現在、次のトークン予測パラダイムを使用した自己回帰大規模言語モデルが世界中で普及しており、同時にインターネット上の多数の合成画像や動画がすでに拡散の力を示しています。モデル。
最近、MIT CSAIL の研究チーム (その 1 人は MIT の博士課程学生である Chen Boyuan です) は、全系列拡散モデルとネクスト トークン モデルの強力な機能を統合することに成功し、トレーニングとサンプリングを提案しました。パラダイム: 拡散強制(DF)。
論文のタイトル: Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
論文のアドレス: https://arxiv.org/pdf/2407.01392
プロジェクトのウェブサイト: https:/ /arxiv.org/pdf/2407.01392 /boyuan.space/diffusion-forcing
コードアドレス: https://github.com/buoyancy99/diffusion-forcing
以下に示すように、拡散強制は明らかにすべての点で優れています。一貫性と安定性の観点 2 つの方法は、シーケンス拡散と教師強制です。

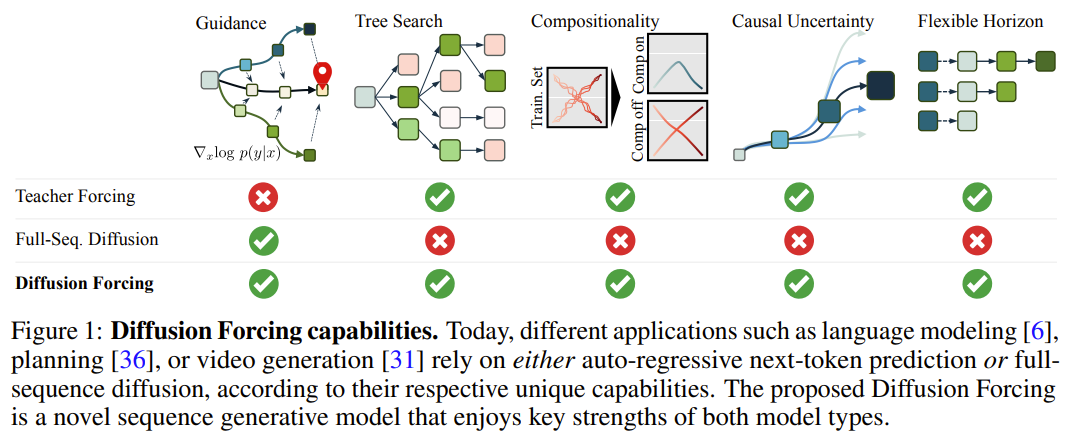
このフレームワークでは、各トークンはランダムな独立したノイズ レベルに関連付けられており、共有の次のトークン予測モデルまたは次のトークン予測モデルを、任意の独立したトークンごとのスキームに従って使用できます。トークンのノイズを除去します。 この手法の研究のインスピレーションは、次の観察から来ています。トークンにノイズを追加するプロセスは、部分的なマスキング プロセスの一種です。ゼロ ノイズはトークンがマスキングされていないことを意味し、完全なノイズは完全にマスキング トークンです。したがって、DF は、ノイズの多いトークンの変数セットを除去するマスクをモデルに強制的に学習させます (図 2)。 同時に、複数の次トークン予測モデルの組み合わせとして予測方法をパラメータ化することで、システムは異なる長さのシーケンスを柔軟に生成し、組み合わせ方式で新しい軌跡に一般化できます (図 1 )。 チームは、シーケンス生成に使用される DF を因果拡散強制 (CDF) に実装しました。CDF では、将来のトークンが因果アーキテクチャを通じて過去のトークンに依存します。彼らは、シーケンスのすべてのトークン (各トークンが独立したノイズ レベルを持つ) を一度にノイズ除去するようにモデルをトレーニングしました。 サンプリング中、CDF は一連のガウス ノイズ フレームを徐々にノイズ除去してクリーンなサンプルにします。この場合、異なるフレームは各ノイズ除去ステップで異なるノイズ レベルを持つ可能性があります。次のトークン予測モデルと同様に、CDF は可変長のシーケンスを生成できます。