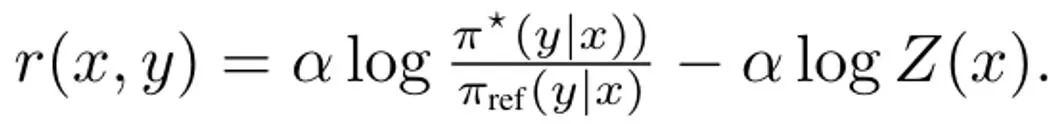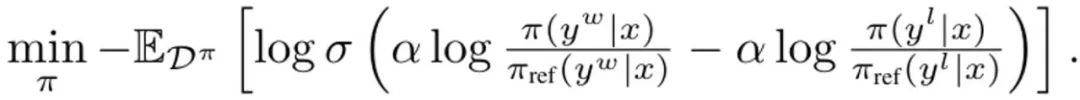子供を育てるとき、人々はいつの時代も、模範を示すという重要な方法について話してきました。つまり、単に子供たちに何をすべきかを教えるのではなく、子供たちが模倣し、学ぶべき手本となるようにしましょう。大規模言語モデル (LLM) をトレーニングする場合、モデルにデモンストレーションを行うというこの方法も使用できる場合があります。
最近、スタンフォード大学のYang Diyi氏のチームは、少数のデモンストレーション(ユーザーが提供する望ましい動作の例)を通じてLLMを特定の設定に調整できる新しいフレームワークDITTOを提案しました。これらの例は、ユーザーの既存の対話ログから、または LLM の出力を直接編集することによって取得できます。これにより、モデルはさまざまなユーザーやタスクのユーザー設定を効率的に理解し、調整することができます。 
- 論文のタイトル: Show, Don't Tell: Aligning Language Models with Demonstrated Feedback
- 論文のアドレス: https://arxiv.org/pdf/2406.00888
同様にできますに基づく 少数のデモ (10 未満) は、ユーザーが元の LLM および以前の反復の出力よりも LLM を好むことを暗黙のうちに認識することにより、多数の好みの比較を含むデータ セットを自動的に作成します (スキャフォールディングと呼ばれるプロセス)。 。次に、デモンストレーションとモデルの出力がデータ ペアに結合されて、強化されたデータ セットが取得されます。その後、DPO などの調整アルゴリズムを使用して言語モデルを更新できます。 さらに、チームは、DITTO がオンラインの模倣学習アルゴリズムとして見なすことができることも発見しました。LLM からサンプリングされたデータは、専門家の行動を区別するために使用されます。この観点から、チームは DITTO が外挿によって専門家以上のパフォーマンスを達成できることを実証しました。 チームは実験を通じてDITTOの効果も検証しました。 LLM を調整するには、以前の方法では多くの場合、数千の比較データのペアを使用する必要がありましたが、DITTO はほんの数回のデモンストレーションでモデルの動作を変更できます。この低コストで迅速な適応は、主にチームの核となる洞察によって可能になりました。オンライン比較データはデモンストレーションを通じて簡単に入手できます。
言語モデルは、プロンプト x と完了結果 y の分布をもたらすポリシー π(y|x) として見ることができます。 RLHF の目標は、プロンプト完了結果ペア (x, y) の品質を評価する報酬関数 r (x, y) を最大化するように LLM をトレーニングすることです。通常、更新されたモデルが基本言語モデル (π_ref) から大きく逸脱しないように、KL 発散も追加されます。全体として、RLHF メソッドの最適化目標は次のとおりです:
これは、αによって規制されるKL制約の影響を受けるプロンプト分布pの期待報酬を最大化するためです。通常、最適化目標では、{(x, y^w, y^l )} の形式の比較データ セットを使用します。ここで、「勝った」完了結果 y^w は、「負けた」完了結果 y ^l よりも優れています。 y^w ⪰ y^l として記録されます。 さらに、ここでは小規模なエキスパート デモンストレーション データ セットを D_E としてマークし、これらのデモンストレーションは予測報酬を最大化できるエキスパート ポリシー π_E によって生成されたと仮定します。 DITTO は、言語モデルの出力と専門家のデモンストレーションを直接使用して、比較データを生成できます。