
ホームページ >テクノロジー周辺機器 >AI >ECCV2024 | ハーバード大学チームがクロスドメイン医療画像のセグメンテーションと分類の公平性を実現する FairDomain を開発
ECCV2024 | ハーバード大学チームがクロスドメイン医療画像のセグメンテーションと分類の公平性を実現する FairDomain を開発

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-08-05 20:04:361351ブラウズ

編集者 | ScienceAI
人工知能 (AI)、特に医療 AI の分野では、公正な医療結果を確保するために公平性の問題に対処することが重要です。
最近、公平性を高める取り組みにより、新しい手法とデータセットが導入されています。しかし、クリニックでは患者の診断にさまざまな画像技術(たとえば、さまざまな網膜画像モダリティ)を使用することが多いにもかかわらず、公平性の問題はドメイン転送の文脈ではほとんど検討されていません。
この論文は、ドメイン転送におけるアルゴリズムの公平性に関する最初の体系的な研究である FairDomain を提案します。私たちは、医療画像のセグメンテーションと分類のための最先端のドメイン適応 (DA) アルゴリズムとドメイン一般化 (DG) アルゴリズムをテストします。タスク。異なるドメイン間でバイアスがどのように伝達されるかを理解するように設計されています。
また、人口統計的属性の性別に基づいて特徴の重要性を調整するセルフ アテンション メカニズムを使用して、さまざまな DA および DG アルゴリズムの公平性を向上させる、新しいプラグ アンド プレイのフェア アイデンティティ アテンション (FIA) モジュールも提案します。
さらに、公平性に焦点を当てた最初のドメインシフトデータセットを編集して公開しました。これには、ドメインシフトシナリオの公平性を厳密に評価するための、同じ患者集団の 2 つのペアの画像モダリティの医療セグメンテーションと分類タスクが含まれています。ソース ドメインとターゲット ドメイン間の人口分布の違いによる交絡効果を除外すると、ドメイン転送モデルのパフォーマンスをより明確に定量化できるようになります。
私たちの広範な評価では、提案された FIA がすべてのドメイン転送タスク (つまり、DA と DG) におけるさまざまな人口統計特性の下でモデルの公平性とパフォーマンスを大幅に向上させ、セグメンテーション タスクと分類タスクの両方で最先端の手法を上回るパフォーマンスを示していることが示されています。方法です。
ここで ECCV 2024 最終草案の成果を共有してください「FairDomain: クロスドメイン医療画像のセグメンテーションと分類における公平性の達成」

記事のアドレス: https://arxiv.org/abs/2407.08813
コードアドレス: https://github.com/Harvard-Ophysical-AI-Lab/FairDomain
データセットウェブサイト: https://ophai.hms.harvard.edu/datasets/harvard-fairdomain20k
データセットのダウンロード リンク: https://drive.google.com/drive/folders/1huH93JVeXMj9rK6p1OZRub868vv0UK0O?usp=sharing
ハーバード眼科-AI-Lab は、高品質の公平性データ セットとより多くの公平性データ セットを提供することに尽力しています。研究室のデータセットのホームページをクリックしてください: https://ophai.hms.harvard.edu/datasets/
