


Im Jahr 2023 entwickeln sich fast alle Bereiche der KI in beispielloser Geschwindigkeit weiter. Gleichzeitig verschiebt die KI ständig die technologischen Grenzen wichtiger Bereiche wie der verkörperten Intelligenz und des autonomen Fahrens. Wird Transformer angesichts des multimodalen Trends als Mainstream-Architektur für große KI-Modelle ins Wanken geraten? Warum ist die Erforschung großer Modelle auf Basis der MoE-Architektur (Mixture of Experts) zu einem neuen Trend in der Branche geworden? Kann das Large Vision Model (LVM) ein neuer Durchbruch im allgemeinen Sehvermögen werden? ...Aus dem PRO-Mitglieder-Newsletter 2023 dieser Website, der in den letzten sechs Monaten veröffentlicht wurde, haben wir 10 spezielle Interpretationen ausgewählt, die eine detaillierte Analyse der technologischen Trends und industriellen Veränderungen in den oben genannten Bereichen bieten, um Ihnen dabei zu helfen, Ihre Ziele in der Zukunft zu erreichen Jahr vorbereitet sein. Diese Interpretation stammt aus dem Branchennewsletter Week50 2023.

Datum: 12. Dezember
Ereignis: Mistral AI hat das Modell Mixtral 8x7B auf Basis der MoE-Architektur (Mixture-of-Experts, Mix of Experts) als Open Source bereitgestellt und seine Leistung erreichte das Niveau von Llama 2 70B und GPT-3.5" Die Veranstaltung fand statt. Erweiterte Interpretation.
Erklären Sie zunächst, was MoE ist und welche Vor- und Nachteile es hat
1 Konzept:
MoE (Mixture of Experts) ist ein Hybridmodell, das aus mehreren Untermodellen (d. h. Experten) besteht. Jedes Untermodell ist ein lokales Modell, das auf die Verarbeitung einer Teilmenge des Eingaberaums spezialisiert ist. Die Kernidee von MoE besteht darin, mithilfe eines Gating-Netzwerks zu entscheiden, welches Modell anhand der einzelnen Daten trainiert werden soll, wodurch die Interferenz zwischen verschiedenen Modellen verringert wird Arten von Proben.
2. Hauptkomponenten:
Mixed Expert Model Technology (MoE) ist eine Deep-Learning-Technologie, die aus Expertenmodellen und Gated-Modellen besteht und die Verteilung von Aufgaben/Trainingsdaten auf verschiedene Experten realisiert Modelle über das Gated-Netzwerk, sodass sich jedes Modell auf die Aufgaben konzentrieren kann, die es am besten beherrscht, wodurch die Sparsität des Modells erreicht wird.
① Beim Training des Gated-Netzwerks wird jede Stichprobe einem oder mehreren Experten zugewiesen.
② Bei der Schulung des Expertennetzwerks wird jeder Experte geschult, um die Fehler der ihm zugewiesenen Proben zu minimieren.
Der „Vorgänger“ von MoE ist Ensemble Learning. Beim Ensemble-Lernen werden mehrere Modelle (Basislerner) trainiert, um dasselbe Problem zu lösen, und ihre Vorhersagen einfach kombiniert (z. B. durch Abstimmung oder Mittelung). Das Hauptziel des Ensemble-Lernens besteht darin, die Vorhersageleistung durch Reduzierung der Überanpassung und Verbesserung der Generalisierungsfähigkeiten zu verbessern. Zu den gängigen Ensemble-Lernmethoden gehören Bagging, Boosting und Stacking.
4. Historische Quelle des MoE:
① Die Wurzeln des MoE lassen sich auf das Papier „Adaptive Mixture of Local Experts“ aus dem Jahr 1991 zurückführen. Die Idee ähnelt Ensemble-Ansätzen, da sie darauf abzielt, einen Überwachungsprozess für ein System bereitzustellen, das aus verschiedenen Teilnetzwerken besteht, wobei jedes einzelne Netzwerk oder jeder einzelne Experte auf einen anderen Bereich des Eingaberaums spezialisiert ist. Das Gewicht jedes Experten wird über ein geschlossenes Netzwerk bestimmt. Während des Schulungsprozesses werden sowohl Experten als auch Gatekeeper geschult.
