションを管理するために使用されます。 DML コマンドによって行われた変更を管理します。
1) コミット
現在のトランザクション中に行われたすべての変更をデータベースに保存するために使用されます
BEGIN TRANSACTION; UPDATE employees SET salary = salary * 1.1 WHERE department = 'Sales'; COMMIT;
2) ロールバック
現在のトランザクション中に行われたすべての変更を元に戻すために使用されます
BEGIN TRANSACTION; UPDATE employees SET salary = salary * 1.1 WHERE department = 'Sales'; ROLLBACK;
3) セーブポイント
begin transaction; update customers set first_name= 'one' WHERE customer_id=4; SAVEPOINT one; update customers set first_name= 'two' WHERE customer_id=4; ROLLBACK TO SAVEPOINT one; COMMIT;
持っているもの:
このコマンドは、集計関数に基づいて結果をフィルタリングするために使用されます。" WHERE ステートメントでは集計関数を使用できないため、このコマンドで使用できます"
注: これは、作成された列を使用して比較する必要がある場合に使用できますが、WHERE コマンドは既存の列
を使用して比較するために使用できます。
select Department, sum(Salary) as Salary from employee group by department having sum(Salary) >= 50000;
で
このコマンドは、2 つ以上の特定の項目を除外するように要求する場合に使用されます
select * from table_name
where colname not in ('Germany', 'France', 'UK');
明確な:
このコマンドは、選択したフィールドに基づいて一意のデータのみを取得するために使用されます。
Select distinct field from table;
SELECT COUNT(DISTINCT salesman_id) FROM orders;
相関クエリ
これは、外部クエリの列を参照するサブクエリ (別のクエリ内にネストされたクエリ) です
SELECT EmployeeName, Salary
FROM Employees e1
WHERE Salary > (
SELECT AVG(Salary)
FROM Employees e2
WHERE e1.DepartmentID = e2.DepartmentID
);
正規化
正規化は、冗長性を減らし、データの整合性を向上させる方法でテーブルを編成するために使用されるデータベース設計手法です。正規化の主な目的は、データ間の関係を維持しながら、大きなテーブルをより小さく管理しやすい部分に分割することです
第一正規形 (1NF)
列内のすべての値はアトミック (分割不可能) です。
各列には 1 種類のデータのみが含まれます。
EmployeeID | EmployeeName | Department | PhoneNumbers ---------------------------------------------------- 1 | Alice | HR | 123456, 789012 2 | Bob | IT | 345678
1NF以降:
EmployeeID | EmployeeName | Department | PhoneNumber ---------------------------------------------------- 1 | Alice | HR | 123456 1 | Alice | HR | 789012 2 | Bob | IT | 345678
第 2 正規形 (2NF)
1NFにあります。
すべての非キー属性は、機能的に主キーに完全に依存しています (部分的な依存関係はありません)。
EmployeeID | EmployeeName | DepartmentID | DepartmentName --------------------------------------------------------- 1 | Alice | 1 | HR 2 | Bob | 2 | IT
2NF以降:
EmployeeID | EmployeeName | DepartmentID --------------------------------------- 1 | Alice | 1 2 | Bob | 2 DepartmentID | DepartmentName ------------------------------ 1 | HR 2 | IT
第 3 正規形 (3NF)
2NFにあります。
すべての属性は機能的に主キーにのみ依存します (推移的な依存関係はありません)。
EmployeeID | EmployeeN | DepartmentID | Department | DepartmentLocation -------------------------------------------------------------------------- 1 | Alice | 1 | HR | New York 2 | Bob | 2 | IT | Los Angeles
3NF以降:
EmployeeID | EmployeeN | DepartmentID ---------------------------------------- 1 | Alice | 1 2 | Bob | 2 DepartmentID | DepartmentName | DepartmentLocation ----------------------------------------------- 1 | HR | New York 2 | IT | Los Angeles
連合:
このコマンドは、2 つ以上の SELECT ステートメントの結果を結合するために使用されます
Select * from table_name WHERE (subject = 'Physics' AND year = 1970) UNION (SELECT * FROM nobel_win WHERE (subject = 'Economics' AND year = 1971));
制限:
このコマンドは、クエリから取得されるデータの量を制限するために使用されます。
select Department, sum(Salary) as Salary from employee limit 2;
オフセット:
このコマンドは、結果を返す前に行数をスキップするために使用されます。
select Department, sum(Salary) as Salary from employee limit 2 offset 2;
Order By:
This command is used to sort the data based on the field in ascending or descending order.
