マンバ建築の大型モデルが再びトランスフォーマーに挑戦しました。
今回、ついにMambaの建築モデルが「立ち上がる」のでしょうか? 2023 年 12 月の最初の発売以来、マンバはトランスフォーマーの深刻な競争相手として浮上してきました。 それ以来、Mistral がリリースした Mamba アーキテクチャに基づく初のオープンソース大型モデルである Codestral 7B など、Mamba アーキテクチャを使用したモデルが次々と登場してきました。 本日、アブダビ技術革新研究所 (TII) は、新しいオープンソース Mamba モデル – Falcon Mamba 7B をリリースしました。 
まず、Falcon Mamba 7B のハイライトを要約しましょう。メモリ ストレージを増やすことなく、あらゆる長さのシーケンスを処理でき、単一の 24GB A10 GPU で実行できます。 現在、Hugging Face で Falcon Mamba 7B を表示および使用できます。この因果デコーダー専用モデルは、新しい Mamba State Space Language Model (SSLM) アーキテクチャ を使用して、さまざまなテキスト生成タスクを処理します。 結果から判断すると、Falcon Mamba 7B は、Meta の Llama 3 8B、Llama 3.1 8B、Mistral 7B などのいくつかのベンチマークで、そのサイズクラスの主要モデルよりも優れたパフォーマンスを示しています。 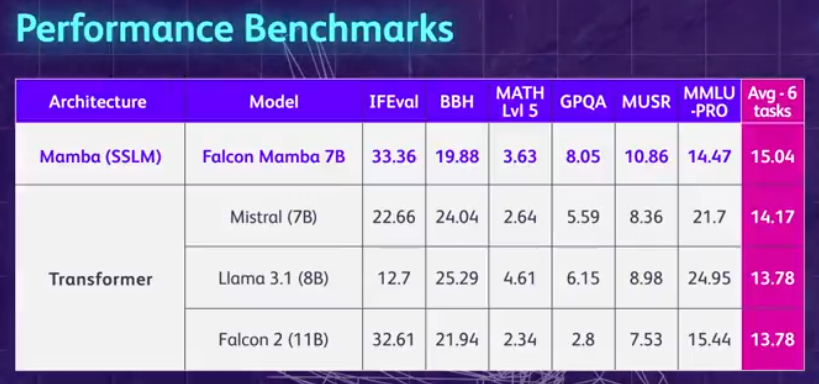
Falcon Mamba 7B は、基本バージョン、コマンド微調整バージョン、4 ビットバージョン、コマンド微調整 4 ビットバージョンの 4 つのバリエーションモデルに分かれています。 
Falcon Mamba 7Bはオープンソースモデルとして、研究や応用目的をサポートするためにApache 2.0ベースのライセンス「Falcon License 2.0」を採用しています。 
Hugging Face アドレス: https://huggingface.co/tiiuae/falcon-mamba-7bFalcon Mamba 7B は、Falcon 180B、Falcon 40B、Falcon 2 Four に続く 3 番目の TII オープンソースにもなりました。これは、初の Mamba SSLM アーキテクチャ モデルです。 
長い間、Transformer ベースのモデルが生成 AI の主流を占めてきましたが、研究者は、Transformer アーキテクチャには長いテキスト情報の処理が難しいことに気づいています。遭遇するかもしれない。 基本的に、Transformer のアテンション メカニズムは、各単語 (またはトークン) をテキスト内の各単語と比較することでコンテキストを理解します。これには、増大するコンテキスト ウィンドウを処理するために、より多くの計算能力とメモリ要件が必要になります。 しかし、それに応じて計算リソースを拡張しないと、モデルの推論速度が遅くなり、一定の長さを超えるテキストを処理できなくなります。