


2時間の映画を4秒で見た後、アリババチームの新しい成果が正式に発表されました -
複数の写真や長いビデオを理解するために特別に使用される一般的なマルチモーダル大型モデルmPLUG-Owl3を発売しました。

具体的には、LLaVA-Next-Interleave をベンチマークとして使用すると、mPLUG-Owl3 はモデルの First Token Latency を 6 倍削減し、1 台の A100 でモデル化できる画像の数は 8 倍に増加しました。 400 枚に達します 写真 1 枚で、2 時間の映画をわずか 4 秒で見ることができます。
つまり、モデルの推論効率が大幅に向上しました。
しかもモデルの精度を犠牲にすることなく。
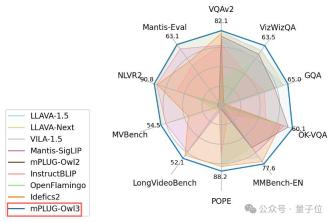
mPLUG-Owl3 は、単一画像、複数画像、およびビデオ フィールドを含むマルチモーダル大規模モデルを含むさまざまなシナリオの多くのベンチマークでも SOTA に達しました。
この論文の著者は、Alibaba mPLUG チームの出身で、これ以前にも、マルチモーダル大規模モデル ベースに深く関与しており、次のことも提案しています。
効率的なマルチモーダル ベース mPLUG シリーズ
-モーダル大規模言語モデル ベース mPLUG -Owl シリーズ
ドキュメント理解ベース mPLUG-DocOwl シリーズ
このリリースの mPLUG-Owl3 がもたらすブラック テクノロジーを調べてみましょう。
ゲームプレイのロック解除
チームは、mPLUG-Owl3 の一般的な使用法をいくつかデモしました。
マルチモーダル検索の強化
一般的に、モデルが学習していない知識を検索システムを通じて補完するのが一般的です。これには、モデルが入ってくるマルチモーダルな知識を正確に理解し、それを使用して質問に答える必要があります。
次の例では、mPLUG-Owl3は取得した知識に基づいて正しく応答するだけでなく、どの知識に基づいて判断し、その判断の詳細な根拠を提供することもできます。これは、開発とデバッグを行う下流の研究開発担当者にとって非常に使いやすいものです。
検索セクション: ここでは、意思決定を行うために検索されたいくつかのマルチモーダルな知識を示します。
質問: 上の 4 枚の犬の写真を観察したことに基づいて、写真 5 の犬を分類できますか?理由を述べてください。
答え: 4 枚の犬の写真の観察に基づいて、写真 5 の犬はアイリッシュ テリアとして分類できます。写真 1 の犬はアイリッシュ テリアとして説明されており、写真 5 の犬は写真 1 の犬と同様の身体的特徴を持っています...

複数の画像による推論
これは人生の状況でよく起こります -
多くのユーザーは 1 つの写真を中心に会話するだけでなく、ユーザーが複数のマテリアルを持っている可能性があり、モデルは異なるマテリアルのコンテンツ間の関係を正しく理解できる必要があります。
以下の例では、mPLUG-Owl3 は 2 つの画像に表示されるものを通じて言語モデルの常識的な知識を有効にし、2 つの画像に基づいて推論を行うことができます。
質問: 左側の動物は右側の環境で生き残ることができますか?解答と解説は必須です。
答え (正解は緑色でマークされています): 一般的な考え方は、環境が寒すぎるため生き残ることができないということです。

別の例では、mPLUG-Owl3 は 2 つの写真間のスタイルの違いを検出できるだけでなく、2 つの写真のキャラクターのスタイルは異なっていても、実際には同じキャラクターであることも認識します。
初めての質問: 写真にはどのようなアート スタイルが描かれていますか?また、それらはどのように異なりますか?
答え: 最初の写真はピクセルスタイルで、2 番目の写真は漫画スタイルです...(理由を教えてください)
2 番目の質問: 両方の写真に誰が写っていますか?彼らの特徴は何でしょうか?
答え: どちらの絵にも、カウボーイハットをかぶった男性が登場しており、彼は 2 つの異なるスタイルで描かれています。

長いビデオの理解
超長いビデオの視聴は、現在のほとんどのモデルではエンドツーエンドで完了できないタスクであり、エージェント フレームワークに基づいている場合、応答速度を保証することが困難です。
mPLUG-Owl3 は 2 時間の映画を視聴し、4 秒以内にユーザーの質問に回答し始めることができます。
ユーザーが映画の最初、中間、最後にある非常に詳細なクリップについて質問しても、mPLUG-Owl3 はそれらに流暢に答えることができます。