つまり、合成データの生成パラダイムとは異なり、DITTO では、特定のタスクですでに良好なパフォーマンスを発揮するモデルを必要としません。 DITTO の重要な洞察は、言語モデル自体を専門家のデモンストレーションと組み合わせることで、調整のための比較データセットを生成でき、これにより大量のペアごとの嗜好データを収集する必要がなくなるということです。 。これにより、専門家のデモンストレーションが肯定的な例となる対照的な目標が生まれます。 比較を生成します。エキスパートポリシーから完了結果 y^E 〜 π_E (・|x) をサンプリングするとします。その場合、他の政策 π からサンプリングされたサンプルに対応する報酬は、π_E からサンプリングされたサンプルの報酬以下であると考えることができます。この観察に基づいて、チームは比較データ (x, y^E, y^π ) (y^E ⪰ y^π) を構築しました。このような比較データは個々のサンプルではなく戦略から得られますが、以前の研究ではこのアプローチの有効性が実証されています。 DITTO の自然なアプローチは、このデータセットとすぐに利用できる RLHF アルゴリズムを使用して (1) を最適化することです。そうすることで、前者のみを実行する標準的な微調整方法とは異なり、現在のモデル サンプルの確率を低減しながら、専門家の応答の確率が向上します。重要なのは、π からのサンプルを使用することで、少数のデモンストレーションで無制限の嗜好データ セットを構築できることです。しかし、チームは、学習プロセスの時間的側面を考慮することで、さらに効果的に実行できることを発見しました。 比較からランキングまで。専門家からの比較データと単一のポリシー π のみを使用するだけでは、良好なパフォーマンスを得るには十分ではない可能性があります。そうすることは、特定の π の可能性を減らすだけであり、過剰適合の問題が発生します。これは、データが少ない場合にも SFT を悩ませます。研究チームは、強化学習におけるリプレイと同様に、RLHF 中に時間の経過とともに学習されたすべてのポリシーによって生成されたデータを考慮することも可能であると提案しています。 反復の最初のラウンドの初期戦略を π_0 とします。データセット D_0 は、この戦略をサンプリングすることによって取得されます。 RLHF の比較データセットはこれに基づいて生成でき、D_E ⪰ D_0 と表すことができます。これらの導出された比較データを使用して、π_0 を更新して π_1 を得ることができます。定義上、 も成り立ちます。その後、引き続き π_1 を使用して比較データを生成し、D_E ⪰ D_1 を生成します。このプロセスを継続し、これまでのすべての戦略を使用して、ますます多様化する比較データを継続的に生成します。チームはこれらの比較を「リプレイ比較」と呼んでいます。 この方法は理論的には理にかなっていますが、D_E が小さい場合、過学習が発生する可能性があります。ただし、反復ごとにポリシーが改善されると想定される場合は、トレーニング中にポリシー間の比較を考慮することもできます。専門家との比較とは異なり、各反復後に戦略がより優れていることを保証することはできませんが、チームは全体的なモデルが各反復後にも改善されていることがわかりました。これは、報酬モデリングと (1) 凸型の両方が原因である可能性があります。このようにして、以下のランキングに従って比較データをサンプリングすることができます:
これらの「モデル間」および「リプレイ」比較データを追加することによって、得られる効果は、初期のサンプル ( D_1 のサンプル) は、(D_t のような) 後のサンプルよりも高くなります。これにより、暗黙的な報酬の画像が滑らかになります。実際の実装では、チームのアプローチは、専門家との比較データを使用するだけでなく、これらのモデル間のいくつかの比較データを集約することです。 実用的なアルゴリズム。実際には、DITTO アルゴリズムは、アルゴリズム 1 に示すように、3 つの単純なコンポーネントで構成される反復プロセスです。