次のトークン予測とは異なり、CDF のパフォーマンスは、次のトークンを予測する場合でも、将来の数千のトークンを予測する場合でも、継続的なトークンを予測する場合でも非常に安定しています。 さらに、フルシーケンス拡散と同様に、指導を受けることもでき、高い報酬の生成が可能です。 CDF は、因果関係、柔軟なスコープ、可変ノイズ スケジューリングを連携して活用することにより、新機能であるモンテカルロ ツリー ガイダンス (MCTG) を有効にします。非因果的全系列拡散モデルと比較して、MCTG は高報酬生成のサンプリング レートを大幅に向上させることができます。図 1 は、これらの機能の概要を示しています。 1. ノイズ追加プロセスを部分マスクとして扱います まず第一に、任意のトークンセット (シーケンスであるかどうかに関係なく) を扱うことができます。またはそうでない) as t によってインデックス付けされた順序付きコレクション。次に、教師強制を使用して次のトークン予測をトレーニングすることは、時間 t での各トークン x_t をマスクし、過去の x_{1:t−1} に基づいてそれらを予測すると解釈できます。 シーケンスの場合、この操作はタイムラインに沿ってマスキングを実行するものとして説明できます。フルシーケンスの前方拡散 (つまり、データに徐々にノイズを追加するプロセス ) は、「ノイズ軸に沿ってマスキングを実行する」 と呼ぶことができる、一種の部分マスキングとして考えることができます。 K ステップでノイズを追加すると、 は (おそらく) ホワイト ノイズとなり、元のデータに関する情報はなくなりました。図 2 に示すように、チームはこれら 2 つの軸のエッジ マスクを確認するための統一された視点を確立しました。 2. 拡散強制: 異なるトークンには異なるノイズ レベルがあります 拡散強制 (DF) フレームワークは、任意のシーケンス長のノイズのあるトークンをトレーニングおよびサンプリングするために使用できます。各トークンのノイズ レベル k_t は時間ステップとともに変化します この論文は時系列データに焦点を当てているため、因果的アーキテクチャを通じて DF をインスタンス化し、簡単に言えば、これは です。基本的なリカレント ニューラル ネットワーク (RNN) を使用して得られる最小限の実装。重み θ を持つ RNN は、過去のトークンの影響を通知された隠れ状態 z_t を維持し、ループ層を通じて動的 に従って進化します。入力ノイズ観測値 が取得されると、隠れ状態がマルコフ方式で更新されます。 k_t=0 の場合、これはベイジアン フィルタリングの事後更新であり、k_t=K (純粋なノイズ、情報なし) の場合、これは「事後分布」p_θ(z_t | z_{ t−1})。 隠れ状態 z_t が与えられた場合、観測モデル p_θ(x_t^0 | z_t) の目的は、このユニットの入出力動作は標準の条件付き拡散モデルと同じです。