どうやってやったの?
従来のモデルとは異なり、mPLUG-Owl3 はビジュアル シーケンスを言語モデルのテキスト シーケンスに事前に結合する必要がありません。
言い換えれば、入力される内容 (数十枚の写真や数時間のビデオ) に関係なく、言語モデルのシーケンス容量を占有しないため、長いビジュアル シーケンスによって引き起こされる膨大なコンピューティング オーバーヘッドとビデオ メモリの使用が回避されます。
視覚情報は言語モデルにどのように統合されるのかと疑問に思う人もいるかもしれません。

これを達成するために、チームは、テキストをモデル化することしかできない既存の Transformer ブロックを、グラフィックとテキストの機能の相互作用とモジュールの新しいモジュールの構築の両方を実行できるように拡張できる、軽量の Hyper tention モジュールを提案しました。

言語モデル全体にわたって 4 つの Transformer ブロックをまばらに拡張することにより、mPLUG-Owl3 は、非常に少ないコストで LLM をマルチモーダル LLM にアップグレードできます。
視覚的特徴が視覚的エンコーダーから抽出された後、単純な線形マッピングを通じて次元が言語モデルの次元に合わせられます。
その後、視覚的特徴は Transformer ブロックのこれら 4 つのレイヤー内のテキストとのみ対話します。視覚的トークンは圧縮を受けていないため、詳細な情報を保持できます。
ハイパー アテンションがどのように設計されているかを見てみましょう。
ハイパーアテンション 言語モデルが視覚的特徴を認識できるようにするために、視覚的特徴をキーと値として使用し、言語モデルの非表示状態をクエリとして使用して視覚的特徴を抽出するクロスアテンション操作が導入されます。
近年、Flamingo や IDEFICS など、他の研究でもマルチモーダル フュージョンにクロスアテンションを使用することが検討されていますが、これらの研究では良好なパフォーマンスを達成できませんでした。
mPLUG-Owl3 の技術レポートでは、チームは Flamingo の設計を比較して、Hyper Attendant の主要な技術的ポイントをさらに説明しました:
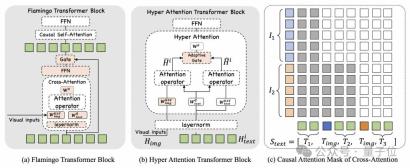
まず第一に、Hyper Attendance は Cross-Attendant の設計を採用していません。 Self-Attend はカスケードしますが、Self-Attend ブロック内に埋め込まれています。
その利点は、導入される追加の新しいパラメーターの数が大幅に減り、モデルのトレーニングが容易になり、トレーニングと推論の効率がさらに向上できることです。
第二に、ハイパー アテンションは、言語モデルを共有する LayerNorm を選択します。これは、LayerNorm によって出力される分布が、アテンション層が安定化するようにトレーニングされた分布とまったく同じであるため、この層を共有することが、新しく導入されたクロスアテンションの安定した学習にとって重要です。
実際、ハイパー アテンションは、クロス アテンションとセルフ アテンションの並行戦略を採用し、共有クエリを使用して視覚機能と対話し、アダプティブ ゲートを通じて 2 つの機能を融合します。
これにより、クエリは、独自のセマンティクスに基づいて、クエリに関連する視覚的特徴を選択的に選択できるようになります。
チームは、モデルがマルチモーダル入力をよりよく理解するためには、元のコンテキストにおける画像とテキストの相対位置が非常に重要であることを発見しました。
このプロパティをモデル化するために、ビジュアル キーの位置情報をモデル化するマルチモーダル インターリーブ回転位置エンコーディング MI-Rope を導入しました。
具体的には、オリジナルのテキスト内の各画像の位置情報が事前に記録されており、この位置を使用して対応するロープの埋め込みを計算し、同じ画像の各パッチがこの埋め込みを共有します。
さらに、クロスアテンションにアテンションマスクも導入されました。これにより、元のコンテキストの画像の前のテキストからは、後続の画像に対応する特徴が見えなくなります。
要約すると、Hyper Attendant のこれらの設計ポイントにより、mPLUG-Owl3 の効率がさらに向上し、依然として一流のマルチモーダル機能を維持できることが保証されました。