まず、エキスパート デモ セットで教師あり微調整を実行し、限られた数のグラデーション ステップを実行します。これを初期ポリシー π_0 とします。第 2 ステップ、サンプル比較データ: トレーニング中に、D_E の N 個のデモンストレーションごとに、π_t から M 個の完了結果をサンプリングすることによって新しいデータセット D_t が構築され、それらは次に従ってランキングに追加されます。戦略(2)。式 (2) から比較データをサンプリングする場合、各バッチ B は 70% の「オンライン」比較データ D_E ⪰ D_t と 20% の「リプレイ」比較データ D_E ⪰ D_{i
ここで、σ は次のロジスティック関数です。ブラッドリー・テリー優先モデル。各更新中、初期化から大きく逸脱することを避けるために、SFT 戦略からの参照モデルは更新されません。 DITTO は、専門家のデモンストレーションとオンライン データの組み合わせを使用して、報酬関数とポリシーを同時に学習するオンライン模倣学習の観点から導出できます。具体的には、戦略プレイヤーは期待される報酬? (π, r) を最大化し、一方、報酬プレイヤーはオンライン データセット D^π 上の損失 min_r L (D^π, r) を最小化します。 (1) のポリシー目標と標準報酬モデリング損失を使用して、最適化問題をインスタンス化します。
同上、(3) を単純化するための最初のステップは、内部ポリシーの最大の問題を解決することです。幸いなことに、チームは以前の研究に基づいて、政策目標 ?_KL には Z (x) が正規化分布の分配関数である形式の閉形式の解があることを発見しました。特に、これによりポリシーと報酬関数の間に全単射関係が作成され、内部最適化を排除するために使用できます。この解を整理すると、報酬関数は次のように書くことができます: さらに、以前の研究では、この再パラメータ化が任意の報酬関数を表すことができることが示されています。したがって、式 (3) に代入することで、変数 r を π に変更することができ、それによって DITTO の目的を取得できます。 DPO と同様に、報酬関数はここでも暗黙的に推定されることに注意してください。 DPO との違いは、DITTO がオンライン設定データ セット D^π に依存していることです。 SFT を単に使用するよりも DITTO の方が優れているのはなぜですか? DITTO のパフォーマンスが優れている理由の 1 つは、比較データを生成することで SFT よりもはるかに多くのデータを使用するためです。もう 1 つの理由は、オンラインの模倣学習方法が発表者よりも優れている場合があるのに対し、SFT はデモンストレーションを模倣することしかできないことです。 チームはDITTOの有効性を証明するために実証研究も実施しました。実験の具体的な設定については元の論文を参照してください。ここでは実験結果のみに焦点を当てます。 静的ベンチマークの評価にはGPT-4を使用し、結果を表1に示します。
平均而言,DITTO 胜过其它所有方法:在 CMCC 上平均胜率为 71.67%,在 CCAT50 上平均胜率为 82.50%;总体平均胜率为 77.09%。在 CCAT50 上,对于所有作者,DITTO 仅在其中一个上没有取得全面优胜。在 CMCC 上,对于所有作者,DITTO 全面胜过其中一半基准,之后是 few-shot prompting 赢得 3 成。尽管 SFT 的表现很不错,但 DITTO 相较于其的平均胜率提升了 11.7%。总体而言,用户研究的结果与在静态基准上的结果一致。DITTO 在对齐演示的偏好方面优于对比方法,如表 2 所示:其中 DITTO (72.1% 胜率) > SFT (60.1%) > few-shot (48.1%) > self-prompt (44.2%) > zero-shot (25.0%)。