Data:
create table employees (
id int primary key,
first_name varchar(50),
last_name varchar(50),
salary decimal(10, 2),
department varchar(50)
);
insert into employees (first_name, last_name, salary, department)
values
('John', 'Doe', 50000.00, 'Sales'),
('Jane', 'Smith', 60000.00, 'Marketing'),
('Jim', 'Brown', 60000.00, 'Sales'),
('Alice', 'Johnson', 70000.00, 'Marketing');
select * from employees order by department; select * from employees order by salary desc
Null
This command is used to test for empty values
select * from tablename where colname IS NULL;
Group By
This command is used to arrange similar data into groups using a function.
select department, avg(salary) AS avg_salary from employees group by department;
Like:
This command is used to search a particular pattern in a column.

SELECT * FROM employees WHERE first_name LIKE 'a%';
SELECT * FROM salesman WHERE name BETWEEN 'A' AND 'L';
Wildcard:
Characters used with the LIKE operator to perform pattern matching in string searches.
% - Percent
_ - Underscore
How to print Wildcard characters?
SELECT 'It\'s a beautiful day';
SELECT * FROM table_name WHERE column_name LIKE '%50!%%' ESCAPE '!';
Case
The CASE statement in SQL is used to add conditional logic to queries. It allows you to return different values based on different conditions.
SELECT first_name, last_name, salary,
CASE salary
WHEN 50000 THEN 'Low'
WHEN 60000 THEN 'Medium'
WHEN 70000 THEN 'High'
ELSE 'Unknown'
END AS salary_category
FROM employees;
Display Text
1) Print something
Select "message";
select ' For', ord_date, ',there are', COUNT(ord_no) group by colname;
2) Print numbers in each column
Select 1,2,3;
3) Print some calculation
Select 6x2-1;
4) Print wildcard characters
select colname1,'%',colname2 from tablename;
5) Connect two colnames
select first_name || ' ' || last_name AS colname from employees
6) Use the nth field
select * from orders group by colname order by 2 desc;
Constraints
1) Not Null:
This constraint is used to tell the field that it cannot have null value in a column.
create table employees(
id int(6) not null
);
2) Unique:
This constraint is used to tell the field that it cannot have duplicate value. It can accept NULL values and multiple unique constraints are allowed per table.
create table employees (
id int primary key,
first_name varchar(50) unique
);
3) Primary Key:
This constraint is used to tell the field that uniquely identifies in the table. It cannot accept NULL values and it can have only one primary key per table.
create table employees (
id int primary key
);
4) Foreign Key:
This constraint is used to refer the unique row of another table.
create table employees (
id int primary key
foreign key (id) references owner(id)
);
5) Check:
This constraint is used to check a particular condition for data to be stored.
create table employees (
id int primary key,
age int check (age >= 18)
);
6) Default:
This constraint is used to provide default value for a field.
create table employees (
id int primary key,
age int default 28
);
Aggregate functions
1)Count:
select count(*) as members from employees;
2)Sum:
select sum(salary) as total_amount FROM employees;
3)Average:
select avg(salary) as average_amount FROM employees;
4)Maximum:
select max(salary) as highest_amount FROM employees;
5)Minimum:
select min(salary) as lowest_amount FROM employees;
6)Round:
select round(123.4567, -2) as rounded_value;
Date Functions
1) datediff
select a.id from weather a join weather b on datediff(a.recordDate,b.recordDate)=1 where a.temperature > b.temperature;
2) date_add
select date_add("2017-06-15", interval 10 day);
SECOND
MINUTE
HOUR
DAY
WEEK
MONTH
QUARTER
YEAR
3) date_sub
SELECT DATE_SUB("2017-06-15", INTERVAL 10 DAY);
Joins
Inner Join
This is used to combine two tables based on one common column.
It returns only the rows where there is a match between both tables.
