現在、ロング コンテキスト ビジュアル言語モデル (VLM) には、システム、モデル トレーニング、データ セット開発を統合する新しいフルスタック ソリューション LongVILA が搭載されています。
この段階では、モデルのマルチモーダルな理解と、より多くのモダリティをサポートする基本モデルがより柔軟な入力信号を受け入れて、人々が多様化できるようにすることが非常に重要です。モデルと対話する方法。また、コンテキストが長くなると、モデルは長いドキュメントや長いビデオなど、より多くの情報を処理できるようになり、より現実世界のアプリケーションに必要な機能も提供されます。 ただし、現在の問題は、一部の作業でロングコンテキスト視覚言語モデル (VLM) が有効になっていますが、通常は包括的なソリューションを提供するのではなく、単純化されたアプローチであることです。 フルスタック設計は、ロングコンテキストの視覚言語モデルにとって非常に重要です。大規模モデルのトレーニングは通常、データ エンジニアリングとシステム ソフトウェアの共同設計を必要とする複雑で体系的なタスクです。テキストのみの LLM とは異なり、VLM (LLaVA など) は多くの場合、独自のモデル アーキテクチャと柔軟な分散トレーニング戦略を必要とします。 さらに、ロング コンテキスト モデリングには、ロング コンテキスト データだけでなく、メモリを大量に消費するロング コンテキスト トレーニングをサポートできるインフラストラクチャも必要です。したがって、ロングコンテキスト VLM には、綿密に計画されたフルスタック設計 (システム、データ、パイプラインをカバーする) が不可欠です。 この記事では、NVIDIA、MIT、カリフォルニア大学バークレー校、テキサス大学オースティン校の研究者が、システム設計、モデルトレーニングを含むロングコンテキストの視覚言語モデルのトレーニングと展開のためのフルスタック ソリューションである LongVILA を紹介します。戦略とデータセットの構築。
- ペーパーアドレス: https://arxiv.org/pdf/2408.10188