条件変数 z_{t−1 } とノイズのあるトークンを入力として、ノイズのない x_t=x_t^0 を予測し、それによってアフィン再パラメータ化を通じて間接的にノイズ ε^{k_t} を予測します。したがって、古典的な拡散ターゲットを直接使用して、(因果的)拡散強制を訓練することができます。ノイズ予測結果 ε_θ に従って、上記のユニットをパラメータ化することができます。次に、次の損失を最小限に抑えることでパラメータ θ が求められます。 アルゴリズム 1 は擬似コードを与えます。重要なのは、この損失がベイジアン フィルタリングと条件付き拡散の重要な要素を捉えているということです。研究チームはまた、元の論文の付録で詳しく説明されているように、拡散強制のための拡散モデルのトレーニングで使用される一般的な手法をさらに再推論しました。彼らはまた、非公式の定理にも到達しました。 定理 3.1 (非公式)。拡散強制トレーニング手順 (アルゴリズム 1) は、期待される対数尤度 の証拠下限 (ELBO) を最適化する再重み付けです。ここで、期待値はノイズ レベル全体にわたって平均され、 は順方向プロセスに従ってノイズが多くなります。さらに、適切な条件下では、(3.1) を最適化すると、すべてのノイズ レベル シーケンスの下限を同時に最大化することもできます。 アルゴリズム 2 は、次のように定義されるサンプリング プロセスを記述します。 2 次元 M × T グリッド K ∈ [K]^{M×T } はノイズ スケジュールを指定します。列はタイム ステップ t に対応し、m でインデックス付けされた行がノイズ レベルを決定します。 長さ T のシーケンス全体を生成するには、最初にトークン x_{1:T} をノイズ レベル k = K に対応するホワイト ノイズに初期化します。次に、ノイズ レベルが K に達するまで、グリッドに沿って行ごとに反復処理を行い、左から右に列ごとにノイズを除去します。最後の行の m = 0 までに、トークンのノイズはクリーンアップされます。つまり、ノイズ レベルは K_{0,t} ≡ 0 になります。 このサンプリング パラダイムは、次の新しい機能をもたらします:
拡散強制の新しい機能は、新たな可能性ももたらします。これに基づいて、チームはシーケンス意思決定 (SDM) のための新しいフレームワークを設計し、それをロボットや自律エージェントの分野に適用することに成功しました。 まず、動的 p (s_{t+1}|s_t, a_t)、観測値 p (o_t|s_t)、報酬 p (r_t|s_t, a_t) を使用してマルコフ決定プロセスを定義します。ここでの目標は、軌道 の期待累積報酬を最大化するようにポリシー π(a_t|o_{1:t}) をトレーニングすることです。ここではトークン x_t = [a_t, r_t, o_{t+1}] が割り当てられます。