② Zwischen 2010 und 2015 trugen zwei verschiedene Forschungsbereiche zur Weiterentwicklung von MoE bei:
Einer sind Experten als Komponenten: In einem traditionellen MoE-Aufbau besteht das gesamte System aus einem geschlossenen Netzwerk und mehreren Experten. MoEs als ganze Modelle wurden in Support-Vektor-Maschinen, Gaußschen Prozessen und anderen Methoden untersucht. Die Arbeit „Learning Factored Representations in a Deep Mixture of Experts“ untersucht die Möglichkeit von MoEs als Komponenten tieferer Netzwerke. Dadurch kann das Modell gleichzeitig groß und effizient sein.
Das andere ist die bedingte Berechnung: Herkömmliche Netzwerke verarbeiten alle Eingabedaten über jede Ebene. Während dieser Zeit untersuchte Yoshua Bengio Möglichkeiten, Komponenten basierend auf Eingabe-Tokens dynamisch zu aktivieren oder zu deaktivieren.
③ Infolgedessen begannen die Menschen, Expertenmischungsmodelle im Kontext der Verarbeitung natürlicher Sprache zu erforschen. In dem Artikel „Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer“ wurde es durch die Einführung von Sparsity auf ein 137B LSTM erweitert, wodurch schnelles Denken in großem Maßstab erreicht wurde.
Warum verdienen MoE-basierte große Modelle Aufmerksamkeit?1. Im Allgemeinen wird die Erweiterung des Modellmaßstabs zu einem erheblichen Anstieg der Trainingskosten führen, und die Begrenzung der Rechenressourcen ist zu einem Engpass für das intensive Modelltraining in großem Maßstab geworden. Um dieses Problem zu lösen, wird eine Deep-Learning-Modellarchitektur vorgeschlagen, die auf dünn besetzten MoE-Schichten basiert.
2. Das Sparse Mixed Expert Model (MoE) ist eine spezielle neuronale Netzwerkarchitektur, die lernbare Parameter zu großen Sprachmodellen (LLM) hinzufügen kann, ohne die Inferenzkosten zu erhöhen, während Instruction Tuning eine Technik zum Trainieren von LLM ist, um Anweisungen zu befolgen .
3. Die Kombination der MoE+-Anweisungs-Feinabstimmungstechnologie kann die Leistung von Sprachmodellen erheblich verbessern. Im Juli 2023 veröffentlichten Forscher von Google, der UC Berkeley, dem MIT und anderen Institutionen das Papier „Mixture-of-Experts Meets Instruction Tuning: A Winning Combination for Large Language Models“, das bewies, dass das hybride Expertenmodell (MoE) und die Instruction Tuning Die Kombination kann die Leistung großer Sprachmodelle (LLM) erheblich verbessern.
① 具体的には、研究者らは、命令によって微調整された一連のスパース ハイブリッド エキスパート モデル FLAN-MOE でスパース アクティベーション MoE を使用し、Transformer レイヤーのフィードフォワード コンポーネントを MoE レイヤーに置き換えて、より優れたモデル容量とコンピューティングの柔軟性を提供しました。 . パフォーマンス; 次に、FLAN 集合データセットに基づいて FLAN-MOE を微調整します。
② 上記の方法に基づいて、研究者らは、命令チューニングを行わない単一の下流タスクに対する直接微調整、命令チューニング後の下流タスクに対するコンテキスト内の少数ショットまたはゼロショット一般化、および命令チューニングを研究しました。単一の下流タスクをさらに微調整し、3 つの実験設定の下で LLM のパフォーマンスの違いを比較します。
③ 実験結果は、命令チューニングを使用しない場合、MoE モデルは同等の計算能力を持つ高密度モデルよりもパフォーマンスが劣ることが多いことを示しています。しかし、ディレクティブチューニングと組み合わせると状況は変わります。命令調整された MoE モデル (Flan-MoE) は、MoE モデルの計算コストが密モデルの 3 分の 1 しかないにもかかわらず、複数のタスクで大規模な密モデルよりも優れたパフォーマンスを発揮します。高密度モデルとの比較。 MoE モデルは命令チューニングにより大幅なパフォーマンス向上が得られるため、コンピューティングの効率とパフォーマンスを考慮すると、MoE は大規模な言語モデルのトレーニング用の強力なツールになります。
4. 今回リリースされたMixtral 8x7Bモデルもスパース混合エキスパートネットワークを使用しています。
① Mixtral 8x7Bはデコーダー専用モデルです。フィードフォワード モジュールは、8 つの異なるパラメータ セットから選択します。ネットワークの各層で、トークンごとに、ルーター ネットワークは 8 つのグループ (エキスパート) のうち 2 つを選択して、トークンを処理し、その出力を集約します。
② Mixtral 8x7B モデルは、ほとんどのベンチマークで Llama 2 70B および GPT3.5 と同等またはそれを上回り、推論速度が 6 倍高速です。
MoE の重要な利点: スパース性とは何ですか?
