
ホームページ >バックエンド開発 >Python チュートリアル >データを理解する: 探索的データ分析の基礎
データを理解する: 探索的データ分析の基礎

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-08-10 07:03:02619ブラウズ
探索的データ分析は、データセットを分析し、結果を視覚的に提示するための一般的なアプローチです。これは、データセットと構造について最大限の洞察を提供するのに役立ちます。これは、探索的データ分析がデータのさまざまな側面を理解するための手法であることを示しています。
データをよりよく理解するには、データがクリーンで、冗長性や欠損値、さらには NULL 値がないことを確認する必要があります。
探索的データ分析の種類
主に 3 つのタイプがあります:
Univariate: ここでは、一度に 1 つの変数 (列) を確認します。これは変数の性質をより深く理解するのに役立ち、最も簡単なタイプの EDA と呼ばれます。
二変量: ここでは 2 つの変数を一緒に調べます。これは、変数 A と B が独立しているか相関しているかに関係なく、それらの関係を理解するのに役立ちます。
多変量: これには、一度に 3 つ以上の変数を調べることが含まれます。これは「高度な」二変量として識別されます。
メソッド
グラフィック: これには、グラフやチャートなどの視覚的表現を通じてデータを探索することが含まれます。一般的な視覚化には、箱ひげ図、棒グラフ、散布図、ヒート マップが含まれます。
非グラフィック: これは統計的手法によって行われます。使用される指標には、平均、中央値、最頻値、標準偏差、パーセンタイルが含まれます。
探索的データ分析ツール
EDA に使用される最も一般的なツールには次のようなものがあります
Python: 既存のコンポーネントを接続し、欠損値を特定するために使用されるオブジェクト指向プログラミング言語
R: 統計計算で使用されるオープンソース プログラミング言語
手順
- データを理解する - 扱っているデータの種類を確認します。列、行、データ型の数。
- データをクリーンアップします – これには、欠損値、欠落行、NULL 値などの不規則な作業が含まれます。
- 分析 – 変数間の関係を分析します。
Python を使用したサンプル EDA
この例で使用されているデータセットは Iris データセットです - ここから入手できます
- パンダライブラリを使用してデータをロードします。
df = pd.read_csv(io.BytesIO(uploaded['Iris.csv'])) df.head()

- データ型を識別する df.info()
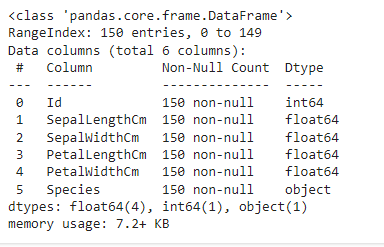
- データをクリーンアップします。例: NULL 値のチェック df.isnull().sum()

- 変数情報を提供するためのデータの非グラフィカル分析 df.describe()

- 変数の相関関係または独立性を示すグラフ分析
df.plot(kind='scatter', x='SepalLengthCm', y='SepalWidthCm') ; plt.show()

以上がデータを理解する: 探索的データ分析の基礎の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。