これらの障害を克服するために、単語を処理しながら状態を継続的に更新することで動作する状態空間言語モデル (SSLM) アーキテクチャが有望な代替手段として浮上しており、TII を含む多くの機関で導入されています。 Falcon Mamba 7B は、もともとカーネギーメロン大学とプリンストン大学の研究者によって 2023 年 12 月の論文で提案されたMamba SSM アーキテクチャ を使用しています。 このアーキテクチャでは、モデルが入力に基づいてパラメーターを動的に調整できるようにする選択メカニズムが使用されています。このようにして、モデルは、Transformer でのアテンション メカニズムの動作と同様に、特定の入力に焦点を当てたり無視したりできると同時に、追加のメモリや計算リソースを必要とせずに長いテキスト シーケンス (書籍全体など) を処理する機能を提供します。 TII は、このアプローチによりモデルがエンタープライズ レベルの機械翻訳、テキスト要約、コンピューター ビジョンと音声処理タスク、推定と予測などのタスクに適したものになると指摘しました。 Falcon Mamba 7Bトレーニングデータは最大5500GTで、主にRefinedWebデータセットに、公開ソースからの高品質の技術データ、コードデータ、数学データが追加されています。 。すべてのデータは Falcon-7B/11B トークナイザーを介してトークン化されます。 他の Falcon シリーズ モデルと同様に、Falcon Mamba 7B は多段階トレーニング戦略を使用してトレーニングされており、コンテキストの長さは 2048 から 8192 に増加しています。さらに、コース学習の概念に触発され、TII はデータの多様性と複雑さを十分に考慮して、トレーニング フェーズ全体を通じて混合データを慎重に選択します。 最終トレーニング段階では、TII はパフォーマンスをさらに向上させるために、厳選された高品質のデータ (つまり、Fineweb-edu からのサンプル) の小さなセットを使用します。 Falcon Mamba 7B のトレーニングのほとんどは、3D 並列処理 (TP=1、PP=1、 ) ZeROと組み合わせた戦略。以下の図は、精度、オプティマイザー、最大学習率、重み減衰、バッチ サイズなど、モデルのハイパーパラメーターの詳細を示しています。 具体而言,Falcon Mamba 7B 经过了 AdamW 优化器、WSD(预热 - 稳定 - 衰减)学习率计划的训练, 并且在前 50 GT 的训练过程中,batch 大小从 b_min=128 增加到了 b_max=2048。在稳定阶段,TII 使用了最大学习率 η_max=6.4×10^−4,然后使用超过 500GT 的指数计划将其衰减到最小值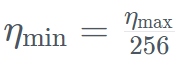 。同时,TII 在加速阶段采用了 BatchScaling 以重新调整学习率 η,使得 Adam 噪声温度
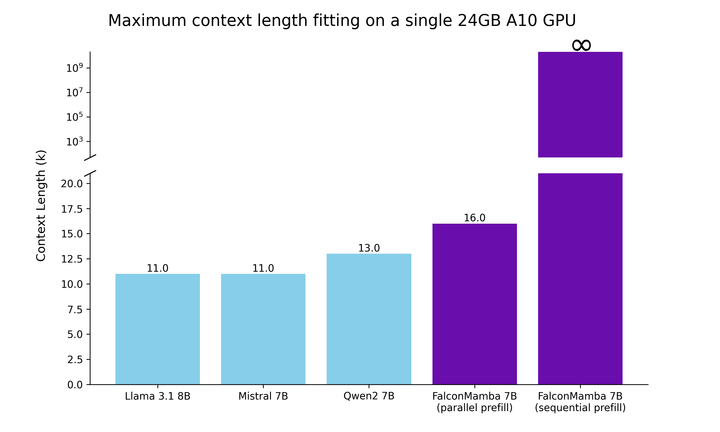
