
ホームページ >テクノロジー周辺機器 >AI >GPT-4o を打ち破るオープンソース モデルを作成するにはどうすればよいでしょうか? Llama 3.1 405B については、この論文にメタが書かれています
GPT-4o を打ち破るオープンソース モデルを作成するにはどうすればよいでしょうか? Llama 3.1 405B については、この論文にメタが書かれています

- PHPzオリジナル
- 2024-07-24 18:42:031062ブラウズ
Après avoir subi une « fuite accidentelle » deux jours à l’avance, Llama 3.1 a finalement été officiellement publié hier soir. Llama 3.1 étend la longueur du contexte à 128 Ko et est disponible en versions 8B, 70B et 405B, élevant une fois de plus à lui seul la barre de la compétition sur les pistes de grands modèles. Pour la communauté IA, l'importance la plus importante de Llama 3.1 405B est qu'il rafraîchit la limite supérieure des capacités du modèle de base open source. Les responsables de Meta ont déclaré que dans une série de tâches, ses performances sont comparables aux meilleures fermées. modèle source. Le tableau ci-dessous montre les performances des modèles actuels de la série Llama 3 sur des critères clés. On constate que les performances du modèle 405B sont très proches de celles du GPT-4o.
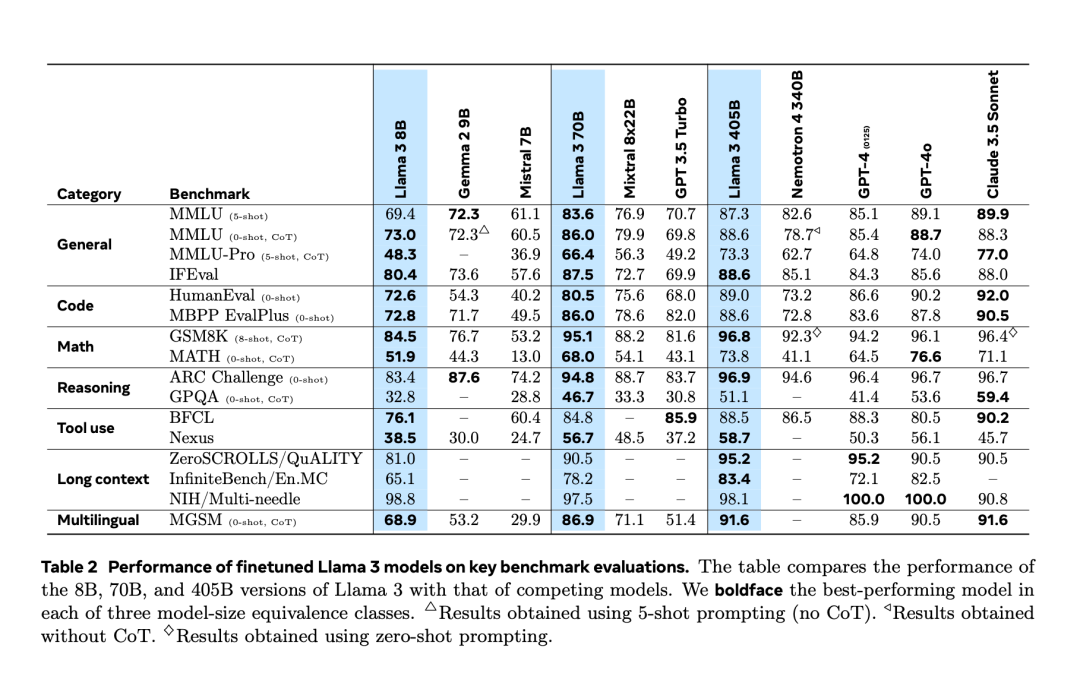
 Meta améliore le prétraitement du modèle Llama et les pipelines de conservation des données de pré-formation, ainsi que les méthodes d'assurance qualité et de filtrage des données de post-formation.
Meta améliore le prétraitement du modèle Llama et les pipelines de conservation des données de pré-formation, ainsi que les méthodes d'assurance qualité et de filtrage des données de post-formation.
Meta estime qu'il existe trois leviers clés pour le développement de modèles sous-jacents de haute qualité : la gestion des données, de l'échelle et de la complexité.
- Données :
- Meta a amélioré à la fois la quantité et la qualité des données pré-entraînement et post-entraînement par rapport aux versions précédentes de Llama. Llama 3 est pré-entraîné sur un corpus d'environ 15 000 milliards de jetons multilingues, tandis que Llama 2 n'utilise que 1 800 milliards de jetons.
- Échelle :
- Gestion de la complexité :
- Selon la loi de mise à l'échelle, le modèle phare de Meta a calculé approximativement la taille optimale, mais le temps d'entraînement des modèles plus petits a largement dépassé le temps optimal calculé. Les résultats montrent que ces modèles plus petits surpassent les modèles informatiques optimaux pour le même budget d'inférence. Dans la phase post-formation, Meta utilise le modèle phare 405B pour améliorer encore la qualité des modèles plus petits tels que le 70B et le 8B.
- Pour prendre en charge l'inférence de production à grande échelle de modèles 405B, Meta quantifie 16 bits (BF16) en 8 bits (FP8), réduisant ainsi les exigences de calcul et permettant au modèle de s'exécuter sur un seul nœud de serveur. La pré-formation de 405B sur 15,6T de jetons (3,8x10^25 FLOP) était un défi majeur, Meta a optimisé l'ensemble de la pile de formation et a utilisé plus de 16 000 GPU H100.
- Comme l'a dit Soumith Chintala, fondateur de PyTorch et ingénieur distingué Meta, le document Llama3 révèle de nombreux détails intéressants, dont la construction de l'infrastructure.
- 研究者らは、モデル開発プロセスの拡張性を最大化するために、設計においていくつかの選択を行いました。たとえば、標準の高密度 Transformer モデル アーキテクチャは、トレーニングの安定性を最大化するために専門家の混合ではなく、わずかな調整のみで選択されました。同様に、安定性が低い傾向にあるより複雑な強化学習アルゴリズムではなく、教師あり微調整 (SFT)、拒絶サンプリング (RS)、および直接優先最適化 (DPO) に基づいた、比較的単純なトレーニング後の手順が採用されています。そしてさらに難しい拡張。
- Llama 3 開発プロセスの一環として、メタ チームはモデルのマルチモーダル拡張機能も開発し、画像認識、ビデオ認識、音声理解の機能を提供しました。これらのモデルはまだ活発に開発中であり、まだリリースの準備ができていませんが、この論文では、これらのマルチモーダル モデルを使用した予備実験の結果を示しています。
- Meta はライセンスを更新し、開発者が Llama モデルの出力を使用して他のモデルを拡張できるようにしました。
- この論文の最後には、fenye1 という寄稿者の長いリストもありました。この一連の要因により、今日、最終的に Llama 3 シリーズが誕生しました。
- もちろん、一般の開発者にとって、405B スケールの Llama モデルを活用する方法は困難であり、多くのコンピューティング リソースと専門知識が必要です。
- 発売後、Llama 3.1 のエコシステムは準備が整い、Amazon Cloud Technologies、NVIDIA、Databricks、Groq、Dell、Azure、Google Cloud、Snowflake などを含む 25 を超えるパートナーが最新モデルで動作するサービスを提供しています。
技術的な詳細については、元の論文を参照してください。
以上がGPT-4o を打ち破るオープンソース モデルを作成するにはどうすればよいでしょうか? Llama 3.1 405B については、この論文にメタが書かれていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。