
出発の時間ですか?再構築する時が来ました!ツイッターを作る

- 王林オリジナル
- 2024-08-12 22:34:351104ブラウズ
マスクと Twitter にうんざりしているユーザーにとって、新しいソーシャル ネットワークの最も重要な機能は次のとおりです。
- Twitter の archive.zip ファイルをインポートします
- できるだけ簡単に登録できます
- 同一ではないにしても同様のユーザー機能
それほど重要ではありませんが、間違いなく役立つプラットフォームの機能です。
- 倫理的に収益化され、モデレートされている
- AI を活用して問題のあるコンテンツを特定する
- Onfido または SMART ID サービスを使用する青いチェックマーク
この投稿では、最初の機能に焦点を当てます。 Twitter の archive.zip ファイルをインポートしています。
ファイル
Twitter では、データをそれほど簡単に入手できるわけではありません。彼らがあなたにそれにアクセスできるようにするのは素晴らしいことです(法的にはそうしなければなりません)。フォーマットがクソだ。
実際にはミニ Web アーカイブとして提供され、すべてのデータは JavaScript ファイルに保存されます。これは、データの便利なストレージというよりは、Web アプリに近いものです。
Your archive.html ファイルを開くと、次のような内容が表示されます。
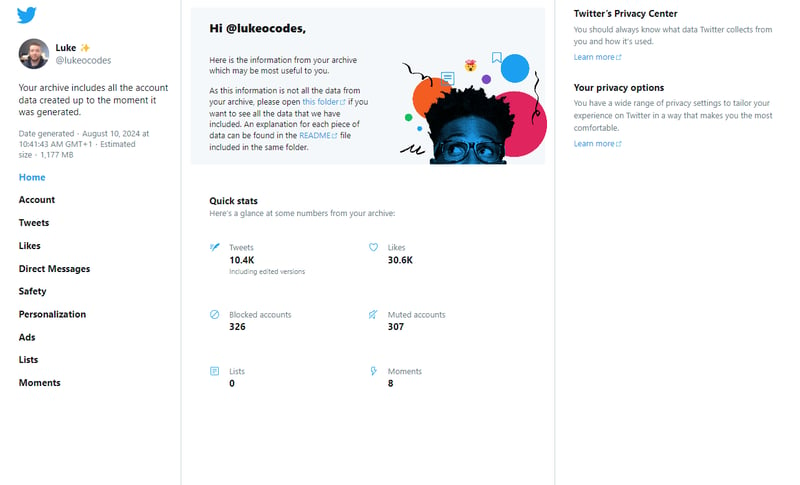
注: 私はかなり早い段階で、サイトには Next.js を使用し、バックエンドには Go と GraphQL を使用して構築することを決定しました。
では、データが構造化データではない場合はどうすればよいでしょうか?
まあ、あなたはそれを解析します。
基本的な Go スクリプトの作成
Go の開始方法に関する公式ドキュメントに進み、プロジェクト ディレクトリを設定してください。
私たちはこのプロセスを一緒にハックしていきます。これは、TwitterX に愛着を感じすぎる人々を惹きつける最も重要な機能の 1 つであるようです。
最初のステップは、main.go ファイルを作成することです。このファイルでは、 (笑) いくつかの作業を行います。
- os.Args: これはコマンドライン引数を保持するスライスです。
- os.Args[0] はプログラムの名前で、os.Args[1] はプログラムに渡される最初の引数です。
- 引数チェック: この関数は、少なくとも 1 つの引数が指定されているかどうかをチェックします。そうでない場合は、パスを要求するメッセージを出力します。
- run 関数: この関数は、今のところ、渡されたパスを単に出力するだけです。
package main
import (
"fmt"
"os"
)
func run(path string) {
fmt.Println("Path:", path)
}
func main() {
if len(os.Args) < 2 {
fmt.Println("Please provide a path as an argument.")