- コードアドレス: https://github.com/NVlabs/VILA/blob/main/LongVILA.md
- 論文のタイトル: LONGVILA: SCALING LONG-CONTEXT VISUAL LANGUAGE MODELS FOR LONG VIDEOS
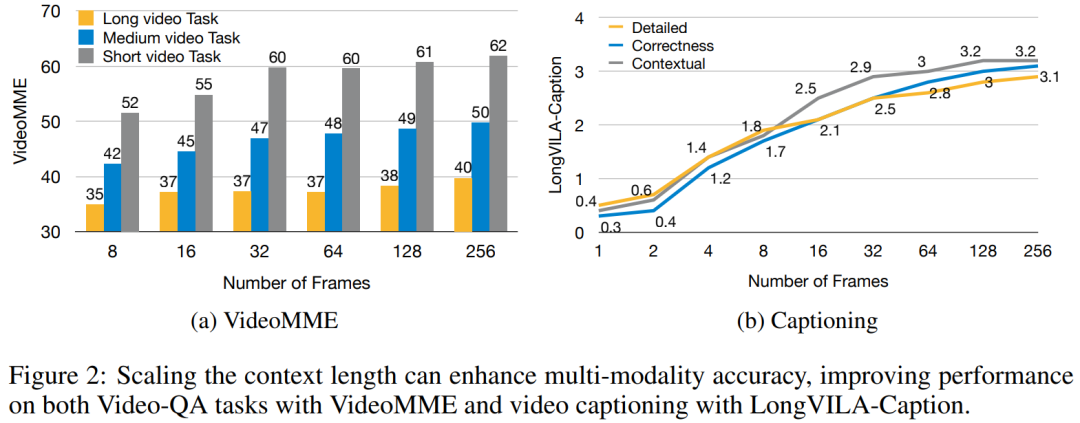
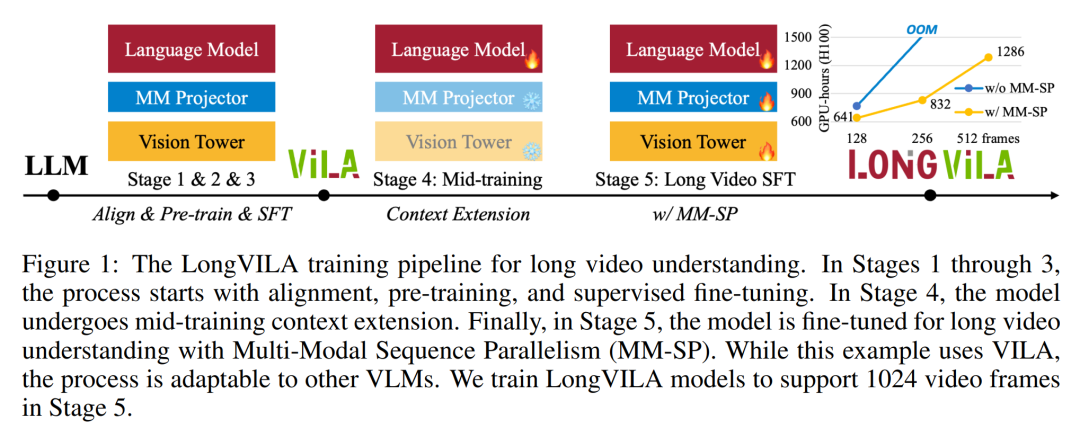
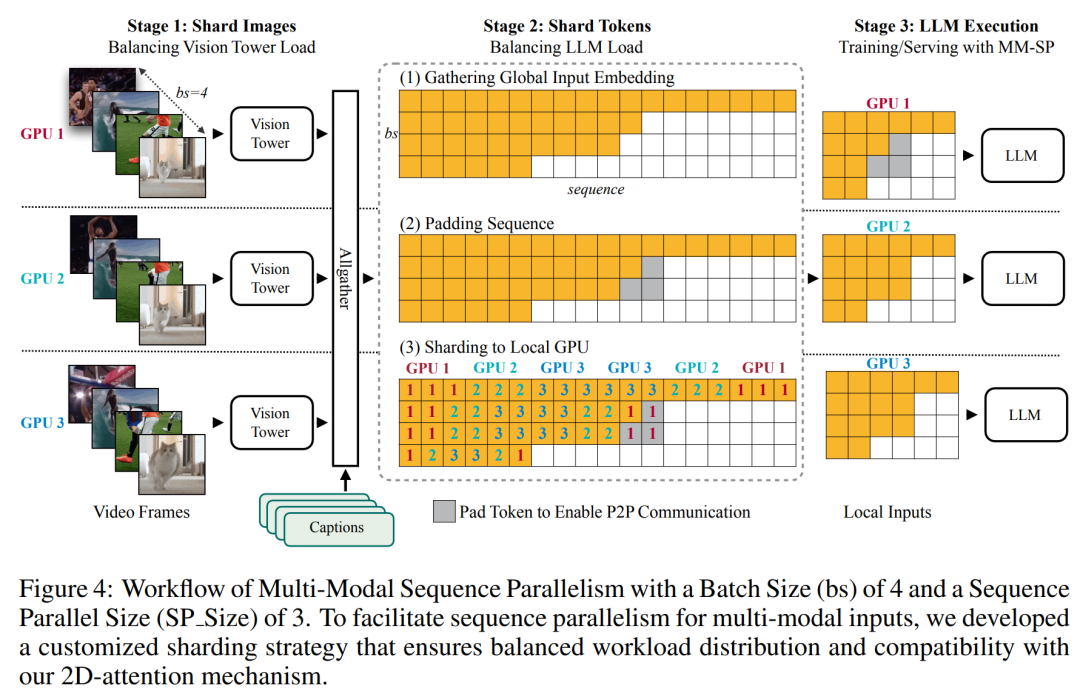
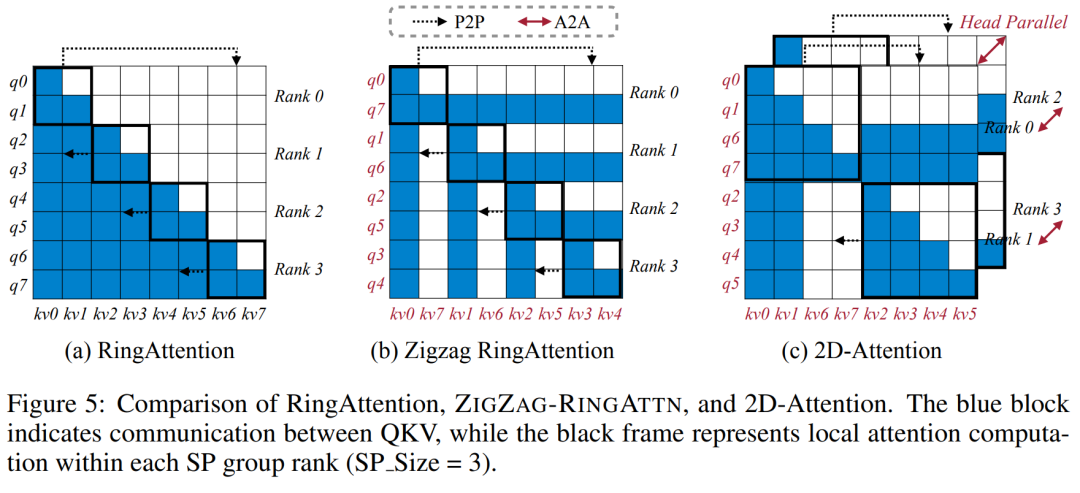
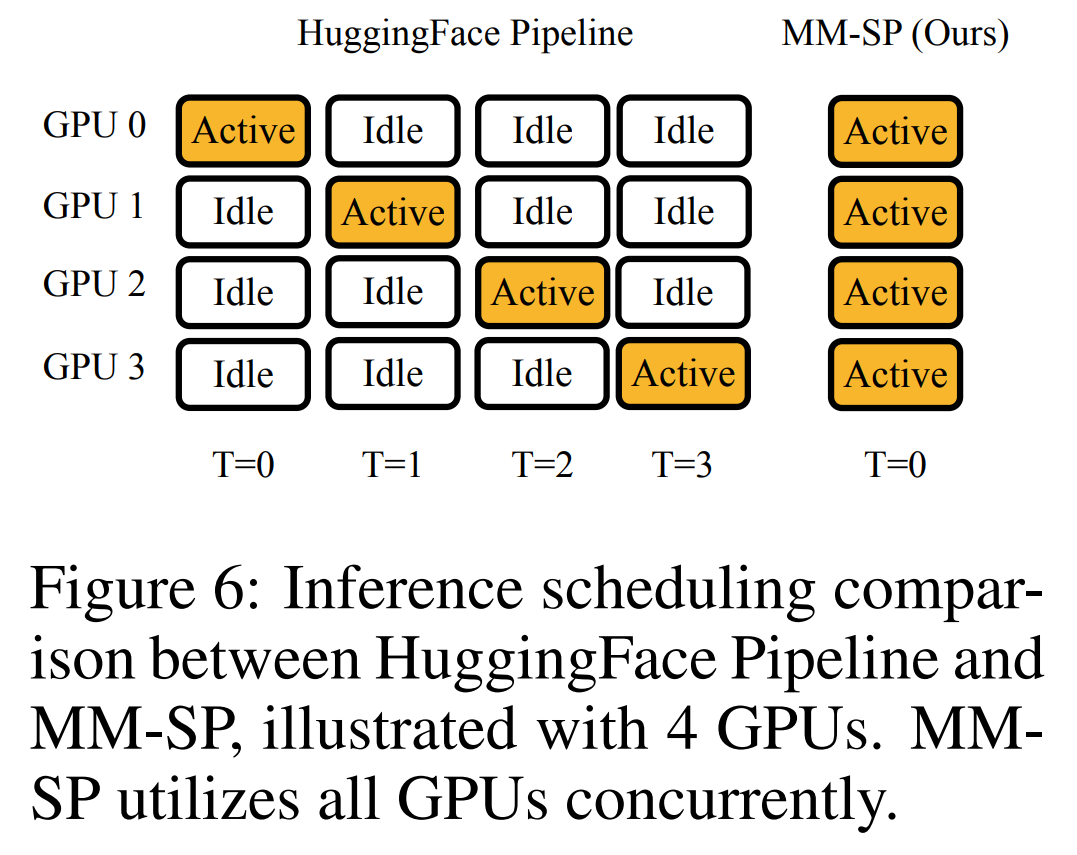
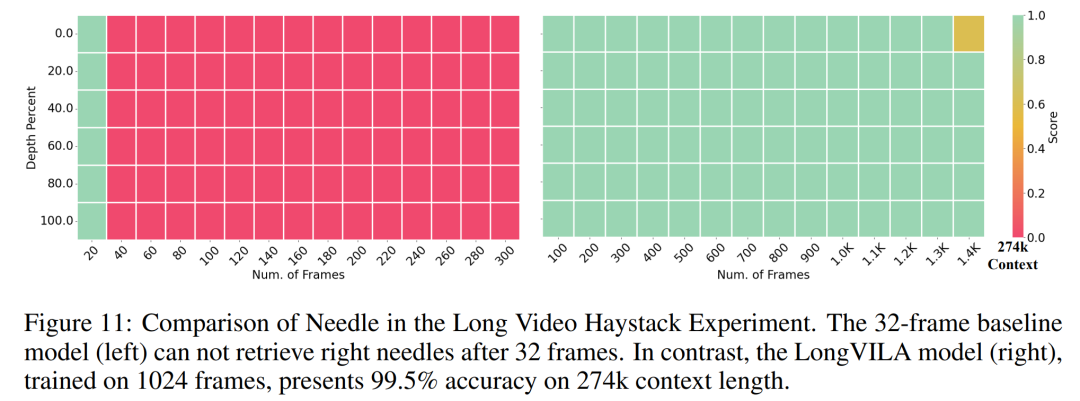
トレーニング インフラストラクチャに関して、研究では効率的でユーザーフレンドリーなフレームワーク、すなわち Multimodal Sequence Parallel (MM-SP) を確立しました。 )、トレーニング メモリ (高密度ロング コンテキスト VLM) をサポートします。 トレーニング パイプラインに関して、研究者らは、図 1 に示すように、5 段階のトレーニング プロセスを実装しました。つまり、(1) マルチモーダル アライメント、(2) 大規模な事前トレーニング、(3) 短期トレーニング監視付き微調整、(4) LLM のコンテキスト拡張、および (5) 長期監視付き微調整。 推論として、MM-SP は、非常に長いシーケンスを処理するときにボトルネックになる可能性がある KV キャッシュ メモリ使用量の課題を解決します。 LongVILA を使用してビデオ フレーム数を増やすことにより、この研究のパフォーマンスが VideoMME および長いビデオ字幕タスクで向上し続けることが実験結果で示されています (図 2)。 1,024 フレームでトレーニングされた LongVILA モデルは、1,400 フレームの干し草の山に針を刺す実験で 99.5% の精度を達成しました。これは、274,000 トークンのコンテキスト長に相当します。