背景
近年、医療画像分野における深層学習の進歩により、分類と分析が大幅に改善されました。セグメンテーションタスクの効果。これらのテクノロジーは、診断の精度を向上させ、治療計画を簡素化し、最終的には患者の健康を改善するのに役立ちます。ただし、ディープラーニングモデルをさまざまな医療現場に導入する際の重要な課題は、アルゴリズムに固有のバイアスと特定の人口統計グループに対する差別であり、医療の診断と治療の公平性を損なう可能性があります。
最近の研究では、医療画像処理におけるアルゴリズムのバイアスの問題を解決し始め、深層学習モデルの公平性を高めるためのいくつかの方法が開発されました。ただし、これらの方法では通常、トレーニング段階とテスト段階でデータ分布が変化しないことを前提としていますが、実際の医療シナリオでは当てはまらないことがよくあります。
たとえば、さまざまなプライマリケアクリニックや専門病院は、診断のためにさまざまなイメージング技術(たとえば、さまざまな網膜イメージングモダリティ)に依存している可能性があり、その結果、大幅なドメインシフトが発生し、それがモデルのパフォーマンスと公平性に影響を及ぼします。
したがって、実際の展開では、ドメインの転送を考慮し、クロスドメインのシナリオで公平性を維持できるモデルを学習する必要があります。
ドメイン適応とドメイン一般化は文献で広く研究されていますが、これらの研究は主にモデルの精度を向上させることに焦点を当てており、モデルがさまざまな集団グループにわたって公平な予測を提供することを保証するという重要性が無視されています。特に医療分野では、意思決定モデルが人間の健康と安全に直接影響するため、領域を越えた公平性を検討することは非常に重要です。
しかし、クロスドメインの公平性の問題を調査し始めた研究はほんのわずかであり、これらの研究には系統的かつ包括的な調査が欠けており、通常はドメインの適応または一般化のみに焦点を当てており、両方に焦点を当てていることはほとんどありません。さらに、既存の研究は主に医療分類問題を解決しており、ドメイン転送下での同様に重要な医療セグメント化タスクは無視されています。
これらの問題を解決するために、ドメイン転送下でのアルゴリズムの公平性を系統的に調査する医療画像分野初の研究である FairDomain を紹介します。
私たちは、複数の最先端のドメイン適応および一般化アルゴリズムを使用して広範な実験を実施し、さまざまな人口統計的属性の下でその精度と公平性を評価し、公平性がさまざまなドメイン間でどのように移行するかを理解します。
私たちの観察により、ソースドメインとターゲットドメイン間のグループパフォーマンスの違いは、さまざまな医療分類タスクとセグメンテーションタスクで大幅に悪化することが明らかになりました。これは、この差し迫った問題に効果的に対処するには、公平性を重視したアルゴリズムを設計する必要があることを示しています。

既存のバイアス緩和の取り組みの欠点を補うために、さまざまなドメイン適応および一般化戦略にシームレスに統合されるように設計された、新しい汎用性の高い Fair Identity Attendance (FIA) メカニズムを導入します。機能の重要性は、派生したセルフ アテンションと調整されます。公平性を促進するために、人口統計上の属性 (人種グループなど) から判断します。
FairDomain ベンチマークの開発における主な課題は、さまざまなイメージング技術によって引き起こされることが多い、現実世界の医療ドメインにおけるドメインシフトを真に反映する医療画像データセットが欠如していることです。
