
ホームページ >テクノロジー周辺機器 >AI >ICML 2024 | 文字インタラクション画像、あなたのプロンプトの言葉がよりよく理解できるようになりました、北京大学が意味認識に基づく文字インタラクション画像生成フレームワークを開始
ICML 2024 | 文字インタラクション画像、あなたのプロンプトの言葉がよりよく理解できるようになりました、北京大学が意味認識に基づく文字インタラクション画像生成フレームワークを開始

- PHPzオリジナル
- 2024-08-08 21:01:32789ブラウズ

AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。投稿メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
キャラクターインタラクション画像生成とは、テキスト記述要件を満たす画像を生成することを指し、その内容は人と物体との間のインタラクションであり、画像は可能な限り現実的で意味論的であることが求められます。近年、テキスト生成画像モデルは現実の画像の生成において大きな進歩を遂げていますが、これらのモデルは、人間のインタラクションを主なコンテンツとして忠実度の高い画像を生成するという点で依然として課題に直面しています。この困難は主に 2 つの側面から生じます。第 1 に、人間の姿勢の複雑さと多様性が合理的なキャラクター生成に課題をもたらし、第 2 に、インタラクティブな境界領域 (インタラクティブな意味が豊富な領域) の信頼性の低い生成が、キャラクターのインタラクティブな意味表現の失敗につながる可能性があります。不十分。
上記の問題に応えて、北京大学の研究チームは、人間の姿勢の生成品質とインタラクション境界領域情報をガイドとして使用する、姿勢とインタラクションを意識した人間インタラクション画像生成フレームワーク (SA-HOI) を提案しました。ノイズ除去プロセスにより、より合理的でリアルなキャラクター インタラクション イメージが生成されます。また、生成された画像の品質を総合的に評価するために、包括的なヒューマンインタラクション画像生成ベンチマークも提案しました。

紙のリンク: https://proceedings.mlr.press/v235/xu24e.html
プロジェクトのホームページ: https://sites.google.com/view/sa-hoi/
ソースコードリンク: https://github.com/XZPKU/SA-HOI
研究室ホームページ: http://www.wict.pku.edu.cn/mipl
SA-HOI は Aセマンティックを意識したヒューマン インタラクション画像生成方法は、ヒューマン インタラクション画像生成の全体的な品質を向上させ、人体の姿勢とインタラクティブ セマンティクスの両方から生じる既存の生成問題を軽減します。画像反転方法を組み合わせることで、反復反転および画像補正プロセスが生成され、生成された画像を徐々に自己補正して品質を向上させることができます。
研究チームは論文の中で、人間と物体、人間と動物、人間と人間の相互作用をカバーする初の人間相互作用画像生成ベンチマークも提案し、人間相互作用画像生成のための対象を絞った評価指標を設計しました。広範な実験により、この方法は、人間のインタラクション画像生成と従来の画像生成の両方の評価基準の下で、既存の拡散ベースの画像生成方法よりも優れていることが示されています。 methodはじめにメソッドはじめに
ポスチャーとインタラクティブなガイダンス(ポーズと相互作用ガイダンス、豚)および帯状の反転と修正プロセス(反復反転および改良パイプライン、IIR)。 PIG では、特定のキャラクター インタラクション テキスト説明 インタラクティブなガイダンスでは、セグメンテーション モデルを使用してインタラクション境界領域の位置を特定し、キー ポイント ポーズとインタラクションに基づくサンプリングの擬似コードを図 2 に示します。各ノイズ除去ステップでは、まず、安定拡散モデル (安定拡散) で設計された予測ノイズ ϵt と中間再構成 ϵt を取得します。次に、ガウスぼかし G on を適用して劣化した潜在特徴 と を取得し、その後、対応する潜在特徴の情報をノイズ除去プロセスに導入します。 ここで、 ここで、ϕt はタイム ステップ t でマスクを生成するしきい値です。同様に、インタラクティブなガイダンスの場合、論文の著者はセグメンテーション モデルを使用してオブジェクトの外側の輪郭点 O と人体の関節点 C を取得し、人とオブジェクトの間の距離行列 D を計算し、そのキー ポイントをサンプリングします。