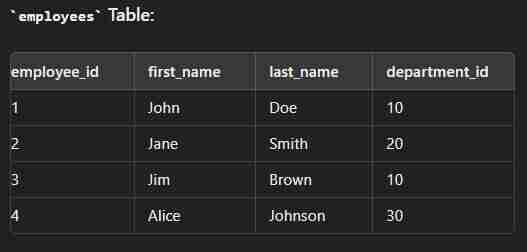
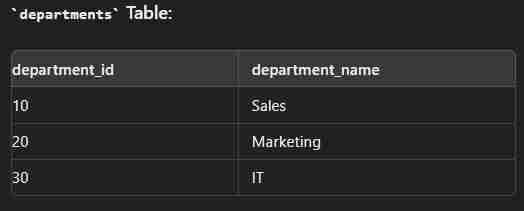
Data
create table employees( employee_id int(2) primary key, first_name varchar(30), last_name varchar(30), department_id int(2) ); create table department( department_id int(2) primary key, department_name varchar(30) ); insert into employees values (1,"John","Dow",10); insert into employees values (2,"Jane","Smith",20); insert into employees values (3,"Jim","Brown",10); insert into employees values (4,"Alice","Johnson",30); insert into department values (10,"Sales"); insert into department values (20,"Marketing"); insert into department values (30,"IT");
select e.employee_id,e.first_name,e.last_name,d.department_name from employees e inner join department d on e.department_id=d.department_id;
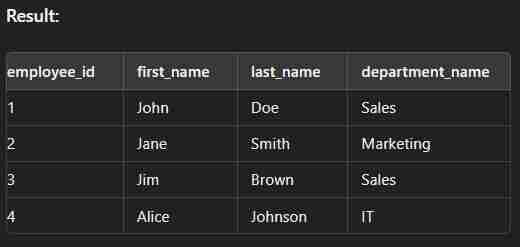
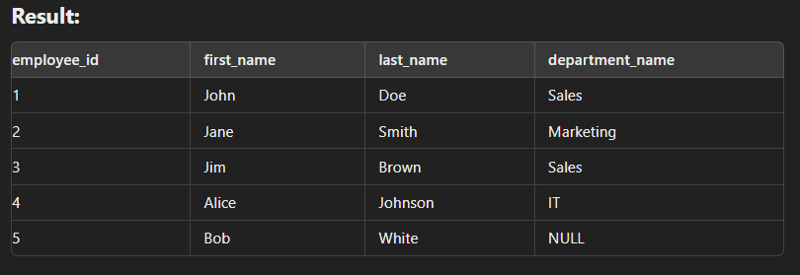
Left Join
This type of join returns all rows from the left table along with the matching rows from the right table. Note: If there are no matching rows in the right side, it return null.
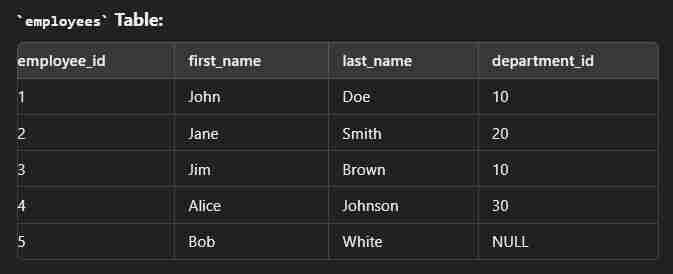
select e.employee_id, e.first_name, e.last_name, d.department_name from employees e left join departments d on e.department_id = d.department_id;
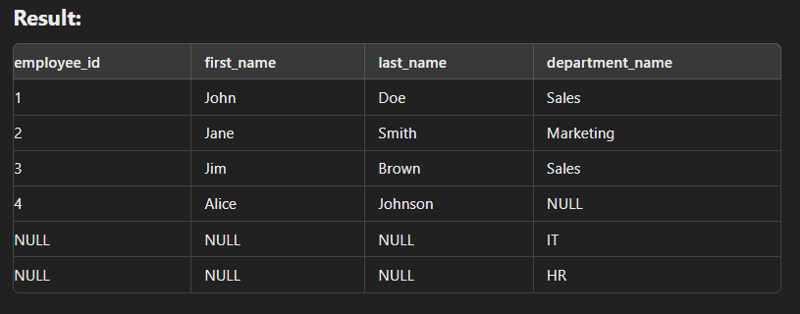
Right Join
This type of join returns all rows from the right table along with the matching rows from the left table. Note: If there are no matching rows in the left side, it returns null.