1. 従来の高密度モデルでは、各入力を完全なモデルで計算する必要があります。スパース混合エキスパート モデルでは、入力データを処理するときに少数のエキスパート モデルのみがアクティブ化されて使用されますが、ほとんどのエキスパート モデルは非アクティブな状態にあり、スパース性は混合エキスパートの重要な側面です。モデルの利点は、モデルのトレーニングと推論プロセスの効率を向上させる鍵でもあります
以上がPRO | なぜ MoE に基づく大規模モデルがより注目に値するのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

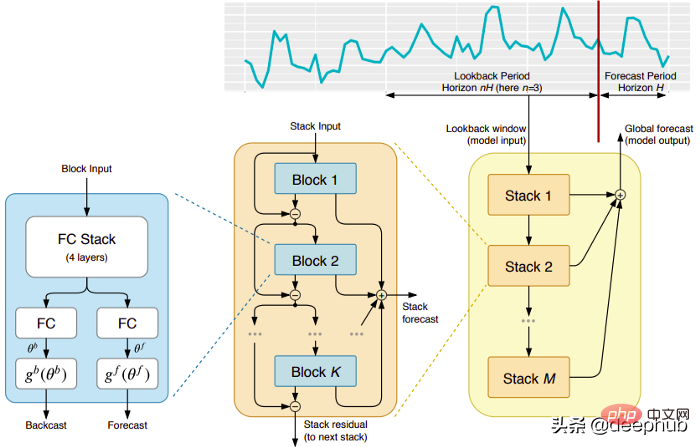 五个时间序列预测的深度学习模型对比总结May 05, 2023 pm 05:16 PM
五个时间序列预测的深度学习模型对比总结May 05, 2023 pm 05:16 PMMakridakisM-Competitions系列(分别称为M4和M5)分别在2018年和2020年举办(M6也在今年举办了)。对于那些不了解的人来说,m系列得比赛可以被认为是时间序列生态系统的一种现有状态的总结,为当前得预测的理论和实践提供了经验和客观的证据。2018年M4的结果表明,纯粹的“ML”方法在很大程度上胜过传统的统计方法,这在当时是出乎意料的。在两年后的M5[1]中,最的高分是仅具有“ML”方法。并且所有前50名基本上都是基于ML的(大部分是树型模型)。这场比赛看到了LightG