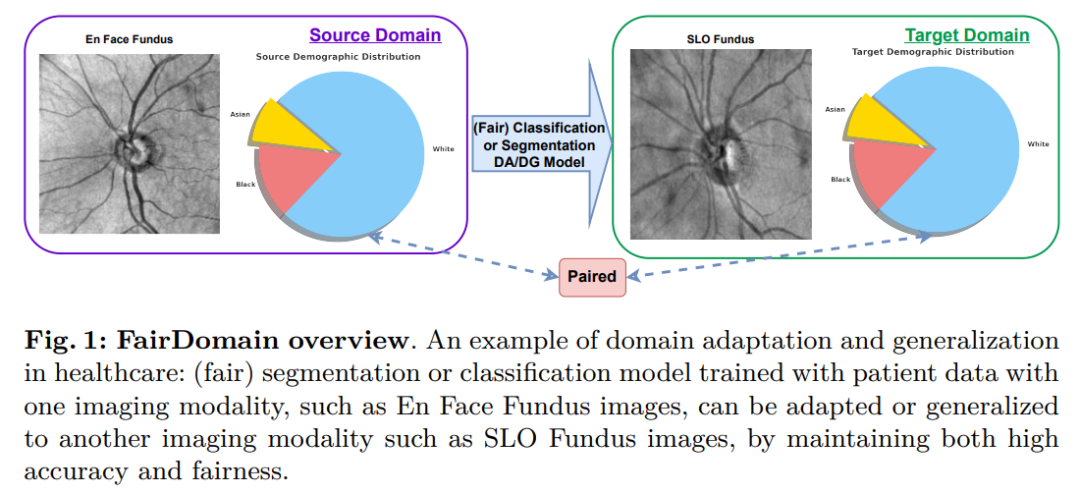
既存の医療データセットでは、ソース ドメインとターゲット ドメイン間の患者人口統計の違いにより交絡が生じ、観察されたアルゴリズムの偏りが人口統計分布の変化によるものなのか、それとも固有のドメインのシフトによるものなのかを区別することが困難になります。この問題を解決するために、特にドメイン転送シナリオのアルゴリズム バイアスを分析するために、2 つの異なるイメージング モダリティ (En 顔画像と SLO 眼底画像) を使用して、同じ患者コホートのペアの網膜眼底画像で構成される独自のデータセットを厳選しました。
私たちの貢献の概要:
1. 医療画像におけるドメイン転送におけるアルゴリズムの公平性が初めて体系的に調査されました。
3. 公平性研究、特にドメイン移管下での公平性の問題を研究するために、大規模な医療セグメンテーションと分類のペアデータセットを作成しました。
データ収集と品質管理被験者は、2010年から2021年の間にハーバード大学医学部の大規模な学術眼科病院から選ばれました。この研究では、医療セグメンテーション タスクと医療分類タスクという 2 つのクロスドメイン タスクを検討します。医療セグメンテーション タスクの場合、データには次の 5 つのタイプが含まれます:
1. SLO 眼底画像スキャン
好みの言語: 英語が92.4%、スペイン語が1.5%、その他の言語が1%、不明が5.1%を占めました
配偶者の有無: 既婚またはパートナーがいる 57.7 %、独身 27.1%、離婚 6.8%、法的別居 0.8%、死別 5.2%、不明 2.4%。 同様に、医療分類データセットには、平均年齢 60.9 ± 16.1 歳の 10,000 人の被験者の 10,000 サンプルが含まれています。データを 8000 サンプルのトレーニング セットと 2000 サンプルのテスト セットに分割します。人口分布は次のとおりです: 性別: 72.5% 女性、27.5% 男性; 人種: 8.7% アジア人、14.5% 黒人、76.8% 白人; 民族性: 96.0% 非ヒスパニック、ヒスパニック系が 4.0% ;希望する言語: 92.6% 英語、1.7% スペイン語、3.6% 他の言語、2.1% 不明;
婚姻状況: 58.5% 既婚またはパートナー、26.1% 独身、6.9% 離婚、法的別居が 0.8%、死別が占める1.9%、不明が5.8%となった。
これらの詳細な人口統計情報は、クロスドメイン タスクの公平性に関する詳細な研究のための豊富なデータ基盤を提供します。
クロスドメイン AI モデルの公平性を向上させるために使用される手法 Fair Identity Attendant (FIA)

問題定義
Domain Adaptation (DA) と Domain Generalization (DG)機械学習モデルの開発に使用され、モデルをある特定のドメインから別のドメインに適用するときに発生する可能性のある変動に対処するように設計されています。
医療画像の分野では、DA および DG 技術は、さまざまな医療機関、画像デバイス、患者集団間のばらつきを確実に処理できるモデルを作成するために重要です。このペーパーは、ドメイン移転のコンテキストにおける公平性のダイナミクスを調査し、新しいドメインに適応または一般化する際にモデルが公平性と信頼性を維持できるようにする方法を開発することを目的としています。