SELECT e.employee_id, e.first_name, e.last_name, d.department_name FROM employees e RIGHT JOIN departments d ON e.department_id = d.department_id;
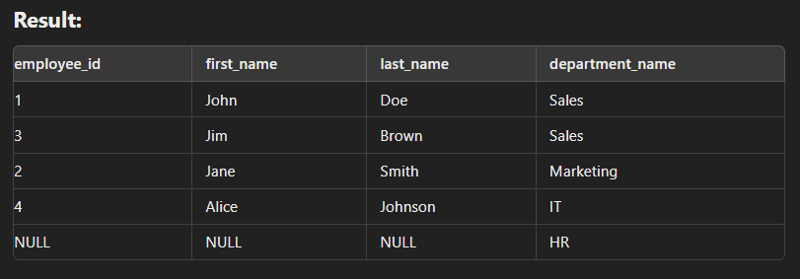
Self Join
This type of join is used to combine with itself especially for creation of new column of same data.
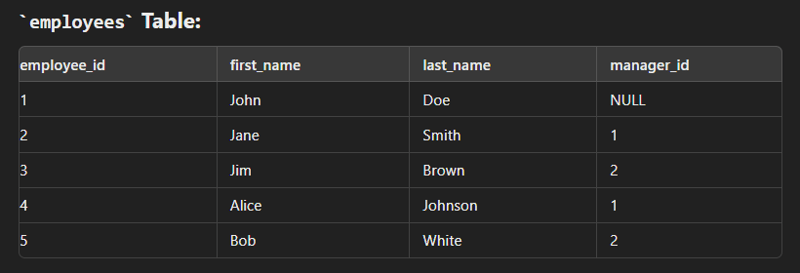
SELECT e.employee_id AS employee_id,
e.first_name AS employee_first_name,
e.last_name AS employee_last_name,
m.first_name AS manager_first_name,
m.last_name AS manager_last_name
FROM employees e
LEFT JOIN employees m ON e.manager_id = m.employee_id;
Full Join/ Full outer join
This type of join is used to combine the result of both left and right join.
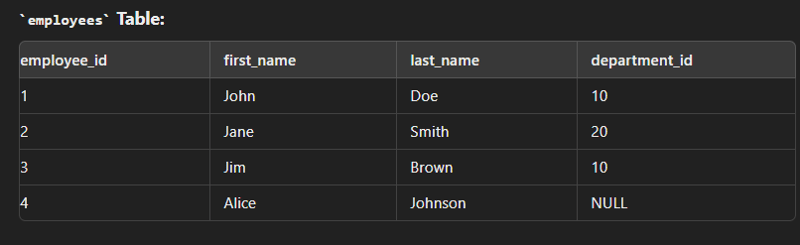
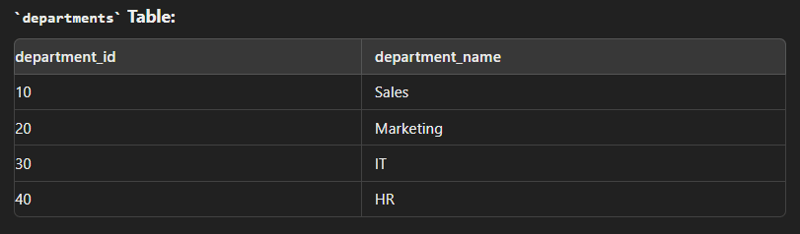
SELECT e.employee_id, e.first_name, e.last_name, d.department_name FROM employees e FULL JOIN departments d ON e.department_id = d.department_id;
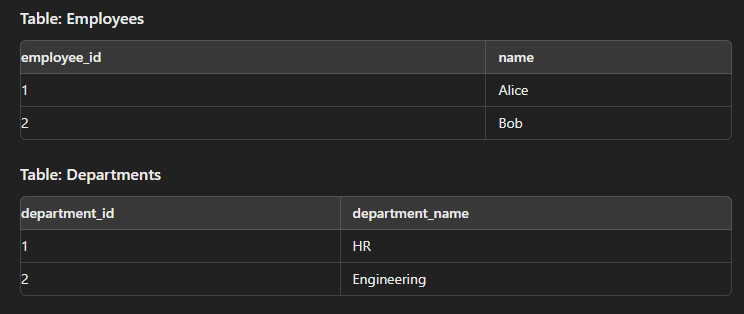
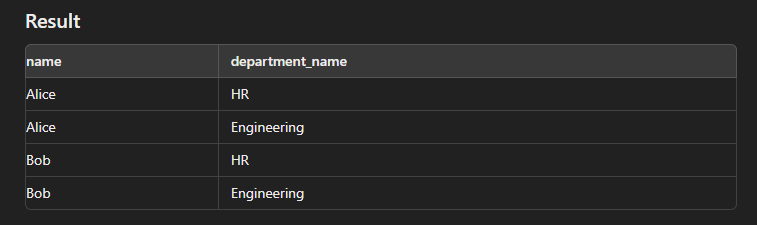
Cross Join
This type of join is used to generate a Cartesian product of two tables.