return
}
path := os.Args[1]
run(path)
}
各ステップで、次のようにファイルを実行します。
go run main.go twitter.zip
Twitter アーカイブのエクスポートがない場合は、単純な manifest.js ファイルを作成し、次の JavaScript を指定します。
window.__THAR_CONFIG = {
"userInfo" : {
"accountId" : "1234567890",
"userName" : "lukeocodes",
"displayName" : "Luke ✨"
},
};
それを twitter.zip ファイルに圧縮し、全体で使用します。
ZIPファイルを読む
次のステップは、zip ファイルの内容を読み取ることです。これをできるだけ効率的に実行し、ディスク上でデータが抽出される時間を短縮したいと考えています。
zip 内には解凍する必要のないファイルも多数あります。
main.go ファイルを編集します;
- ZIP ファイルを開く: zip.OpenReader() 関数は、パスで指定された ZIP ファイルを開くために使用されます。
- ファイルの反復処理: この関数は、zip.File のスライスである r.File を使用して、ZIP アーカイブ内の各ファイルをループします。各ファイルの Name プロパティが出力されます。
package main
import (
"archive/zip"
"fmt"
"log"
"os"
)
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
fmt.Println("Files in the zip archive:")
for _, f := range r.File {
fmt.Println(f.Name)
}
}
func main() {
// Example usage
if len(os.Args) < 2 {
log.Fatal("Please provide the path to the zip file as an argument.")
}
path:= os.Args[1]
run(path)
}
JS限定!私たちは構造化データを探しています
このアーカイブ ファイルはまったく役に立ちません。 /data ディレクトリ内の .js ファイルのみをチェックしたいと考えています。
- ZIP ファイルを開く: ZIP ファイルは zip.OpenReader() を使用して開きます。
- /data ディレクトリの確認: プログラムは ZIP アーカイブ内のファイルを繰り返し処理します。 strings.HasPrefix(f.Name, "data/") を使用して、ファイルが /data ディレクトリに存在するかどうかを確認します。
- .js ファイルの検索: プログラムは、filepath.Ext(f.Name) を使用して、ファイルに .js 拡張子が付いているかどうかもチェックします。
- 内容の読み取りと印刷: /data ディレクトリで .js ファイルが見つかった場合、プログラムはその内容を読み取り、印刷します。
package main
import (
"archive/zip"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"strings"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc) // deprecated? :/
if err != nil {
log.Fatal(err)
}
// Print the contents
fmt.Printf("Contents of %s:\n", file.Name)
fmt.Println(string(contents))
}
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
fmt.Println("JavaScript files in the zip archive:")
for _, f := range r.File {
// Use filepath.Ext to check the file extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file so we don't end up printing a gazillion lines when testing
}
}
}
func main() {
// Example usage
if len(os.Args) < 2 {
log.Fatal("Please provide the path to the zip file as an argument.")
}
path:= os.Args[1]
run(path)
}
JSを解析してみよう!私たちはそのデータが欲しいのです
構造化データを発見しました。次に、それを解析する必要があります。良いニュースは、Go 内で JavaScript を使用するための既存のパッケージがあることです。 gojaを使用します。
このセクションを読んでいて Goja に詳しく、ファイルの出力を見たことがあるなら、今後エラーが発生することがわかるかもしれません。
goja をインストールします:
go get github.com/dop251/goja
次に、main.go ファイルを編集して次のことを行います。
- goja による解析: goja.New() 関数は新しい JavaScript ランタイムを作成し、vm.RunString(processedContents) はそのランタイム内で処理された JavaScript コードを実行します。
- 解析中のエラーを処理する
package main
import (
"archive/zip"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"strings"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc) // deprecated? :/
if err != nil {
log.Fatal(err)
}
// Parse the JavaScript file using goja
vm := goja.New()
_, err = vm.RunString(contents)
if err != nil {
log.Fatalf("Error parsing JS file: %v", err)
}
fmt.Printf("Parsed JavaScript file: %s\n", file.Name)
}
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
fmt.Println("JavaScript files in the zip archive:")
for _, f := range r.File {
// Use filepath.Ext to check the file extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file so we don't end up printing a gazillion lines when testing
}
}
}
func main() {
// Example usage
if len(os.Args) < 2 {
log.Fatal("Please provide the path to the zip file as an argument.")
}
path:= os.Args[1]
run(path)
}
驚きました。 「ウィンドウが定義されていません」はよくあるエラーかもしれません。基本的に goja は EMCA ランタイムを実行します。ウィンドウはブラウザのコンテキストであるため、残念ながら利用できません。
実際にJSを解析する
この時点でいくつかの問題を解決しました。これには、トップレベルの JS ファイルであるためデータを返せないことも含まれます。
簡単に言えば、ファイルをランタイムにロードする前にファイルの内容を変更する必要があります。
main.go ファイルを変更しましょう;
- reConfig: A regex that matches any assignment of the form window.someVariable = { and replaces it with var data = {.
