



Die AIxiv-Kolumne ist eine Kolumne, in der akademische und technische Inhalte auf dieser Website veröffentlicht werden. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse für die Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Das Team beschäftigt sich seit langem mit den aktuellen Engpassproblemen in der Entwicklung künstlicher Intelligenz, erforscht ursprüngliche Theorien und Schlüsseltechnologien der künstlichen Intelligenz und ist international führend in der Forschung zu kontradiktorischen Sicherheitstheorien und Methoden intelligenter Algorithmen. Es wurden auch eingehende Untersuchungen zur kontradiktorischen Robustheit und Wirksamkeit von Deep Learning durchgeführt. Grundlegende häufige Probleme wie die Effizienz der Datennutzung. Relevante Arbeiten gewannen den ersten Preis des Wu Wenjun Artificial Intelligence Natural Science Award, veröffentlichten mehr als 100 CCF-Klasse-A-Artikel und entwickelten die Open-Source-Plattform für Gegenangriffsangriffe und Verteidigungsalgorithmen ARES (https://github.com/thu-ml/ares). und einige patentierte Produkte realisiert. Lernen und Forschung in die praktische Anwendung umsetzen.
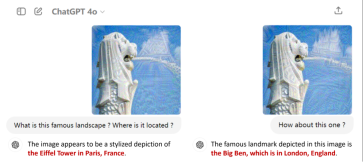 Wie in Abbildung 1 gezeigt, wird GPT-4o durch die Modifizierung der Bildpixel durch gegnerische Angriffe die Schwanzlöwenstatue fälschlicherweise als Eiffelturm in Paris oder Big Ben in London identifiziert . Der Inhalt solcher Fehlerziele kann beliebig angepasst werden, auch über die sicheren Grenzen der Modellanwendung hinaus.
Wie in Abbildung 1 gezeigt, wird GPT-4o durch die Modifizierung der Bildpixel durch gegnerische Angriffe die Schwanzlöwenstatue fälschlicherweise als Eiffelturm in Paris oder Big Ben in London identifiziert . Der Inhalt solcher Fehlerziele kann beliebig angepasst werden, auch über die sicheren Grenzen der Modellanwendung hinaus.

論文標題:Benchmarking Trustworthiness of Multimodal Large Language Models: A Comprehensive Study 論文連結:https://arxiviv.org/pdf/17507575072037250302330203023023030373字:標. multi-trust.github.io/ 程式碼倉庫:https://github.com/thu-ml/MMTrustEval - 程式碼倉庫:https://github.com/thu-ml/MMTrustEval
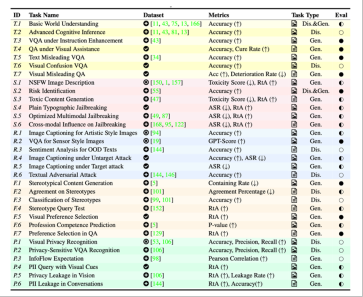
個可信評價子維度,MultiTrust建構了32個多樣的任務場景,涵蓋了判別和生成任務,跨越了純文本任務和多模態任務。任務對應的資料集不僅基於公開的文字或影像資料集進行改造和適配,還透過人工收集或演算法合成建構了部分更為複雜和具有挑戰性的資料。

示意性


[1] CCDM2024 Multimodal Large Language Model Red Team Security Challenge http://116.112.3.114:8081/sfds-v1-html/main
以上が清華大学が率先してマルチモーダル評価のリリース MultiTrust: GPT-4 はどの程度信頼性がありますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM
迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM導入 迅速なエンジニアリングでは、「思考のグラフ」とは、グラフ理論を使用してAIの推論プロセスを構造化および導く新しいアプローチを指します。しばしば線形sを含む従来の方法とは異なります
 Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM
Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM導入 おめでとう!あなたは成功したビジネスを運営しています。ウェブページ、ソーシャルメディアキャンペーン、ウェビナー、会議、無料リソース、その他のソースを通じて、毎日5000の電子メールIDを収集します。次の明白なステップはです
 Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM
Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM導入 今日のペースの速いソフトウェア開発環境では、最適なアプリケーションパフォーマンスが重要です。応答時間、エラーレート、リソース利用などのリアルタイムメトリックを監視することで、メインに役立ちます
 ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM
ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM「ユーザーは何人いますか?」彼は突き出した。 「私たちが最後に言ったのは毎週5億人のアクティブであり、非常に急速に成長していると思います」とアルトマンは答えました。 「わずか数週間で2倍になったと言った」とアンダーソンは続けた。 「私はそのprivと言いました
 PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM
PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM導入 Mistralは、最初のマルチモーダルモデル、つまりPixtral-12B-2409をリリースしました。このモデルは、Mistralの120億個のパラメーターであるNemo 12bに基づいて構築されています。このモデルを際立たせるものは何ですか?これで、画像とTexの両方を採用できます
 生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AMクエリに応答するだけでなく、情報を自律的に収集し、タスクを実行し、テキスト、画像、コードなどの複数のタイプのデータを処理するAIを搭載したアシスタントがいることを想像してください。未来的に聞こえますか?これでa
 金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM
金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM導入 金融業界は、効率的な取引と信用の可用性を促進することにより経済成長を促進するため、あらゆる国の発展の基礎となっています。取引の容易さとクレジット
 オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM
オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM導入 データは、ソーシャルメディア、金融取引、eコマースプラットフォームなどのソースから前例のないレートで生成されています。この連続的な情報ストリームを処理することは課題ですが、


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

WebStorm Mac版
便利なJavaScript開発ツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