軌跡はシーケンス x_{1:T} であり、その長さは可変であり、トレーニング方法はアルゴリズム 1 に示すとおりです。 実行プロセスの各ステップ t には、過去のノイズフリー トークン x_{1:t-1} を要約する隠れ状態 z_{t-1} があります。この隠れた状態に基づいて、アルゴリズム 2 に従って計画 がサンプリングされます。ここで には、予測されたアクション、報酬、および観察が含まれます。 H は前方観測ウィンドウであり、モデル予測制御における将来予測に似ています。計画されたアクションを実行した後、環境は報酬と次の観察、つまり次のトークンを受け取ります。隠れ状態は事後 p_θ(z_t|z_{t−1}, x_t, 0) に従って更新できます。 このフレームワークは戦略とプランナーの両方として使用でき、その利点は次のとおりです:
- を達成できる将来の不確実性を達成するためのカルロ ツリー ガイダンス (MCTG)
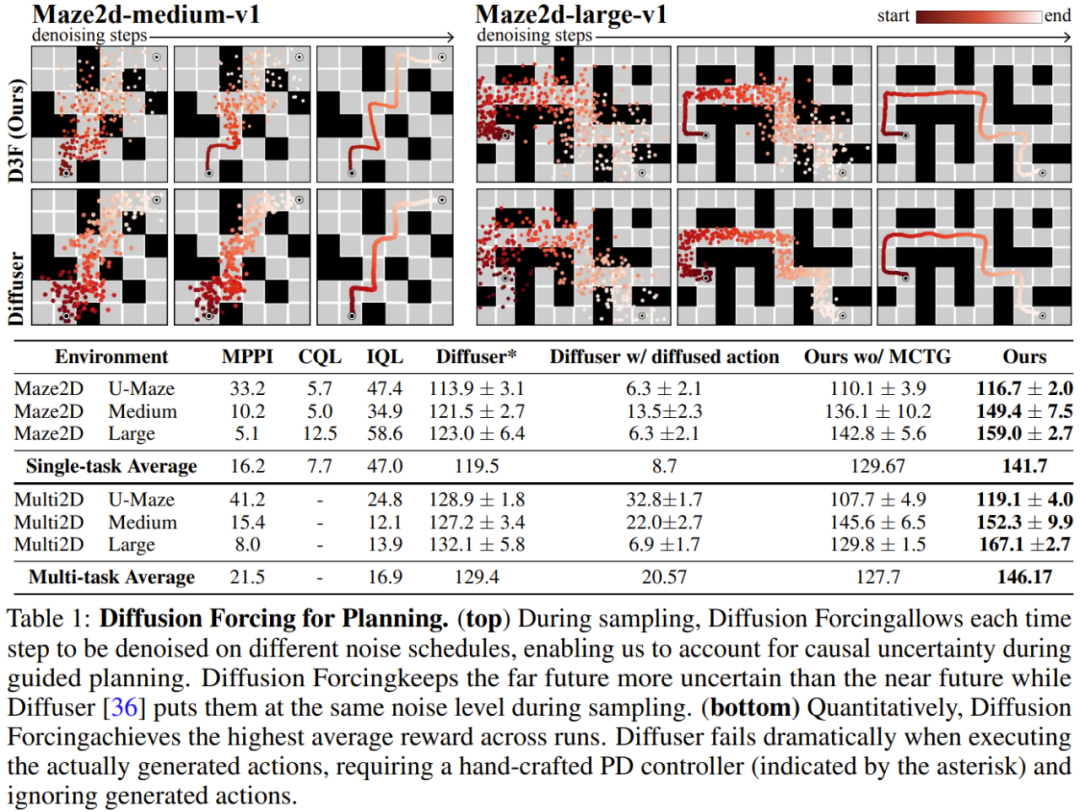
チームは、ビデオと時系列の予測、計画と模倣学習を含む生成シーケンス モデルとしての拡散強制の利点を評価しました。他のアプリケーション。 ビデオ予測: 一貫性のある安定したシーケンス生成と無限の拡張ビデオ生成モデリング タスクでは、Minecraft ゲーム ビデオと DMLab ナビゲーションの成果に基づいて、因果拡散強制のための畳み込み RNN をトレーニングしました。 図 3 は、拡散強制とベースラインの定性的な結果を示しています。 教師による強制とフルシーケンスの拡散ベンチマークはすぐに発散する一方で、拡散強制はトレーニング範囲を超えても安定して展開できることがわかります。 拡散計画: MCTG、因果不確実性、柔軟な範囲制御強制を拡散する機能は、意思決定に独自の利点をもたらすことができます。チームは、標準のオフライン強化学習フレームワークである D4RL を使用して、新しく提案された意思決定フレームワークを評価しました。 表 1 に定性的および定量的な評価結果を示します。ご覧のとおり、Diffusion Enforcement は 6 つの環境すべてで Diffuser およびすべてのベースラインを上回っています。 チームは、サンプリングスキームを変更するだけで、トレーニング時に観察されたシーケンスのサブシーケンスを柔軟に組み合わせることができることを発見しました。 彼らは 2D 軌跡データセットを使用して実験を実施しました。正方形の平面上で、すべての軌跡は 1 つの角から始まり、反対側の角で終わり、一種の十字形を形成します。 上の図 1 に示すように、組み合わせ動作が必要ない場合、DF は完全なメモリを維持し、クロスの分布を複製することができます。組み合わせが必要な場合、モデルを使用して MPC を使用してメモリレスで短い計画を生成し、それによってこの十字のサブ軌道をステッチして V 字型の軌道を取得できます。 