
ホームページ >テクノロジー周辺機器 >AI >ビデオモデルに速い目と遅い目を追加すると、Apple のトレーニング不要の新しいメソッドはすべての SOTA を数秒で上回ります
ビデオモデルに速い目と遅い目を追加すると、Apple のトレーニング不要の新しいメソッドはすべての SOTA を数秒で上回ります

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-08-11 16:02:31603ブラウズ
低速パス: 可能な限り多くの空間詳細を保持しながら、低フレーム レートで特徴を抽出します (例: 8 フレームごとに 24×24 トークンを保持) 高速パス: 高フレーム レートで実行しますが、空間プーリングのステップ サイズを大きくして、ビデオの解像度を下げて、より大きな時間的コンテキストをシミュレートし、アクションの一貫性を理解することに重点を置きます



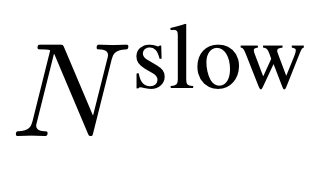 à partir de F_v, où
à partir de F_v, où 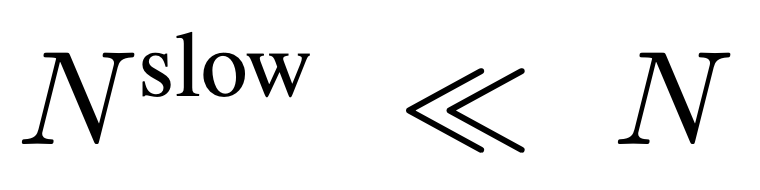 .
. 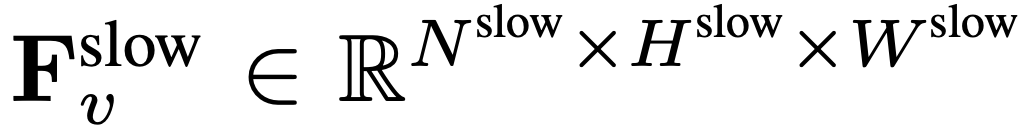 , où
, où 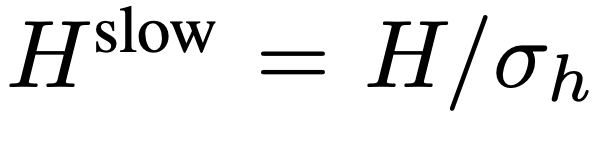 ,
, 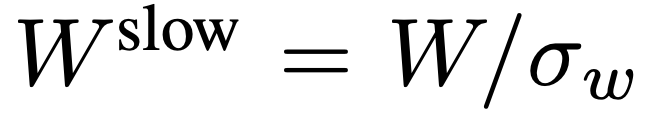 . L’ensemble du processus du chemin lent est illustré dans l’équation 2.
. L’ensemble du processus du chemin lent est illustré dans l’équation 2. 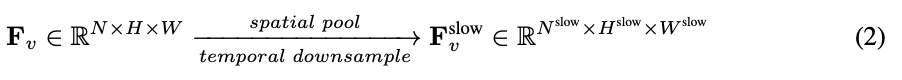
 pour sous-échantillonner de manière agressive F_v afin d’obtenir la caractéristique finale
pour sous-échantillonner de manière agressive F_v afin d’obtenir la caractéristique finale 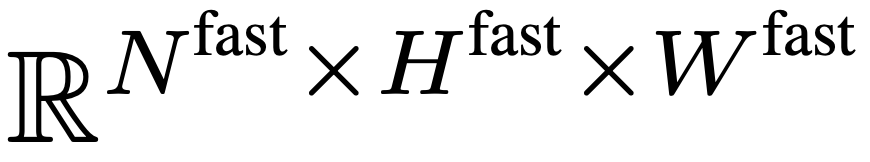 . L'équipe de recherche a mis en place
. L'équipe de recherche a mis en place  ,
, 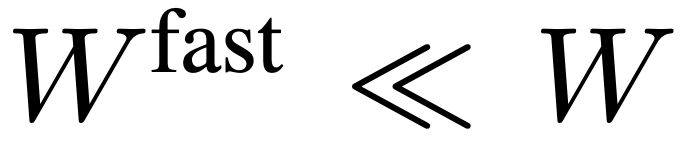 afin que la voie rapide puisse se concentrer sur la simulation du contexte temporel et des signaux de mouvement. L’ensemble du processus du chemin lent est illustré dans l’équation 3.
afin que la voie rapide puisse se concentrer sur la simulation du contexte temporel et des signaux de mouvement. L’ensemble du processus du chemin lent est illustré dans l’équation 3. 