。同时,TII 在加速阶段采用了 BatchScaling 以重新调整学习率 η,使得 Adam 噪声温度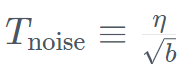 保持恒定。为了了解 Falcon Mamba 7B 与同尺寸级别领先的 Transformer 模型相比如何,该研究进行了一项测试,以确定使用单个 24GB A10GPU 时模型可以处理的最大上下文长度。结果显示,Falcon Mamba 能够比当前的 Transformer 模型适应更大的序列,同时理论上能够适应无限的上下文长度。
保持恒定。为了了解 Falcon Mamba 7B 与同尺寸级别领先的 Transformer 模型相比如何,该研究进行了一项测试,以确定使用单个 24GB A10GPU 时模型可以处理的最大上下文长度。结果显示,Falcon Mamba 能够比当前的 Transformer 模型适应更大的序列,同时理论上能够适应无限的上下文长度。
接下来,研究者使用批处理大小为 1 ,硬件采用 H100 GPU 的设置中测量模型生成吞吐量。结果如下图所示,Falcon Mamba 以恒定的吞吐量生成所有 token,并且 CUDA 峰值内存没有任何增加。对于 Transformer 模型,峰值内存会增加,生成速度会随着生成的 token 数量的增加而减慢。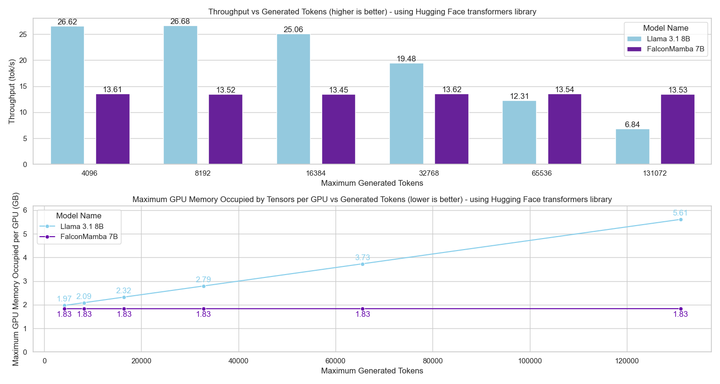
即使在标准的行业基准测试中,新模型的性能也优于或接近于流行的 transformer 模型以及纯状态空间模型和混合状态空间模型。例如,在 Arc、TruthfulQA 和 GSM8K 基准测试中,Falcon Mamba 7B 的得分分别为 62.03%,53.42% 和 52.54%,超过了 Llama 3 8 B, Llama 3.1 8B, Gemma 7B 和 Mistral 7B。然而,在 MMLU 和 Hellaswag 基准测试中,Falcon Mamba 7B 远远落后于这些模型。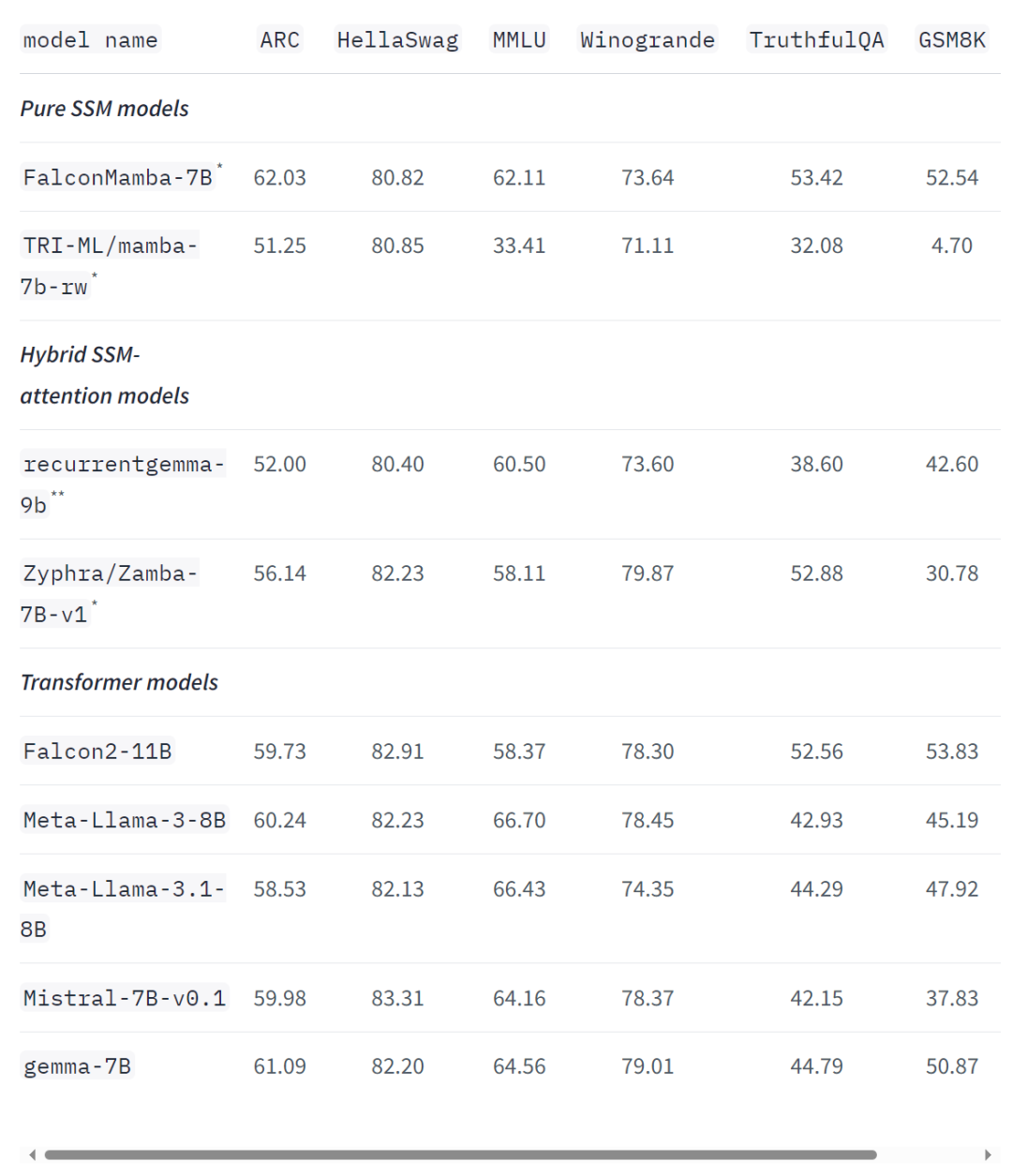

TII 首席研究员 Hakim Hacid 在一份声明中表示:Falcon Mamba 7B 的发布代表着该机构向前迈出的重大一步,它激发了新的观点,并进一步推动了对智能系统的探索。在 TII,他们正在突破 SSLM 和 transformer 模型的界限,以激发生成式 AI 的进一步创新。目前,TII 的 Falcon 系列语言模型下载量已超过 4500 万次 —— 成为阿联酋最成功的 LLM 版本之一。Falcon Mamba 7B 论文即将放出,大家可以等一等。https://huggingface.co/blog/falconmambahttps://venturebeat.com/ai/falcon-mamba-7bs-powerful-new-ai-architecture-offers-alternative-to-transformer-models/以上がノントランスアーキテクチャが立ち上がる!オープンソースの巨人 Llama 3.1 を超える、初の純粋なアテンションフリーの大型モデルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