さらに、MM-SP システムは、勾配チェックポイントなしでコンテキスト長を 200 万トークンまで効果的に拡張でき、リング シーケンス並列処理と比較して 2.1 倍から 5.7 倍の高速化を達成し、メガトロン コンテキスト並列処理と Tensor 並列処理は比較して 1.1 倍から 1.4 倍の高速化を達成します。テンソル並列に。 下の図は、長いビデオの字幕を処理する場合の LongVILA テクノロジーの例です。字幕の先頭では、8 フレームのベースライン モデルは静止画像と 2 台の車のみを記述します。これに対し、LongVILA の 256 フレームには、雪上の車が正面、背面、側面から描かれています。細部の点では、256 フレームの LongVILA では、8 フレームのベースライン モデルには欠けているイグニッション ボタン、ギア レバー、計器クラスターのクローズ アップも描かれています。 ロングコンテキスト視覚言語モデル (VLM) のトレーニングでは、大量のメモリ要件が発生します。たとえば、以下の図 1 のステージ 5 の長いビデオ トレーニングでは、1 つのシーケンスに 1024 のビデオ フレームを生成する 200K トークンが含まれており、これは 1 つの GPU のメモリ容量を超えています。 研究者らは、シーケンス並列処理に基づいてカスタマイズされたシステムを開発しました。逐次並列処理は、テキストのみの LLM トレーニングを最適化するために現在の基本モデル システムで一般的に使用される手法です。しかし、研究者らは、既存のシステムがロングコンテキストの VLM ワークロードを処理できるほど効率的でも拡張性でもないことを発見しました。既存システムの限界を特定した後、研究者らは、効率を優先するために、理想的なマルチモーダルシーケンス並列アプローチがモーダルとネットワークの不均一性を解決する必要があると結論付けました。スケーラビリティは、アテンション ヘッドの数によって制限されるべきではありません。 MM-SP ワークフロー。モーダル異質性の課題に対処するために、研究者らは、画像エンコードと言語モデリングの段階での計算ワークロードを最適化する 2 段階のシャーディング戦略を提案しています。 