拡散強制は、実際のロボットの視覚的動作制御に新たな機会ももたらします。 模倣学習は、専門家によって実証された観察された動作のマッピングを学習する、一般的に使用されるロボット制御手法です。ただし、記憶力が不足していると、長距離タスクの模倣学習が困難になることがよくあります。 DF はこの欠点を軽減するだけでなく、模倣学習をより堅牢にすることもできます。 記憶を模倣学習に使用します。 Franka ロボットを遠隔制御することで、チームはビデオとモーション データ セットを収集しました。図 4 に示すように、タスクは 3 番目の位置を使用してリンゴとオレンジの位置を交換することです。フルーツの初期位置はランダムであるため、可能な目標状態は 2 つあります。 さらに、3 番目の位置にフルーツがある場合、現在の観察から望ましい結果を推測することはできません。どのフルーツを移動するかを決定するために、戦略は初期構成を覚えていなければなりません。一般的に使用される動作クローン作成手法とは異なり、DF は記憶を独自の隠れた状態に自然に統合できます。 DF は 80% の成功率を達成したが、拡散戦略 (現時点で最良の記憶を持たない模倣学習アルゴリズム) は失敗したことが判明した。 さらに、DF はノイズにもより堅牢に対処し、ロボットの事前トレーニングを容易にすることもできます。 時系列予測: 拡散強制は優れた一般シーケンスモデルです多変量時系列予測タスクについては、チームの研究により、DFが以前の拡散モデルやTransformerベースのモデルと競合するのに十分であることが示されています匹敵します。 技術的な詳細と実験結果については、元の論文を参照してください。 以上が無制限のビデオ生成、計画と意思決定、次のトークン予測とフルシーケンス拡散の拡散強制統合の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




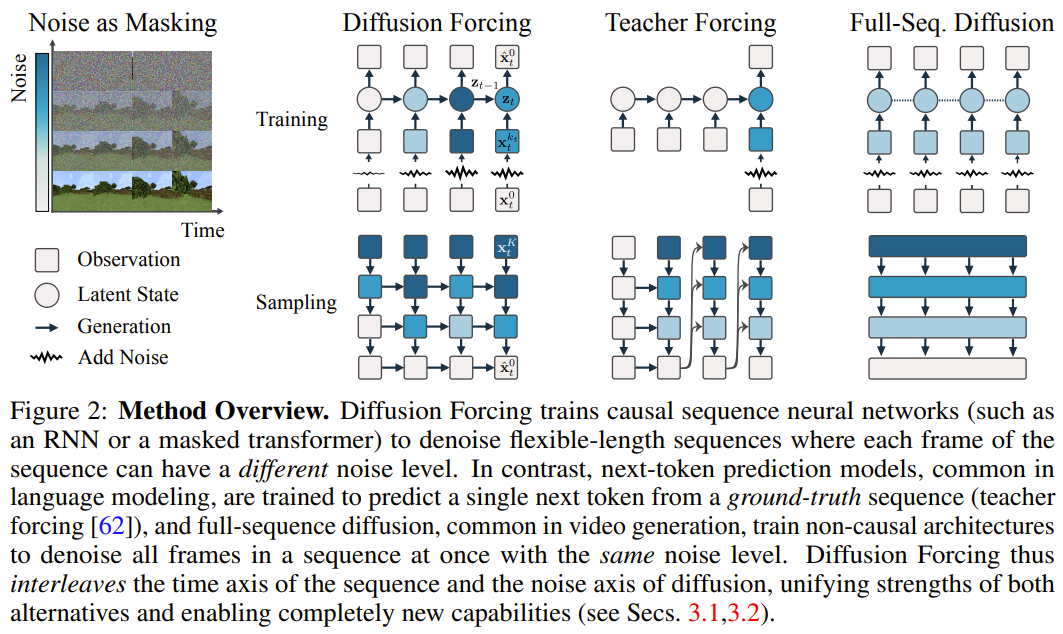
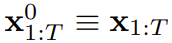 ) は、「ノイズ軸に沿ってマスキングを実行する」
) は、「ノイズ軸に沿ってマスキングを実行する」  は (おそらく) ホワイト ノイズとなり、元のデータに関する情報はなくなりました。図 2 に示すように、チームはこれら 2 つの軸のエッジ マスクを確認するための統一された視点を確立しました。
は (おそらく) ホワイト ノイズとなり、元のデータに関する情報はなくなりました。図 2 に示すように、チームはこれら 2 つの軸のエッジ マスクを確認するための統一された視点を確立しました。 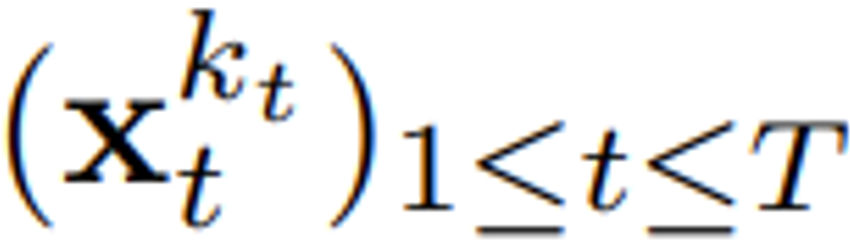 に従って進化します。入力ノイズ観測値