SELECT e.name, d.department_name FROM Employees e CROSS JOIN Departments d;
Nested Query
A nested query, also known as a subquery, is a query within another SQL query. The nested query is executed first, and its result is used by the outer query.
Subqueries can be used in various parts of a SQL statement, including the SELECT clause, FROM clause, WHERE clause, and HAVING clause.
1) Nested Query in SELECT Clause:
SELECT e.first_name, e.last_name,
(SELECT d.department_name
FROM departments d
WHERE d.id = e.department_id) AS department_name
FROM employees e;
2) Nested Query in WHERE Clause:
SELECT first_name, last_name, salary FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
SELECT pro_name, pro_price FROM item_mast WHERE pro_price = (SELECT MIN(pro_price) FROM item_mast);
3) Nested Query in FROM Clause:
SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id;
4) Nested Query with EXISTS:
SELECT customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
Exists
This command is used to test the existence of a particular record. Note: When using EXISTS query, actual data returned by subquery does not matter.
SELECT customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
SELECT customer_name
FROM customers c
WHERE NOT EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
COALESCE
The COALESCE function in SQL is used to return the first non-null expression among its arguments. It is particularly useful for handling NULL values and providing default values when dealing with potentially missing or undefined data.
CREATE TABLE employees (
first_name VARCHAR(50),
middle_name VARCHAR(50),
last_name VARCHAR(50)
);
INSERT INTO employees (first_name, middle_name, last_name) VALUES
('John', NULL, 'Doe'),
('Jane', 'Marie', 'Smith'),
('Emily', NULL, 'Johnson');
SELECT
first_name,
COALESCE(middle_name, 'No Middle Name') AS middle_name,
last_name
FROM
employees;
PL/SQL(Procedural Language/Structured Query Language)
It is Oracle's procedural extension to SQL. If multiple SELECT statements are issued, the network traffic increases significantly very fast. For example, four SELECT statements cause eight network trips. If these statements are part of the PL/SQL block, they are sent to the server as a single unit.
Blocks
They are the fundamental units of execution and organization.
1) Named block
Named blocks are used when creating subroutines. These subroutines are procedures, functions, and packages. The subroutines can be stored in the database and referenced by their names later on.
Ex.
CREATE OR REPLACE PROCEDURE procedure_name (param1 IN datatype, param2 OUT datatype) AS BEGIN -- Executable statements END procedure_name;
2) Anonymous
They are blocks do not have names. As a result, they cannot be stored in the database and referenced later.
DECLARE -- Declarations (optional) BEGIN -- Executable statements EXCEPTION -- Exception handling (optional) END;
Declaration
It contains identifiers such as variables, constants, cursors etc
Ex.
declare v_first_name varchar2(35) ; v_last_name varchar2(35) ; v_counter number := 0 ; v_lname students.lname%TYPE; // takes field datatype from column
Rowtype
DECLARE v_student students%rowtype; BEGIN select * into v_student from students where sid='123456'; DBMS_OUTPUT.PUT_LINE(v_student.lname); DBMS_OUTPUT.PUT_LINE(v_student.major); DBMS_OUTPUT.PUT_LINE(v_student.gpa); END;
Execution
It contains executable statements that allow you to manipulate the variables.