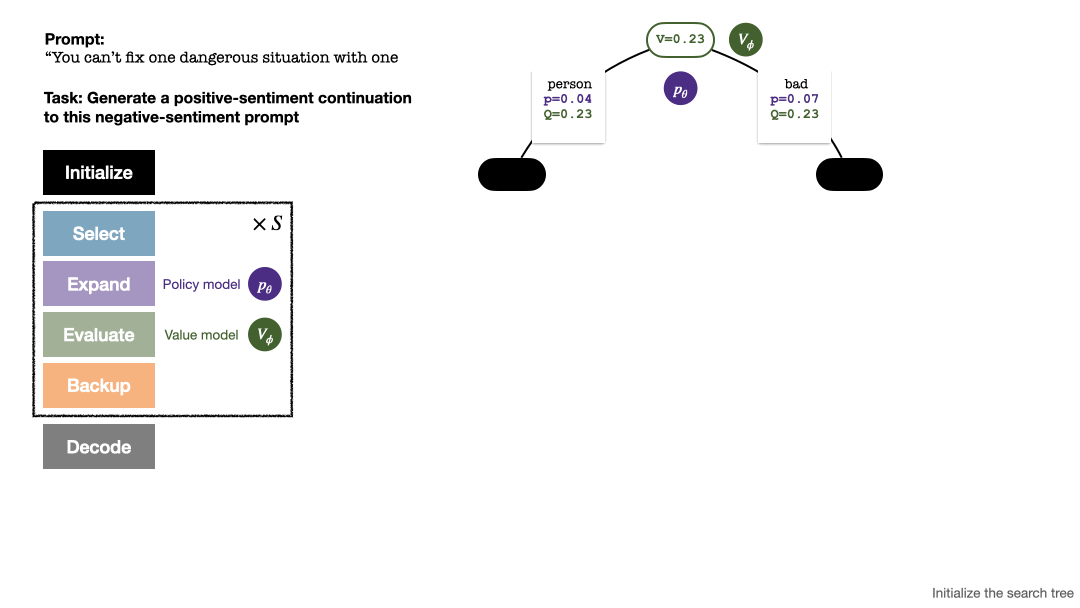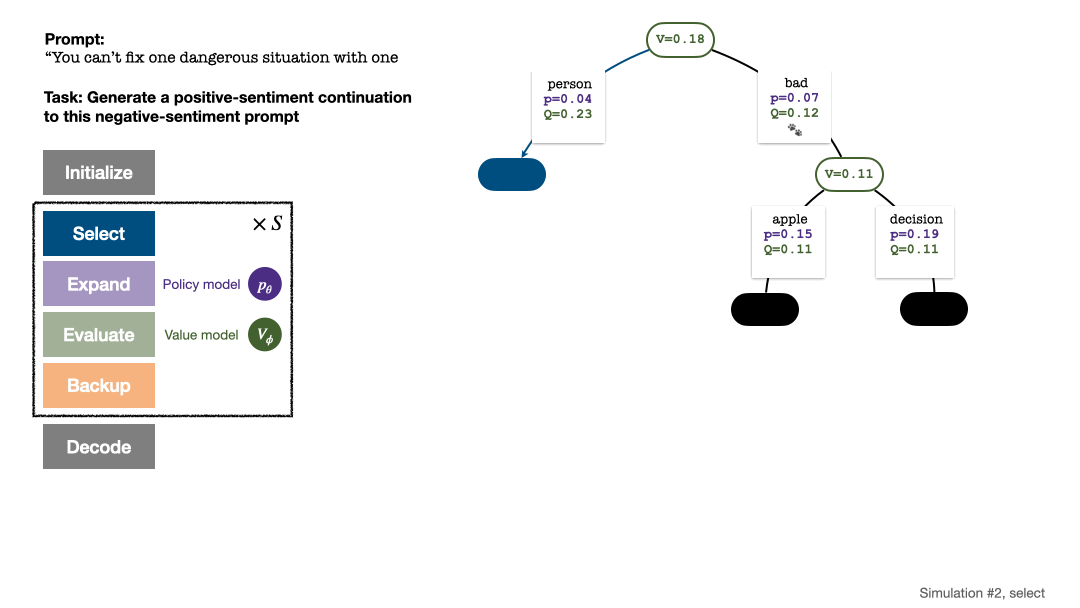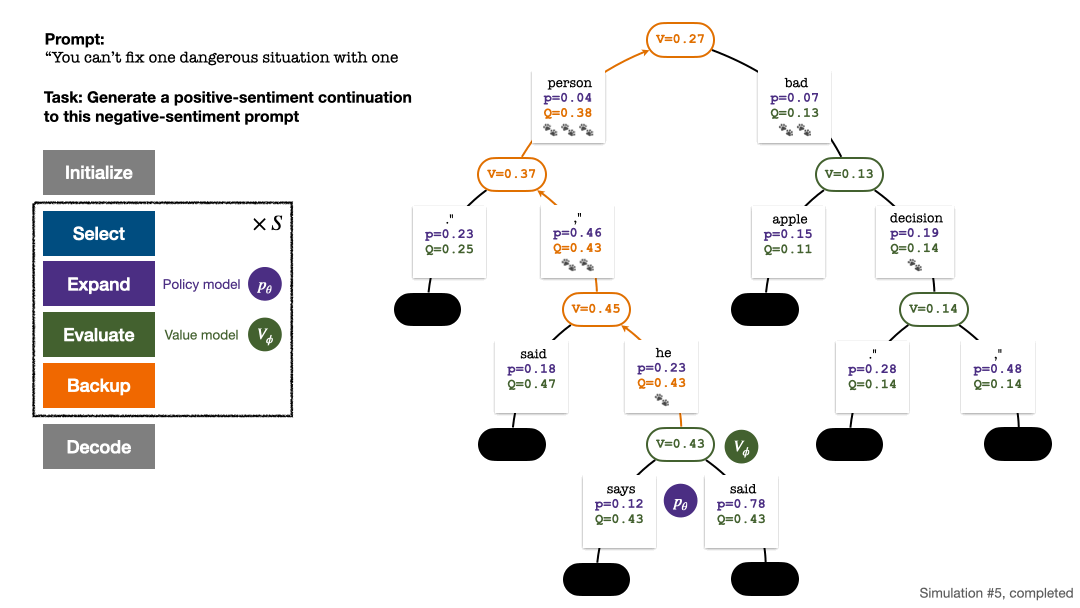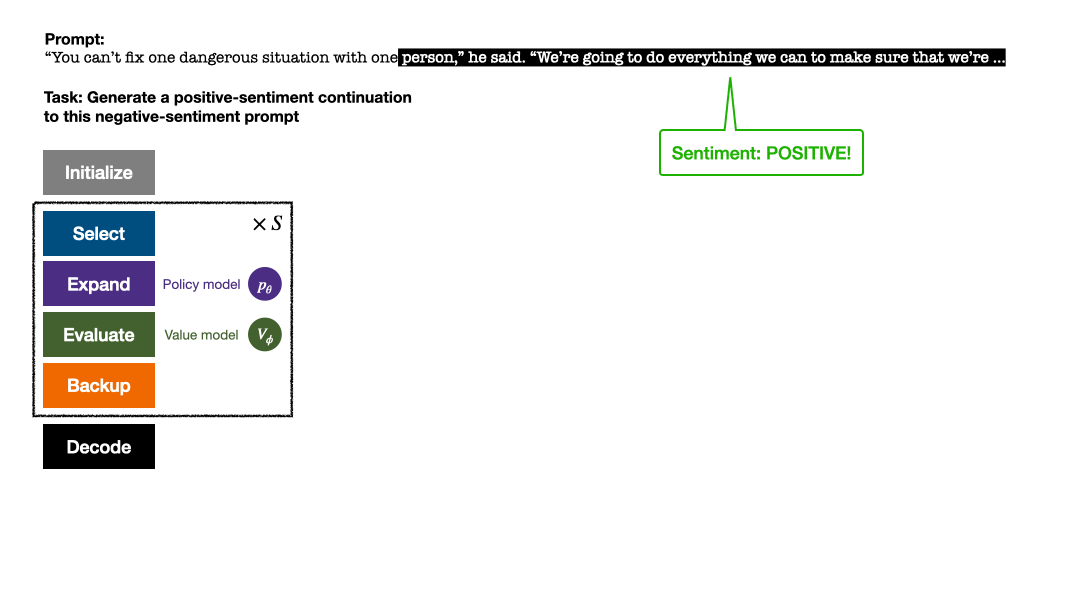 RLHF与AlphaGo核心技术强强联合,UW/Meta让文本生成能力再上新台阶Oct 27, 2023 pm 03:13 PM
RLHF与AlphaGo核心技术强强联合,UW/Meta让文本生成能力再上新台阶Oct 27, 2023 pm 03:13 PM在一项最新的研究中,来自UW和Meta的研究者提出了一种新的解码算法,将AlphaGo采用的蒙特卡洛树搜索算法(Monte-CarloTreeSearch,MCTS)应用到经过近端策略优化(ProximalPolicyOptimization,PPO)训练的RLHF语言模型上,大幅提高了模型生成文本的质量。PPO-MCTS算法通过探索与评估若干条候选序列,搜索到更优的解码策略。通过PPO-MCTS生成的文本能更好满足任务要求。论文链接:https://arxiv.org/pdf/2309.150
 MIT团队运用机器学习闭环自主分子发现平台,成功发现、合成和描述了303种新分子Jan 04, 2024 pm 05:38 PM
MIT团队运用机器学习闭环自主分子发现平台,成功发现、合成和描述了303种新分子Jan 04, 2024 pm 05:38 PM编辑|X传统意义上,发现所需特性的分子过程一直是由手动实验、化学家的直觉以及对机制和第一原理的理解推动的。随着化学家越来越多地使用自动化设备和预测合成算法,自主研究设备越来越接近实现。