同じ方法でインタラクティブなアテンション 反復反転と画像補正プロセス 為了即時獲取生成影像的品質評估,論文作者引入品質評估器 Q,用於作為迭代式 操作的指導。對於第 k 輪的圖像 然而,這樣的噪聲不是現成可得的,為此引入圖像反演方法 透過比較前後迭代輪次中的質量分數,可以判斷是否要繼續進行最佳化:當 人物互動影像產生基準 為了更好地評估生成的人物交互圖像質量,論文作者為人物交互生成量身定制了幾個測評標準,從可靠性(Authenticity)、可行性(Plausibility) 和保真度(Fidelity) 的角度全面評估生成影像。在可靠性上,論文作者引入姿勢分佈距離和人 - 物體距離分佈,評估生成結果和真實圖像是否接近:生成結果在分佈意義上越接近真實圖像,就說明品質越好。可行性上,採用計算姿勢置信度分數來衡量產生人體關節的可信度和合理性。在保真度上,採用人物互動偵測任務,以及圖文檢索任務評估產生影像與輸入文字之間的語意一致性。 與現有方法的對比實驗結果如表 1 和表 2 所示,分別對比了人物交互影像產生指標和常規影像產生指標上的表現。 實驗結果表明,該論文中的方法在人體生成質量,交互語義表達,人物交互距離,人體姿態分佈,整體圖像質量等多個維度的測評上都優於現有模型。 此外,論文作者還進行了主觀評測,邀請眾多用戶從人體質量,物體外觀,交互語義和整體質量等多個角度進行評分,實驗結果證明SA-HOI 的方法在各個角度都更符合人類審美。 表 3:與現有方法的主觀評測結果 圖 4:作用中對接一個結果視覺化相比與原始資料一樣為視覺化。 參考文獻: [1] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent0. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10684–10695, June 2022 . uggingface .co/CompVis/stable-diffusion-v1-4. [3] Chen, K., Wang, J., Pang, J., Cao, Y., Xiong, Y., Li, X, J., Pang, J., Cao, Y., Xiong, Y., Li, X, J., Pang, J., Cao, Y., Xiong, Y., Li, X, J., Pang, J., Cao, Y., Xiong, Y., Li, X, J., Pang, X. ., Sun, S., Feng, W., Liu, Z., Xu, J., Zhang, Z., Cheng, D., Zhu, C., Cheng, T., Zhao, Q., Li , B., Lu, X., Zhu, R., Wu, Y., Dai, J., Wang, J., Shi, J., Ouyang, W., Loy, C. C., and Lin, D. MMDetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155, 2019. [4] Ron Mokady, Anidtz, Kullfir Abman, Kofir Abt. text inversion for editing real images using guided diffusion models. arXiv preprint arXiv:2211.09794, 2022. arXiv:2211.09794, 2022. , Jiaxuan Wang, and Jia Deng. HICO: A benchmark for recognizing human-object interactions in images. In Proceedings of the IEEE International Conference on Computer Vision, 2015. とノイズ
とノイズ  に対して、まず安定拡散モデル (Stable Diffusion [2]) を使用して
に対して、まず安定拡散モデル (Stable Diffusion [2]) を使用して  を初期画像として生成し、姿勢検出器 [3] を使用して画像を取得します。人体の関節位置
を初期画像として生成し、姿勢検出器 [3] を使用して画像を取得します。人体の関節位置  と対応する信頼度スコア
と対応する信頼度スコア  を使用して、低品質のポーズ領域を強調表示するポーズ マスク
を使用して、低品質のポーズ領域を強調表示するポーズ マスク  を構築します。
を構築します。  と対応する信頼スコア
と対応する信頼スコア  を取得し、インタラクション マスク
を取得し、インタラクション マスク  でインタラクション領域を強調表示して、インタラクション境界の意味表現を強化します。各ノイズ除去ステップで、