に従って進化します。入力ノイズ観測値 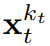 が取得されると、隠れ状態がマルコフ方式で更新されます。
が取得されると、隠れ状態がマルコフ方式で更新されます。 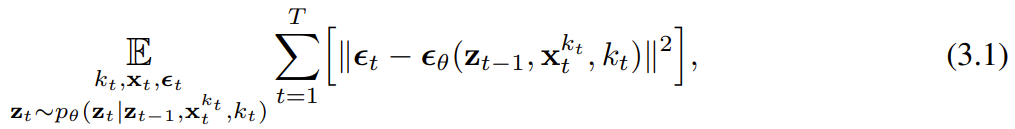

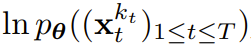 の証拠下限 (ELBO) を最適化する再重み付けです。ここで、期待値はノイズ レベル全体にわたって平均され、
の証拠下限 (ELBO) を最適化する再重み付けです。ここで、期待値はノイズ レベル全体にわたって平均され、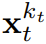 は順方向プロセスに従ってノイズが多くなります。さらに、適切な条件下では、(3.1) を最適化すると、すべてのノイズ レベル シーケンスの下限を同時に最大化することもできます。
は順方向プロセスに従ってノイズが多くなります。さらに、適切な条件下では、(3.1) を最適化すると、すべてのノイズ レベル シーケンスの下限を同時に最大化することもできます。 
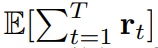 の期待累積報酬を最大化するようにポリシー π(a_t|o_{1:t}) をトレーニングすることです。ここではトークン x_t = [a_t, r_t, o_{t+1}] が割り当てられます。軌跡はシーケンス x_{1:T} であり、その長さは可変であり、トレーニング方法はアルゴリズム 1 に示すとおりです。
の期待累積報酬を最大化するようにポリシー π(a_t|o_{1:t}) をトレーニングすることです。ここではトークン x_t = [a_t, r_t, o_{t+1}] が割り当てられます。軌跡はシーケンス x_{1:T} であり、その長さは可変であり、トレーニング方法はアルゴリズム 1 に示すとおりです。 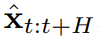 がサンプリングされます。ここで
がサンプリングされます。ここで 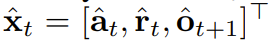 には、予測されたアクション、報酬、および観察が含まれます。 H は前方観測ウィンドウであり、モデル予測制御における将来予測に似ています。計画されたアクションを実行した後、環境は報酬と次の観察、つまり次のトークンを受け取ります。隠れ状態は事後 p_θ(z_t|z_{t−1}, x_t, 0) に従って更新できます。
には、予測されたアクション、報酬、および観察が含まれます。 H は前方観測ウィンドウであり、モデル予測制御における将来予測に似ています。計画されたアクションを実行した後、環境は報酬と次の観察、つまり次のトークンを受け取ります。隠れ状態は事後 p_θ(z_t|z_{t−1}, x_t, 0) に従って更新できます。