在使用 DITTO 之前,用户必须考虑一些前提条件,从他们有多少演示到必须从语言模型采样多少负例。该团队探索了这些决定的影响,并重点关注了 CMCC,因为其覆盖的任务超过 CCAT。此外,他们还分析了演示与成对反馈的样本效率。如图 2(左)所示,增加 DITTO 的迭代次数通常可以提升性能。
可以看到,当迭代次数从 1 次提升到 4 次,GPT-4 评估的胜率会有 31.5% 的提升。这样的提升是非单调的 —— 在第 2 次迭代时,性能稍有降低(-3.4%)。这是因为早期的迭代可能会得到噪声更大的样本,从而降低性能。另一方面,如图 2(中)所示,增加负例数量会使 DITTO 性能单调提升。此外,随着采样的负例增多,DITTO 性能的方差会下降。
另外,如表 3 所示,对 DITTO 的消融研究发现,去掉其任何组件都会导致性能下降。比如如果放弃在线方式的迭代式采样,相比于使用 DITTO,胜率会从 70.1% 降至 57.3%。而如果在在线过程中持续更新 π_ref,则会导致性能大幅下降:从 70.1% 降至 45.8%。该团队猜想其原因是:更新 π_ref 可能会导致过拟合。最后,我们也能从表 3 中看到重放和策略间比较数据的重要性。DITTO 的一大关键优势是其样本效率。该团队对此进行了评估,结果见图 2(右);同样,这里报告的是归一化后的胜率。首先可以看到,DITTO 的胜率一开始会快速提升。在演示数量从 1 变成 3 时,每次增加都会让归一化性能大幅提升(0% → 5% → 11.9%)。但是,当演示数量进一步增加时,收益增幅降低了(从 4 增至 7 时为 11.9% → 15.39%),这说明随着演示数量增加,DITTO 的性能会饱和。另外,该团队猜想,不止演示数量会影响 DITTO 的性能,演示质量也会,但这还留待未来研究。DITTO 的一个核心假设是样本效率源自于演示。理论上讲,如果用户心中有一套完美的演示集合,通过标注许多成对的偏好数据也能实现类似的效果。该团队做了一个近似实验,使用从指令遵从 Mistral 7B 采样的输出,让一位提供了用户研究的演示的作者也标注了 500 对偏好数据。总之,他们构建了一个成对的偏好数据集 D_pref = {(x, y^i , y^j )},其中 y^i ≻ y^j。然后他们计算了采样自两个模型的 20 对结果的胜率情况 —— 其一是使用 DITTO 在 4 个演示上训练的,其二是仅使用 DPO 在 {0...500} 偏好数据对训练的。
当仅从 π_ref 采样成对偏好数据时,可以观察到生成的数据对位于演示的分布外 —— 成对的偏好不涉及用户演示的行为(图 3 中 Base policy 的结果,蓝色)。即使当他们使用用户演示对 π_ref 进行微调时,仍然需要超过 500 对偏好数据才能比肩 DITTO 的性能(图 3 中 Demo-finetuned policy 的结果,橙色)。以上がYang Diyi のチームが提案した DITTO は、大規模なモデルを数回デモンストレーションするだけで非常に効率的です。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





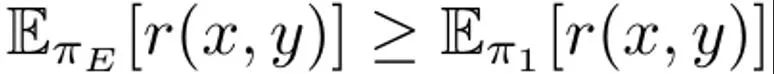 も成り立ちます。その後、引き続き π_1 を使用して比較データを生成し、D_E ⪰ D_1 を生成します。このプロセスを継続し、これまでのすべての戦略を使用して、ますます多様化する比較データを継続的に生成します。チームはこれらの比較を「リプレイ比較」と呼んでいます。
も成り立ちます。その後、引き続き π_1 を使用して比較データを生成し、D_E ⪰ D_1 を生成します。このプロセスを継続し、これまでのすべての戦略を使用して、ますます多様化する比較データを継続的に生成します。チームはこれらの比較を「リプレイ比較」と呼んでいます。