でインタラクション領域を強調表示して、インタラクション境界の意味表現を強化します。各ノイズ除去ステップで、 と
と  が制約として使用され、これらの強調表示された領域が修正され、それによってこれらの領域に存在する生成の問題が軽減されます。さらに、IIR は画像反転モデル N を組み合わせて、さらなる修正が必要な画像からノイズ n とテキスト記述の埋め込み t を抽出し、PIG を使用して画像に次の修正を実行し、品質評価器 Q を使用します。補正された画像の品質を評価し、 操作を使用して画像の品質を徐々に向上させます。 🎙
が制約として使用され、これらの強調表示された領域が修正され、それによってこれらの領域に存在する生成の問題が軽減されます。さらに、IIR は画像反転モデル N を組み合わせて、さらなる修正が必要な画像からノイズ n とテキスト記述の埋め込み t を抽出し、PIG を使用して画像に次の修正を実行し、品質評価器 Q を使用します。補正された画像の品質を評価し、 操作を使用して画像の品質を徐々に向上させます。 🎙  と
と  は
は  と
と  を生成するために使用され、
を生成するために使用され、 と
と  でポーズ品質の低い領域を強調表示して、これらの領域での歪みの生成を減らすようにモデルをガイドします。低品質領域を改善するようにモデルを導くために、ポーズ スコアの低い領域が次の式によって強調表示されます:
でポーズ品質の低い領域を強調表示して、これらの領域での歪みの生成を減らすようにモデルをガイドします。低品質領域を改善するようにモデルを導くために、ポーズ スコアの低い領域が次の式によって強調表示されます: 
 、x、y は画像のピクセルごとの座標、H、W は画像サイズ、σ はガウス分布の分散です。
、x、y は画像のピクセルごとの座標、H、W は画像サイズ、σ はガウス分布の分散です。  は、i 番目の関節を中心とした注意を表します。すべての関節の注意を組み合わせることで、最終的な注意マップ
は、i 番目の関節を中心とした注意を表します。すべての関節の注意を組み合わせることで、最終的な注意マップ  を形成し、しきい値を使用して をマスク に変換できます。
を形成し、しきい値を使用して をマスク に変換できます。  とマスク
とマスク  が生成され、最終的な予測ノイズの計算に適用されます。
が生成され、最終的な予測ノイズの計算に適用されます。  ,採用評估器 Q 獲取其質量分數
,採用評估器 Q 獲取其質量分數 ,然後基於
,然後基於  生成
生成 。為了在最佳化後保留 的主要內容,需要相應的雜訊作為去噪的初始值。
。為了在最佳化後保留 的主要內容,需要相應的雜訊作為去噪的初始值。  來獲取其噪聲潛在特徵
來獲取其噪聲潛在特徵 和文本嵌入
和文本嵌入 ,作為 PIG 的輸入,生成優化後的結果
,作為 PIG 的輸入,生成優化後的結果 。
。  和
和 之間沒有顯著差異,即低於閾值θ,可以認為該流程可能已經對影像做出了充足的修正,因此結束優化並輸出品質分數最高的影像。
之間沒有顯著差異,即低於閾值θ,可以認為該流程可能已經對影像做出了充足的修正,因此結束優化並輸出品質分數最高的影像。  +「影像」產生任務設計的現有模型和基準,論文作者收集並整合了一個人物互動影像生成基準,包括一個含有150 個人物互動類別的真實人物互動影像資料集,以及若干為人物互動影像產生客製化的評量指標。 該資料集從開源人物交互檢測資料集 HICO-DET [5] 中篩選得到 150 個人物交互類別,涵蓋了人 - 物體、人 - 動物和人 - 人三種不同交互場景。共計收集了 5k 人物交互真實圖像作為該論文的參考資料集,用於評估生成人物交互圖像的品質。
+「影像」產生任務設計的現有模型和基準,論文作者收集並整合了一個人物互動影像生成基準,包括一個含有150 個人物互動類別的真實人物互動影像資料集,以及若干為人物互動影像產生客製化的評量指標。 該資料集從開源人物交互檢測資料集 HICO-DET [5] 中篩選得到 150 個人物交互類別,涵蓋了人 - 物體、人 - 動物和人 - 人三種不同交互場景。共計收集了 5k 人物交互真實圖像作為該論文的參考資料集,用於評估生成人物交互圖像的品質。 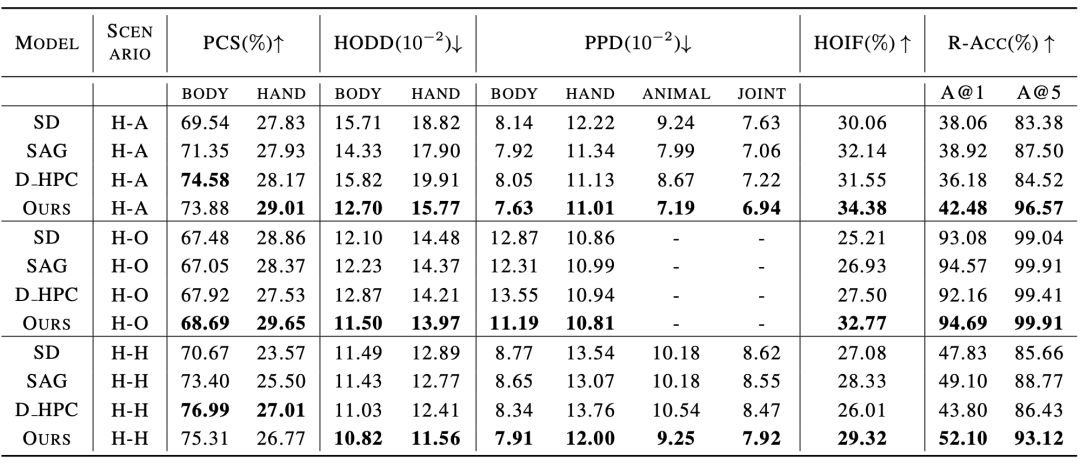 ¢ 表2:與現有方法使用常規影像產生指標時的實驗結果相較
¢ 表2:與現有方法使用常規影像產生指標時的實驗結果相較

以上がICML 2024 | 文字インタラクション画像、あなたのプロンプトの言葉がよりよく理解できるようになりました、北京大学が意味認識に基づく文字インタラクション画像生成フレームワークを開始の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。