以下の図 4 に示すように、最初のステージでは、まずシーケンス並列処理グループ内のデバイス間で画像 (ビデオ フレームなど) を均等に分配します。 、これにより、画像エンコード段階での負荷分散が実現されます。第 2 段階では、研究者はトークンレベルのシャーディングのためにグローバルなビジュアルおよびテキスト入力を集約します。 2D 注意並列処理。ネットワークの異質性を解決し、スケーラビリティを実現するために、研究者はリング シーケンスの並列処理と Ulysses シーケンスの並列処理の利点を組み合わせています。 具体的には、シーケンス次元またはアテンションヘッド次元にわたる並列性を「1D SP」とみなします。この方法は、アテンション ヘッドとシーケンス次元にわたる並列計算を通じてスケーリングし、1D SP をリング (P2P) プロセスとユリシーズ (A2A) プロセスの独立したグループで構成される 2D グリッドに変換します。 以下の図 3 の左側に示すように、2 つのノード間で 8 度のシーケンス並列性を達成するために、研究者は 2D-SP を使用して4 × 2 の通信グリッドを構築します。 さらに、以下の図 5 では、ZIGZAG-RINGATTN が計算のバランスをどのように取るか、および 2D アテンション メカニズムがどのように動作するかをさらに説明するために、研究者らは注意計算スキームのさまざまな方法の使用について説明します。 HuggingFace のネイティブ パイプライン並列戦略と比較すると、この記事の推論モードは、すべてのデバイスが同時に計算に参加するため、より効率的です。下の図 6 に示すように、プロセスは地上に比べて加速されます。同時に、この推論モードはスケーラブルであり、メモリがデバイス間で均等に分散されるため、より多くのマシンを使用してより長いシーケンスをサポートできます。 #🎜 🎜 #前述したように、LongVILAのトレーニングプロセスは5つの段階に分かれています。各ステージの主なタスクは次のとおりです。