近日,来自MIT的研究人员开发了由集成机器学习工具驱动的闭环自主分子发现平台,以加速具有所需特性的分子的设计。无需手动实验即可探索化学空间并利用已知的化学结构。在两个案例研究中,该平台尝试了3000多个反应,其中1000多个产生了预测的反应产物,提出、合成并表征了303种未报道的染料样分子。该研究以《Autonom
 AI助力脑机接口研究,纽约大学突破性神经语音解码技术,登Nature子刊Apr 17, 2024 am 08:40 AM
AI助力脑机接口研究,纽约大学突破性神经语音解码技术,登Nature子刊Apr 17, 2024 am 08:40 AM作者|陈旭鹏编辑|ScienceAI由于神经系统的缺陷导致的失语会导致严重的生活障碍,它可能会限制人们的职业和社交生活。近年来,深度学习和脑机接口(BCI)技术的飞速发展为开发能够帮助失语者沟通的神经语音假肢提供了可行性。然而,神经信号的语音解码面临挑战。近日,约旦大学VideoLab和FlinkerLab的研究者开发了一个新型的可微分语音合成器,可以利用一个轻型的卷积神经网络将语音编码为一系列可解释的语音参数(例如音高、响度、共振峰频率等),并通过可微分神经网络将这些参数合成为语音。这个合成器
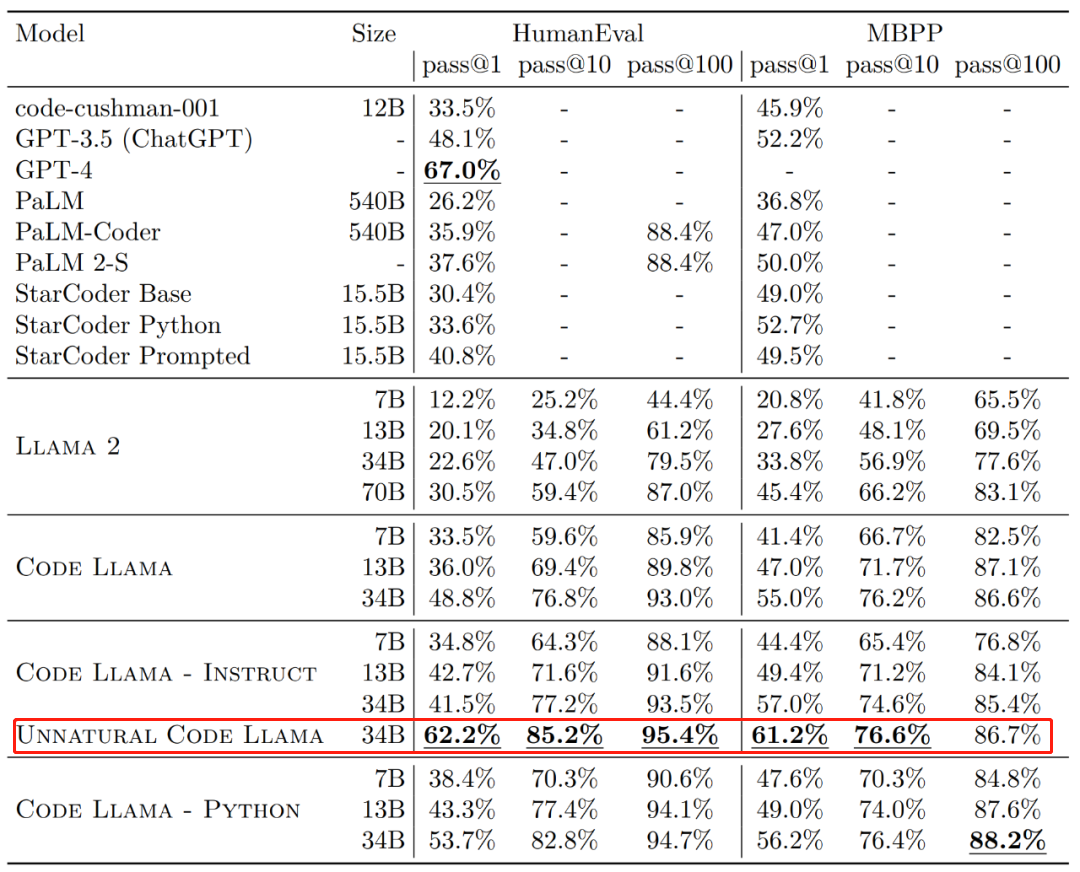 Code Llama代码能力飙升,微调版HumanEval得分超越GPT-4,一天发布Aug 26, 2023 pm 09:01 PM