declare v_regno number; v_variable number:=0; begin select regno into v_regno from student where regno=1; dbms_output.put_line(v_regno || ' '|| v_variable); end
Input of text
DECLARE v_inv_value number(8,2); v_price number(8,2); v_quantity number(8,0) := 400; BEGIN v_price := :p_price; v_inv_value := v_price * v_quantity; dbms_output.put_line(v_inv_value); END;
If-else loop
IF rating > 7 THEN
v_message := 'You are great';
ELSIF rating >= 5 THEN
v_message := 'Not bad';
ELSE
v_message := 'Pretty bad';
END IF;
Loops
Simple Loop
declare
begin
for i in 1..5 loop
dbms_output.put_line('Value of i: ' || i);
end loop;
end;
While Loop
declare
counter number := 1;
begin
while counter <= 5 LOOP
dbms_output.put_line('Value of counter: ' || counter);
counter := counter + 1;
end loop;
end;
Loop with Exit
declare
counter number := 1;
begin
loop
exit when counter > 5;
dbms_output.put_line('Value of counter: ' || counter);
counter := counter + 1;
end loop;
end;
Procedure
A series of statements accepting and/or returning
zero variables.
--creating a procedure create or replace procedure proc (var in number) as begin dbms_output.put_line(var); end --calling of procedure begin proc(3); end
Function
A series of statements accepting zero or more variables that returns one value.
create or replace function func(var in number) return number is res number; begin select regno into res from student where regno=var; return res; end --function calling declare var number; begin var :=func(1); dbms_output.put_line(var); end
All types of I/O
p_name IN VARCHAR2 p_lname OUT VARCHAR2 p_salary IN OUT NUMBER
Triggers
DML (Data Manipulation Language) triggers are fired in response to INSERT, UPDATE, or DELETE operations on a table or view.
BEFORE Triggers:
Execute before the DML operation is performed.
AFTER Triggers:
Execute after the DML operation is performed.
INSTEAD OF Triggers:
Execute in place of the DML operation, typically used for views.
Note: :new represents the cid of the new row in the orders table that was just inserted.
create or replace trigger t_name after update on student for each row begin dbms_output.put_line(:NEW.regno); end --after updation update student set name='name' where regno=1;
Window function
SELECT
id,name,gender,
ROW_NUMBER() OVER(
PARTITION BY name
order by gender
) AS row_number
FROM student;
SELECT
employee_id,
department_id,
salary,
RANK() OVER(
PARTITION BY department_id
ORDER BY salary DESC
) AS salary_rank
FROM employees;
ACID Properties:
Atomicity:
All operations within a transaction are treated as a single unit.
Ex. Consider a bank transfer where money is being transferred from one account to another. Atomicity ensures that if the debit from one account succeeds, the credit to the other account will also succeed. If either operation fails, the entire transaction is rolled back to maintain consistency.
一貫性:
一貫性により、トランザクションの前後でデータベースが一貫した状態に保たれることが保証されます。
例 送金取引により 1 つの口座の残高が減少した場合、受取口座の残高も増加するはずです。これにより、システム全体のバランスが維持されます。
隔離:
分離により、トランザクションの同時実行により、トランザクションが連続的に (つまり、次々に) 実行された場合に得られるシステム状態が得られることが保証されます。
元。 2 つのトランザクション T1 と T2 を考えてみましょう。 T1 がアカウント A からアカウント B に送金し、T2 がアカウント A の残高をチェックする場合、分離により、T2 は送金前 (T1 がまだコミットしていない場合) または送金後 (T1 の場合) にアカウント A の残高を確認できるようになります。コミットしました)、しかし中間状態ではありません。
耐久性:
耐久性により、トランザクションがコミットされると、その効果は永続的に持続し、システム障害が発生しても存続することが保証されます。システムがクラッシュまたは再起動しても、トランザクションによって加えられた変更は失われません。
データ型
1) 数値データ型
int
10 進数(p,q) - p はサイズ、q は精度
2) 文字列データ型
char(value) - max(8000) && 不変
varchar(value) - max(8000)
テキスト - 最大サイズ
3) 日付データ型
日付
時間
日時
以上がSQL インタビュー完全ガイドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。