- reArray: A regex that matches any assignment of the form window.someObject.someArray = [ and replaces it with var data = [
- Extracting data: Running the script, we use vm.Get("data") to retrieve the value of the data variable from the JavaScript context.
package main
import (
"archive/zip"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"regexp"
"strings"
"github.com/dop251/goja"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc)
if err != nil {
log.Fatal(err)
}
// Regular expressions to replace specific patterns
reConfig := regexp.MustCompile(`window\.\w+\s*=\s*{`)
reArray := regexp.MustCompile(`window\.\w+\.\w+\.\w+\s*=\s*\[`)
// Replace patterns in the content
processedContents := reConfig.ReplaceAllStringFunc(string(contents), func(s string) string {
return "var data = {"
})
processedContents = reArray.ReplaceAllStringFunc(processedContents, func(s string) string {
return "var data = ["
})
// Parse the JavaScript file using goja
vm := goja.New()
_, err = vm.RunString(processedContents)
if err != nil {
log.Fatalf("Error parsing JS file: %v", err)
}
// Retrieve the value of the 'data' variable from the JavaScript context
value := vm.Get("data")
if value == nil {
log.Fatalf("No data variable found in the JS file")
}
// Output the parsed data
fmt.Printf("Processed JavaScript file: %s\n", file.Name)
fmt.Printf("Data extracted: %v\n", value.Export())
}
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
for _, f := range r.File {
// Check if the file is in the /data directory and has a .js extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file so we don't end up printing a gazillion lines when testing
}
}
}
func main() {
// Example usage
if len(os.Args) < 2 {
log.Fatal("Please provide the path to the zip file as an argument.")
}
path:= os.Args[1]
run(path)
}
Hurrah. Assuming I didn't muck up the copypaste into this post, you should now see a rather ugly print of the struct data from Go.
JSON would be nice
Edit the main.go file to marshall the JSON output.
- Use value.Export() to get the data from the struct
- Use json.MarshallIndent() for pretty printed JSON (use json.Marshall if you want to minify the output).
package main
import (
"archive/zip"
"encoding/json"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"regexp"
"strings"
"github.com/dop251/goja"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc) // deprecated :/
if err != nil {
log.Fatal(err)
}
// Regular expressions to replace specific patterns
reConfig := regexp.MustCompile(`window\.\w+\s*=\s*{`)
reArray := regexp.MustCompile(`window\.\w+\.\w+\.\w+\s*=\s*\[`)
// Replace patterns in the content
processedContents := reConfig.ReplaceAllStringFunc(string(contents), func(s string) string {
return "var data = {"
})
processedContents = reArray.ReplaceAllStringFunc(processedContents, func(s string) string {
return "var data = ["
})
// Parse the JavaScript file using goja
vm := goja.New()
_, err = vm.RunString(processedContents)
if err != nil {
log.Fatalf("Error parsing JS file: %v", err)
}
// Retrieve the value of the 'data' variable from the JavaScript context
value := vm.Get("data")
if value == nil {
log.Fatalf("No data variable found in the JS file")
}
// Convert the data to a Go-native type
data := value.Export()
// Marshal the Go-native type to JSON
jsonData, err := json.MarshalIndent(data, "", " ")
if err != nil {
log.Fatalf("Error marshalling data to JSON: %v", err)
}
// Output the JSON data
fmt.Println(string(jsonData))
}
func run(zipFilePath string) {
// Open the zip file
r, err := zip.OpenReader(zipFilePath)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
for _, f := range r.File {
// Check if the file is in the /data directory and has a .js extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file
}
}
}
func main() {
// Example usage
if len(os.Args) < 2 {
log.Fatal("Please provide the path to the zip file as an argument.")
}
zipFilePath := os.Args[1]
run(zipFilePath)
}
That's it!
go run main.go twitter.zip
}
"userInfo": {
"accountId": "1234567890",
"displayName": "Luke ✨",
"userName": "lukeocodes"
}
}
Open source
I'll be open sourcing a lot of this work so that others who want to parse the data from the archive, can store it how they like.
以上が出発の時間ですか?再構築する時が来ました!ツイッターを作るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。