Code Llama代码能力飙升,微调版HumanEval得分超越GPT-4,一天发布Aug 26, 2023 pm 09:01 PM昨天,Meta开源专攻代码生成的基础模型CodeLlama,可免费用于研究以及商用目的。CodeLlama系列模型有三个参数版本,参数量分别为7B、13B和34B。并且支持多种编程语言,包括Python、C++、Java、PHP、Typescript(Javascript)、C#和Bash。Meta提供的CodeLlama版本包括:代码Llama,基础代码模型;代码羊-Python,Python微调版本;代码Llama-Instruct,自然语言指令微调版就其效果来说,CodeLlama的不同版
 准确率 >98%,基于电子密度的 GPT 用于化学研究,登 Nature 子刊Mar 27, 2024 pm 02:16 PM
准确率 >98%,基于电子密度的 GPT 用于化学研究,登 Nature 子刊Mar 27, 2024 pm 02:16 PM编辑|紫罗可合成分子的化学空间是非常广阔的。有效地探索这个领域需要依赖计算筛选技术,比如深度学习,以便快速地发现各种有趣的化合物。将分子结构转换为数字表示形式,并开发相应算法生成新的分子结构是进行化学发现的关键。最近,英国格拉斯哥大学的研究团队提出了一种基于电子密度训练的机器学习模型,用于生成主客体binders。这种模型能够以简化分子线性输入规范(SMILES)格式读取数据,准确率高达98%,从而实现对分子在二维空间的全面描述。通过变分自编码器生成主客体系统的电子密度和静电势的三维表示,然后通
 手机摄影技术让以假乱真的好莱坞级电影特效视频走红Sep 07, 2023 am 09:41 AM