実験結果
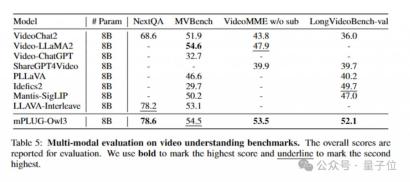
幅広いデータセットで実験を行うことにより、mPLUG-Owl3 は、ほとんどの単一画像マルチモーダル ベンチマークで SOTA 結果を達成し、多くのテストでより大きなモデル サイズのベンチマークを上回る結果を得ることができます。 。
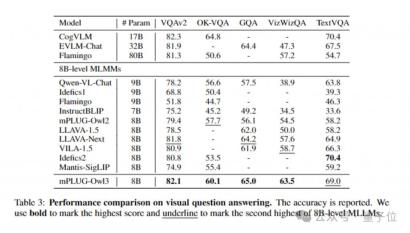
同時に、マルチ画像評価において、mPLUG-Owl3 は、マルチ画像シナリオ用に特別に最適化された LLAVA-Next-Interleave と Mantis も上回りました。
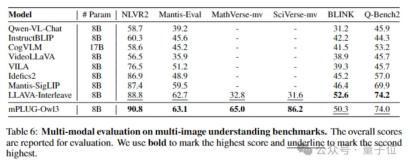
さらに、長いビデオに対するモデルの理解を特に評価するリストである LongVideoBench の既存のモデル (52.1 ポイント) を上回っています。
研究開発チームは、興味深い長い視覚シーケンスの評価方法も提案しました。
ご存知のとおり、人間とコンピューターの実際の対話シナリオでは、すべての写真がユーザーの問題に役立つわけではありません。問題とは無関係なマルチモーダル コンテンツが含まれることになります。この現象は、シーケンスが長ければ長いほど深刻になります。は。
長いビジュアル シーケンス入力におけるモデルの耐干渉能力を評価するために、MMBench-dev に基づいて新しい評価データ セットを構築しました。
MMBench サイクルの評価サンプルごとに無関係な画像を導入し、画像の順序を乱してから、元の画像について質問して、モデルが正しく安定して応答できるかどうかを確認します。 (同じ問題に対して、選択肢と干渉画像の順番が異なるサンプルを4つ作成し、全問正解の場合は正解が1つだけ記録されます。)
実験は入力数に応じて複数のレベルに分かれています写真。
Qwen-VL や mPLUG-Owl2 などのマルチグラフ トレーニングのないモデルはすぐに失敗することがわかります。
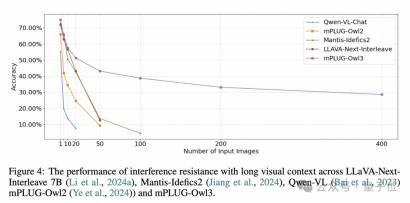
LLAVA-Next-Interleave と Mantis は、複数の画像でトレーニングされており、最初は mPLUG-Owl3 と同様の減衰曲線を維持できますが、画像の数が 50 のレベルに達すると、これらのモデルは正しく答えられなくなりました。
そして、mPLUG-Owl3 は 400 枚の写真でも 40% の精度を維持できます。
ただし、一つ言えることは、mPLUG-Owl3 は既存のモデルを上回っていますが、その精度は優れたレベルには程遠いです。この評価方法は、長いシーケンス下でのすべてのモデルの耐干渉能力を明らかにしているとしか言えません。今後さらに改善する必要があります。
詳細については、論文とコードを参照してください。
ペーパー: https://arxiv.org/abs/2408.04840
コード: https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl3
デモ (ハグ顔) : https://huggingface.co/spaces/mPLUG/mPLUG-Owl3
デモ (マジックコミュニティ): https://modelscope.cn/studios/iic/mPLUG-Owl3
7B モデル (ハグ顔): https:/ /huggingface.co/mPLUG/mPLUG-Owl3-7B-240728
7B モデル (Magic Community) https://modelscope.cn/models/iic/mPLUG-Owl3-7B-240728
— 終了—
送信してくださいメール:
ai@qbitai.com
タイトルを明記して、次の内容をお知らせください:
あなたは誰ですか、どこの出身ですか、投稿内容
論文/プロジェクトのホームページへのリンクを添付し、ご連絡ください情報
時間内に(できるだけ)返信します
ここをクリックして私をフォローし、スターを付けることを忘れないでください〜
3クリックで「共有」、「いいね」、「視聴」してください
毎日会いましょう最先端の科学技術の進歩のために〜
以上が2時間の映画を4秒で観よう!アリババ、ユニバーサルマルチモーダル大型モデルmPLUG-Owl3を発売の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

WebStorm Mac版
便利なJavaScript開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