ステージ 1 では、マルチモーダル マッパーのみをトレーニングでき、他のマッパーはフリーズされます。
ステージ 2 では、研究者はビジュアル エンコーダーをフリーズし、LLM とマルチモーダル マッパーをトレーニングしました。
ステージ 3 では、研究者は、画像や短いビデオ データ セットの使用などのタスクに続く短いデータ命令用にモデルを包括的に微調整します。
ステージ 4 では、研究者はテキストのみのデータセットを使用して、継続的な事前トレーニング方法で LLM のコンテキスト長を拡張しました。
ステージ 5 では、研究者は長時間のビデオ監視を使用して微調整し、指示に従う能力を強化します。この段階ではすべてのパラメータをトレーニングできることに注目してください。
#🎜🎜 #研究者らは、この記事のフルスタック ソリューションをシステムとモデリングの 2 つの側面から評価しました。最初にトレーニングと推論の結果を提示し、ロングコンテキストのトレーニングと推論をサポートできるシステムの効率とスケーラビリティを示します。次に、キャプションと指示に続くタスクに関する長いコンテキスト モデルのパフォーマンスを評価します。 トレーニングと推論システム
#🎜 🎜#この調査では、トレーニング システムのスループット、推論システムのレイテンシー、サポートされる最大シーケンス長の定量的評価が提供されます。
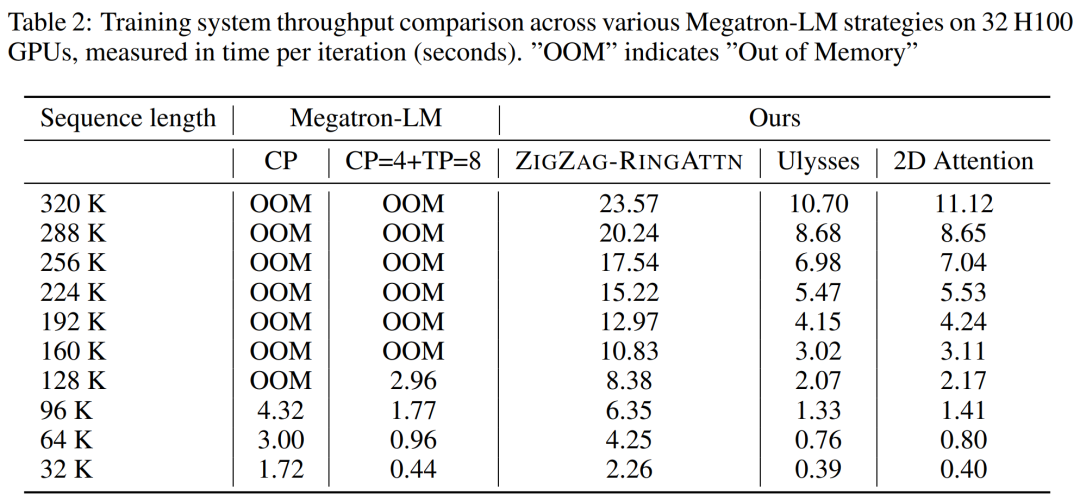
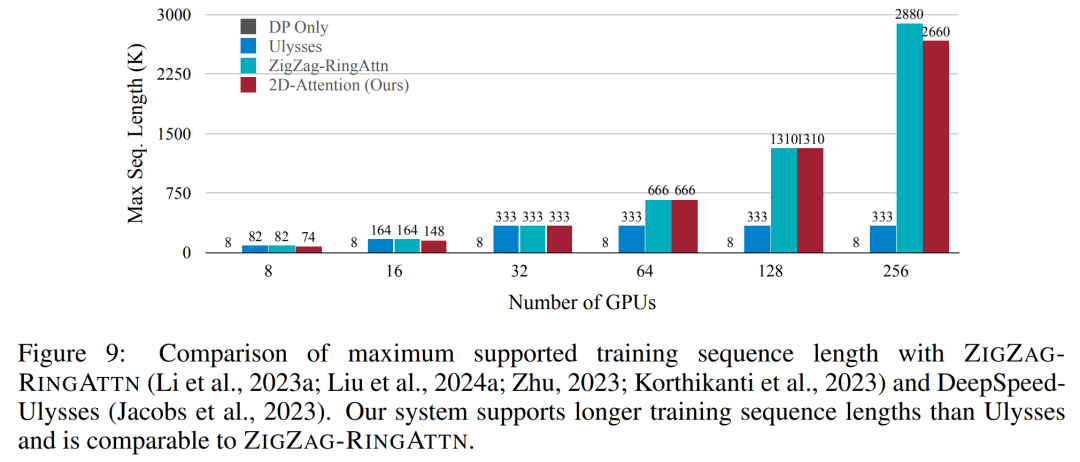
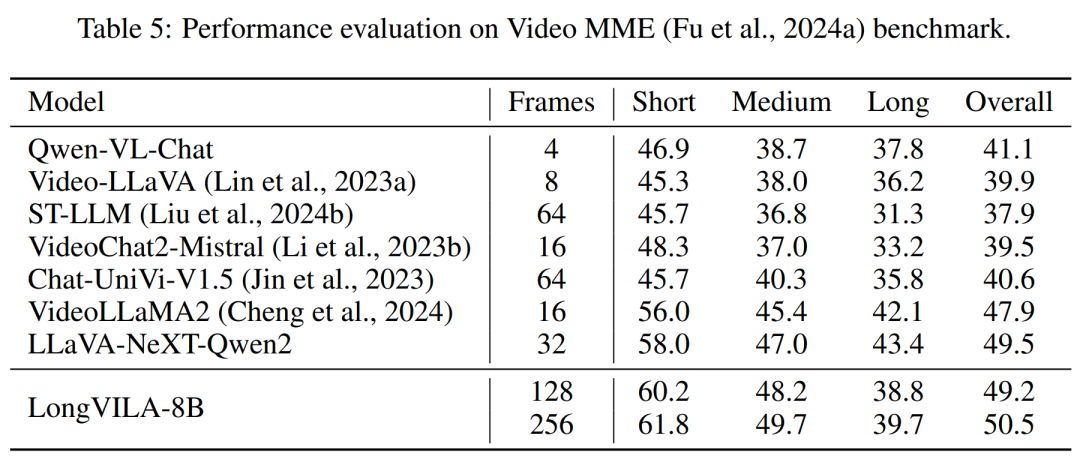
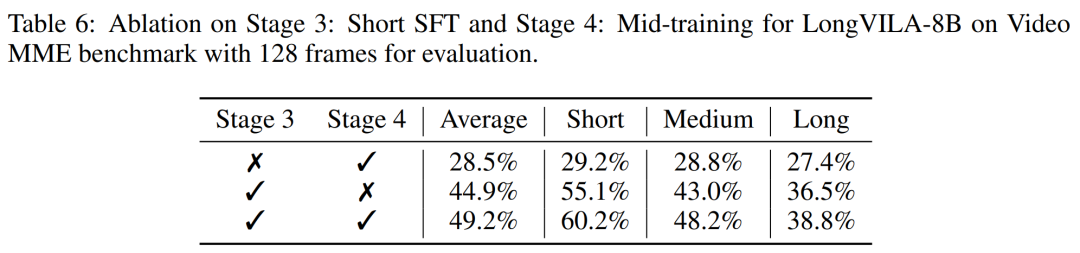
表 2 にスループットの結果を示します。 ZIGZAG-RINGATTNと比較して2.1倍から5.7倍の加速を実現し、DeepSpeed-Ulyssesと同等の性能を発揮します。 Megatron-LM CP のより最適化されたリング シーケンス並列実装と比較して、3.1 倍から 4.3 倍のスピードアップが達成されます。 