手机摄影技术让以假乱真的好莱坞级电影特效视频走红Sep 07, 2023 am 09:41 AM一个普通人用一台手机就能制作电影特效的时代已经来了。最近,一个名叫Simulon的3D技术公司发布了一系列特效视频,视频中的3D机器人与环境无缝融合,而且光影效果非常自然。呈现这些效果的APP也叫Simulon,它能让使用者通过手机摄像头的实时拍摄,直接渲染出CGI(计算机生成图像)特效,就跟打开美颜相机拍摄一样。在具体操作中,你要先上传一个3D模型(比如图中的机器人)。Simulon会将这个模型放置到你拍摄的现实世界中,并使用准确的照明、阴影和反射效果来渲染它们。整个过程不需要相机解算、HDR
 背景与前景控制更加精细,编辑更加快捷:BEVControl的两阶段方法Sep 07, 2023 pm 11:21 PM
背景与前景控制更加精细,编辑更加快捷:BEVControl的两阶段方法Sep 07, 2023 pm 11:21 PM本文将介绍一种通过BEVSketch布局来精确生成多视角街景图片的方法在自动驾驶领域,图像合成被广泛应用于提升下游感知任务的性能在计算机视觉领域,提升感知模型性能的一个长期存在的研究难题是通过合成图像来实现。在以视觉为中心的自动驾驶系统中,使用多视角摄像头,这个问题变得更加突出,因为有些长尾场景是永远无法收集到的根据图1(a)所示,现有的生成方法将语义分割风格的BEV结构输入生成网络,并输出合理的多视角图像。在仅根据场景级指标进行评估时,现有方法似乎能合成照片般逼真的街景图像。然而,一旦放大,我


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。
ホットトピック
 7442
7442 15137152
15137152