モデルがソースドメインからターゲットドメインに転送されるときに一般的な公平性の低下を軽減するメソッド関数 f を開発することを目指しています。このような悪化は主に、ドメインのシフトによってデータセット内の既存のバイアス、特に性別、人種、民族などの人口統計的属性に関連するバイアスが増幅される可能性があるためです。この問題に対処するために、人口統計的属性を考慮しながら、セグメンテーションや分類などの下流タスクに関連する画像の特徴を特定して活用することを目的とした、アテンションメカニズムベースのアプローチを提案します。
図 3 は、提案された公平なアイデンティティ アテンション モジュールのアーキテクチャを示しています。このモジュールは、まず、入力画像と入力統計属性ラベルを処理することにより、入力画像埋め込み E_i と属性埋め込み E_a を取得します。これらの埋め込みは、位置埋め込み E_p に追加されます。詳細な計算式は次のとおりです。
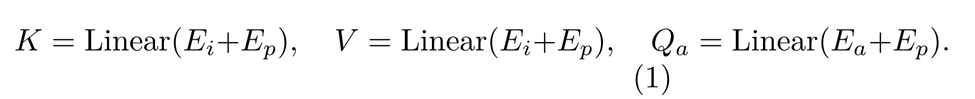 クエリとキーのドット積を計算することで、現在の特徴属性に関連する類似度行列を抽出します。次に、この行列と値のドット積を使用して、各フィーチャ属性の下流タスクで重要なフィーチャを抽出します。このプロセスは次の式で表されます:
クエリとキーのドット積を計算することで、現在の特徴属性に関連する類似度行列を抽出します。次に、この行列と値のドット積を使用して、各フィーチャ属性の下流タスクで重要なフィーチャを抽出します。このプロセスは次の式で表されます:
 ここで、D はソフトマックス関数で過度に大きな値を避けるためのスケーリング係数です。
ここで、D はソフトマックス関数で過度に大きな値を避けるためのスケーリング係数です。
その後、入力情報の整合性を維持するために、残留接続によって E_i が注目の出力に追加されます。最後に、正規化層と多層パーセプトロン (MLP) 層によってさらに特徴が抽出されます。これら 2 つの層の出力に対する別の残差演算の後、フェア アテンション モジュールの最終出力が得られます。
フェア アイデンティティ アテンション メカニズムは、公平性の問題を解決しながらモデルのパフォーマンスを向上させるように設計された強力で多用途のツールです。性別、人種、民族などの人口統計的属性を明示的に考慮することで、学習された表現がデータに存在するバイアスを不注意に増幅することがなくなります。
そのアーキテクチャにより、プラグイン コンポーネントとして既存のネットワークにシームレスに統合できます。このモジュール式の性質により、研究者や実践者は、基盤となるアーキテクチャに大規模な変更を加えることなく、公正なアイデンティティへの注意をモデルに統合することができます。
したがって、公平なアイデンティティ アテンション モジュールは、セグメンテーションおよび分類タスクにおけるモデルの精度と公平性を向上させるだけでなく、データセット内のさまざまなグループの公平な扱いを促進することにより、信頼できる AI の実装を促進します。
実験ドメイン転送におけるアルゴリズムの公平性
私たちの実験では、まず、特にカップとプレートのセグメンテーションタスクに焦点を当てて、ドメイン転送のコンテキストにおける公平性を分析します。カップ対ディスクのセグメンテーションとは、眼底画像内の眼杯とディスクの輪郭を正確に描写するプロセスを指します。これは、緑内障の進行とリスクを評価する際の重要なパラメーターであるカップ対ディスク比 (CDR) を計算するために重要です。
このタスクは、医療画像処理の分野、特に緑内障などの眼疾患を診断および管理する場合に特に重要です。眼杯は視神経乳頭の重要な部分領域であるため、セグメンテーションタスクをカップアンドリム(視神経乳頭と視神経乳頭縁の間の組織領域)セグメンテーションとして再構築し、眼杯と視神経乳頭の間の大きな重複によるエラーを回避します。光ディスクのパフォーマンスに歪みが生じます。