Diese Studie bewertet die maximale Sequenzlänge, die von einer festen Anzahl von GPUs unterstützt wird, indem die Sequenzlänge schrittweise von 1.000 auf 10.000 erhöht wird, bis ein Fehler wegen unzureichendem Speicher auftritt auftritt. Die Ergebnisse sind in Abbildung 9 zusammengefasst. Bei der Skalierung auf 256 GPUs kann unsere Methode etwa das Achtfache der Kontextlänge unterstützen. Darüber hinaus erreicht das vorgeschlagene System eine Kontextlängenskalierung ähnlich wie ZIGZAG-RINGATTN und unterstützt mehr als 2 Millionen Kontextlängen auf 256 GPUs. Tabelle 3 vergleicht die maximal unterstützten Sequenzlängen, und die in dieser Studie vorgeschlagene Methode unterstützt Sequenzen, die 2,9-mal länger sind als die von HuggingFace Pipeline unterstützten. Abbildung 11 zeigt die Ergebnisse des langen Video-Experiments „Nadel im Heuhaufen“. Im Gegensatz dazu zeigt das LongVILA-Modell (rechts) eine verbesserte Leistung über eine Reihe von Rahmen und Tiefen hinweg. Tabelle 5 listet die Leistung verschiedener Modelle im Video-MME-Benchmark auf und vergleicht sie hinsichtlich der Effektivität und Gesamtleistung bei kurzen, mittleren und langen Videolängen. LongVILA-8B verwendet 256 Bilder und hat eine Gesamtpunktzahl von 50,5. Die Forscher führten außerdem eine Ablationsstudie zu den Auswirkungen der Stadien 3 und 4 in Tabelle 6 durch. Tabelle 7 zeigt die Leistungsmetriken des LongVILA-Modells, das auf einer unterschiedlichen Anzahl von Frames (8, 128 und 256) trainiert und bewertet wurde. Mit zunehmender Anzahl von Frames verbessert sich die Leistung des Modells erheblich. Insbesondere stieg die durchschnittliche Punktzahl von 2,00 auf 3,26, was die Fähigkeit des Modells unterstreicht, bei einer höheren Anzahl von Bildern genaue und reichhaltige Untertitel zu erzeugen. 以上が1024フレームとほぼ100%の精度をサポートするNVIDIA「LongVILA」が長時間ビデオの開発を開始の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。