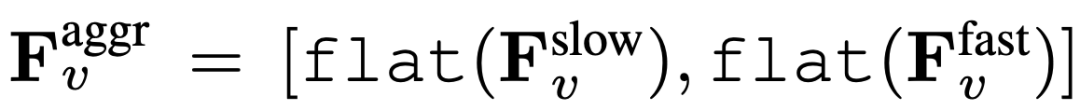 , où flat et [, ] représentent respectivement les opérations d'aplatissement et de concaténation. Comme le montre l'expression,
, où flat et [, ] représentent respectivement les opérations d'aplatissement et de concaténation. Comme le montre l'expression, 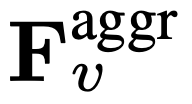 ne nécessite aucun jeton spécial pour séparer les chemins lents et rapides. SF-LLaVA utilise un total de
ne nécessite aucun jeton spécial pour séparer les chemins lents et rapides. SF-LLaVA utilise un total de 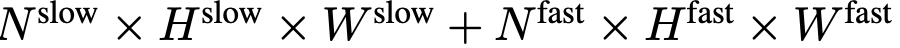 jetons vidéo. Les caractéristiques visuelles de la vidéo
jetons vidéo. Les caractéristiques visuelles de la vidéo 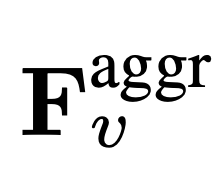 seront combinées avec des informations textuelles (telles que les questions posées par les utilisateurs) et envoyées comme données d'entrée à un grand modèle de langage (LLM) pour traitement.
seront combinées avec des informations textuelles (telles que les questions posées par les utilisateurs) et envoyées comme données d'entrée à un grand modèle de langage (LLM) pour traitement. 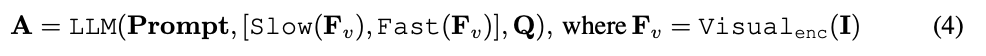
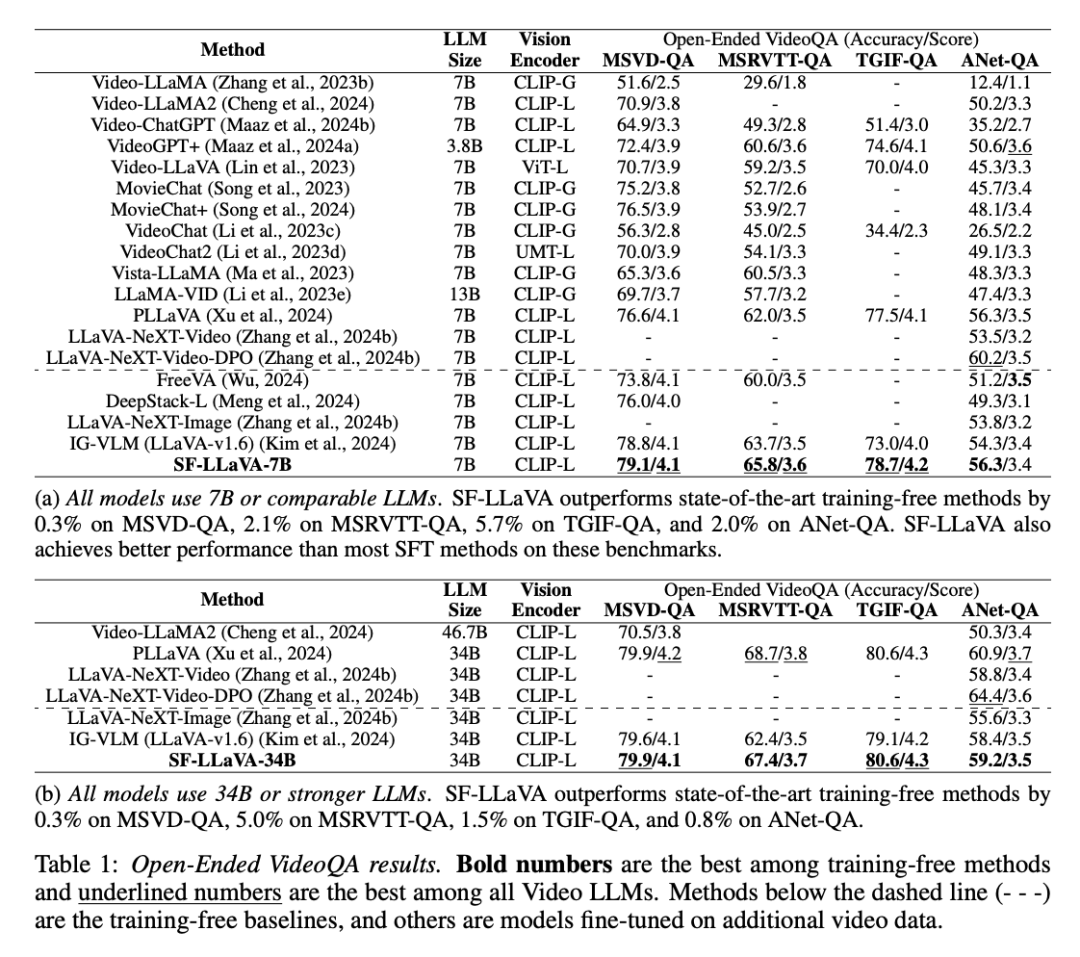
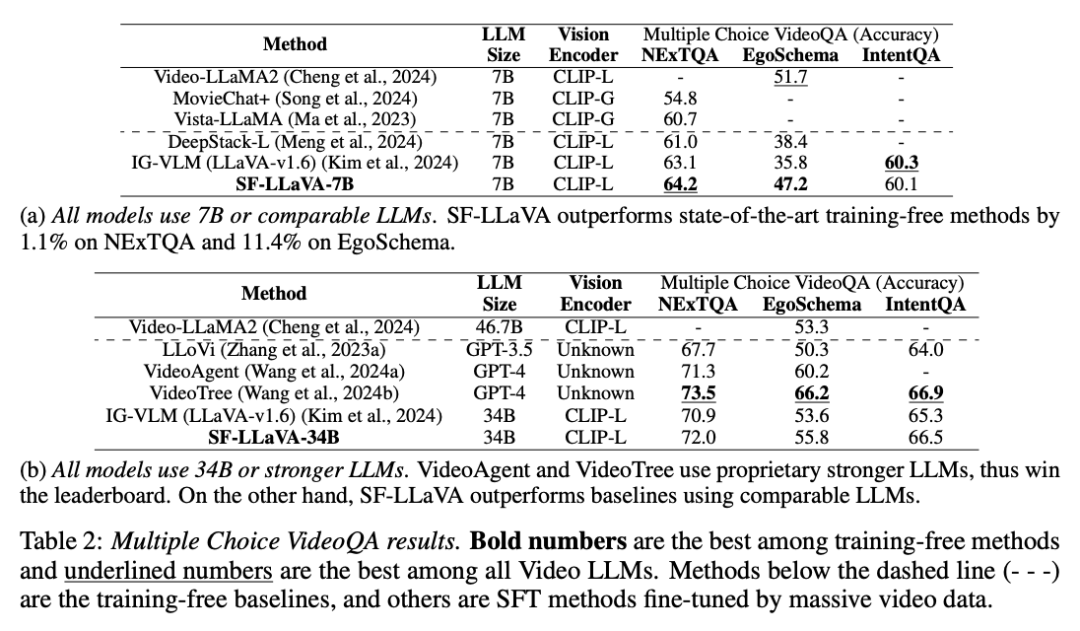
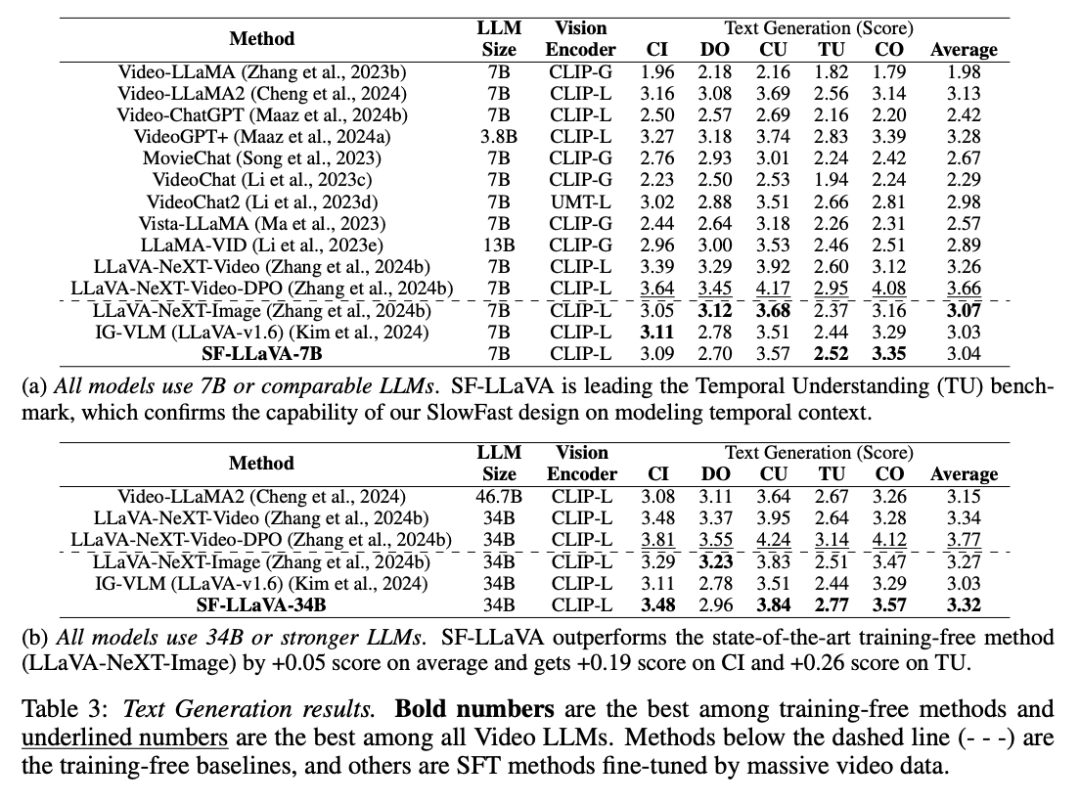
以上がビデオモデルに速い目と遅い目を追加すると、Apple のトレーニング不要の新しいメソッドはすべての SOTA を数秒で上回りますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。