私たちは、光干渉断層計 (OCT) から取得した正面眼底画像と走査レーザー眼底画像 (SLO) という 2 つの異なる領域で、3 つの異なる人口統計 (性別、人種、民族) にわたる公平性のパフォーマンスを調査しました。
その後の実験では、ソース ドメインとして En face 眼底画像を選択し、ターゲット ドメインとして SLO 眼底画像を選択しました。その理由は、SLO 眼底画像と比較して、対面眼底画像は専門の眼科医療現場でより一般的であるため、データの可用性が大幅に高いためです。
因此,我们选择将 En face 眼底图像作为源域,将 SLO 眼底图像作为目标域。对于分类任务,我们使用这两个域的眼底图像作为源域和目标域,分类为正常和青光眼两类。
评估指标
我们使用 Dice 和IoU指标来评估分割性能,使用受AUC来评估分类任务的性能。这些传统的分割和分类指标虽然能反映模型的表现,但并未内在地考虑到各人口统计群体之间的公平性。
为了解决医学影像中模型性能和公平性之间的潜在权衡,我们使用新颖的公平性缩放性能(ESP)指标来评估分割和分类任务的性能和公平性。
令 ∈{Dice,IoU,AUC,...}M in {Dice,IoU, AUC, . . .}M∈{Dice,IoU,AUC,...} 表示适用于分割或分类的通用性能指标。传统评估通常忽略人口统计身份属性,从而错过了关键的公平性评估。为了将公平性纳入其中,我们首先计算性能差异Δ,定义为各人口统计群体的指标与总体性能的集体偏差,其公式如下:

当不同群体的性能公平性达到时,Δ接近零,反映出最小的差异。然后,ESP 指标可以公式化如下:
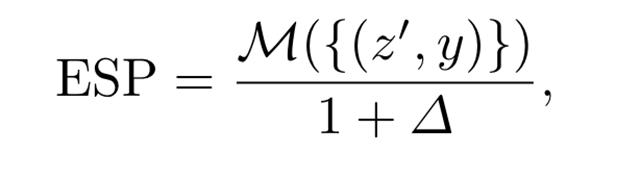
该统一指标有助于全面评估深度学习模型,强调不仅要关注其准确性(如通过 Dice、IoU 和 AUC 等测量),还要关注其在不同人口群体间的公平性。
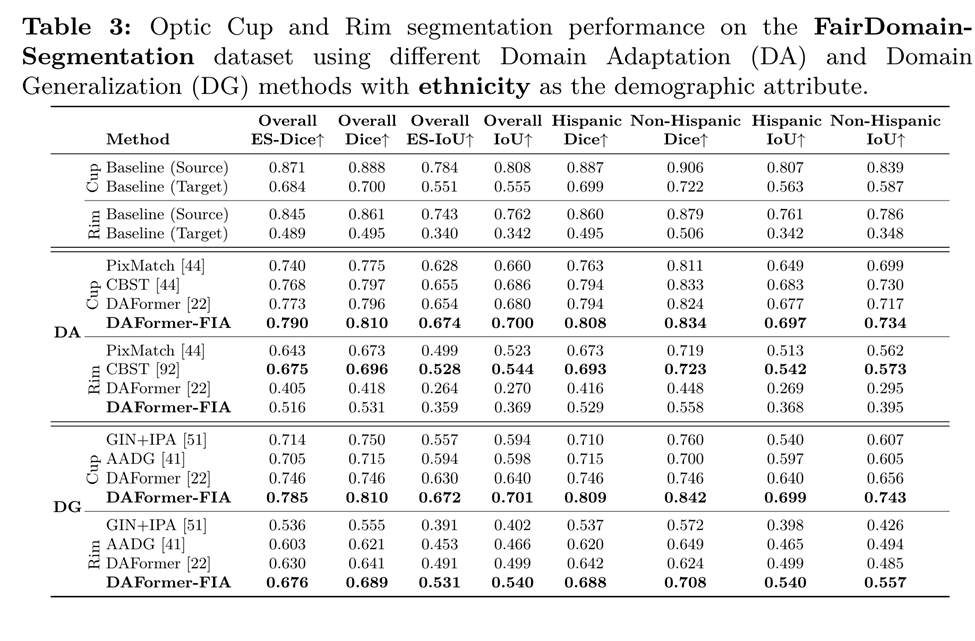
Cup-Rim Segmentation Results under Domain Shifts


Glaucoma Classification Results under Domain Shifts
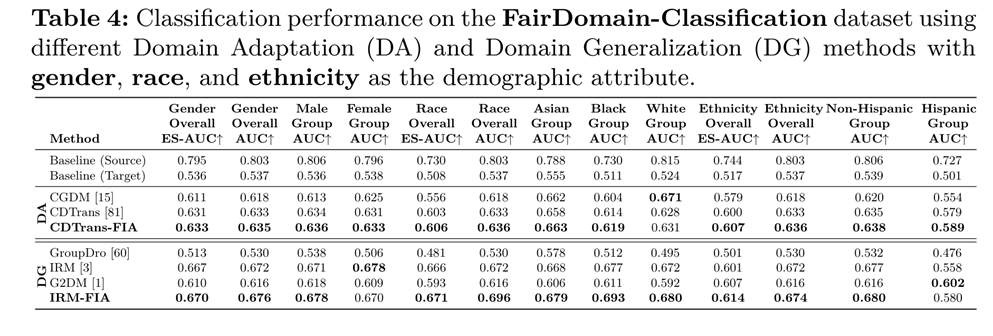
总结
本文聚焦于人工智能(尤其是医疗AI)中的公平性问题,这是实现公平医疗的关键。
由于诊所可能使用不同的成像技术,域转移中的公平性问题仍然基本未被探索。我们的工作引入了FairDomain,这是一个关于域转移任务中算法公平性的全面研究,包括域适应和泛化,涉及医学分割和分类两个常见任务。
我们提出了一种新颖的即插即用的Fair Identity Attention(FIA)模块,通过注意力机制根据人口统计属性学习特征相关性,从而在域转移任务中增强公平性。
我们还创建了第一个以公平性为中心的跨域数据集,其中包含同一患者队列的两种配对的成像图片,以排除人口统计分布变化对模型公平性的混淆影响,从而精确评估域转移对模型公平性的影响。
我们的公平身份注意力模型可以改善现有的域适应和泛化方法,使模型性能在考虑公平性的情况下得到提升。
注:封面图由AI生成。
以上がECCV2024 | ハーバード大学チームがクロスドメイン医療画像のセグメンテーションと分類の公平性を実現する FairDomain を開発の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。